@AlexGDimakis@yevgets Anyways, even if the result is "obvious" common wisdom many years old, there's still upsides to have a paper that formally writes it up and tries to analyze it where others haven't really done so.
@AlexGDimakis@yevgets Without ruling out the confounders here, the paper's hypothesis that non-transcendence of their 1500 model is due to lack of "diversity" rather than one of these other effects seems oddly particular and a bit premature.
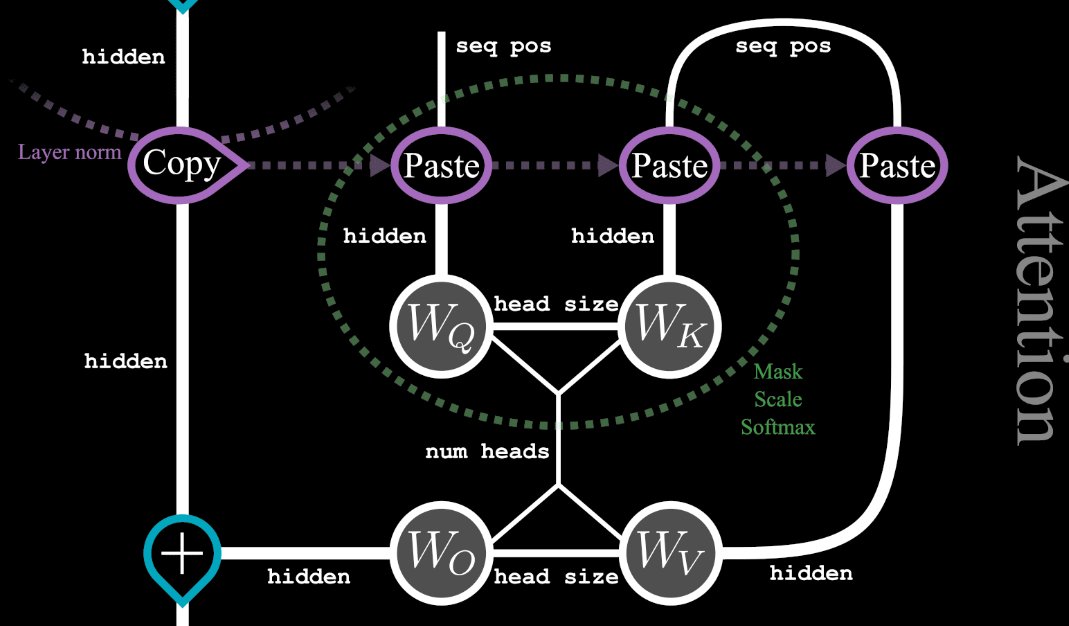
I always found the tensor notation in Fast Matrix Multiplication algorithms confusing. But using tensor diagrams it's pretty easy to see what's going on:
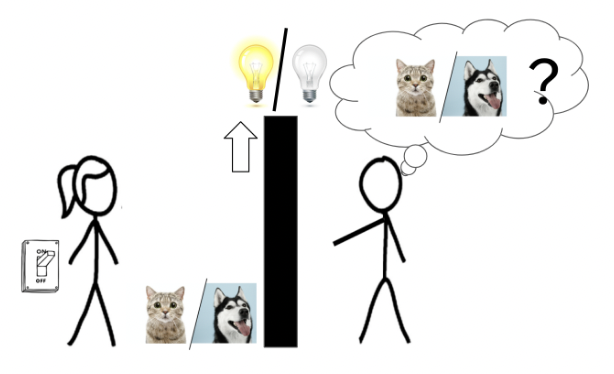
Even though we've known from word2vec and much work since that LLM representations correlate well with human concepts (both in linear additivity, distance/clustering, etc), I still find it cool that it holds up with larger models so far. Lots of space to explore further.
New Anthropic research paper: Scaling Monosemanticity.
The first ever detailed look inside a leading large language model.
Read the blog post here: https://t.co/6RYwxt6nWI
@littmath If you always...
...show as many heads as you can, then prob=0.
...show exactly 9 heads if there are at least 9 heads, then prob=1/11.
...show a random 9 coins and it just happens they're all heads, then prob=1/2.
...show 9 heads only in the case there are 10 heads, then prob=1.
SOTA AI for games like poker & Hanabi rely on search methods that don’t scale to games w/ large amounts of hidden information.
In our ICLR paper, we introduce simple search methods that scale to large games & get SOTA for Hanabi w/ 100x less compute. 1/N
https://t.co/oxopUMkTK2
There are tons of articles on MCTS, which wastes compute whenever paths lead to the same state, but few on Monte-Carlo *Graph* Search, which doesn't. But implementing MCGS soundly can be tricky! Here's a doc on how to do it, and the theory behind it: https://t.co/J1TiH9Y2QC
In the recent paper https://t.co/tZD0NK49fh @GoogleDeepMind introduced a transformer chess network, but didn't include Lc0 in their comparison. We've used transformers for a while, and our network is stronger with fewer parameters. More details soon.
There are two shapes below: one is named “kiki” and one is named “bouba”.
Which is which?
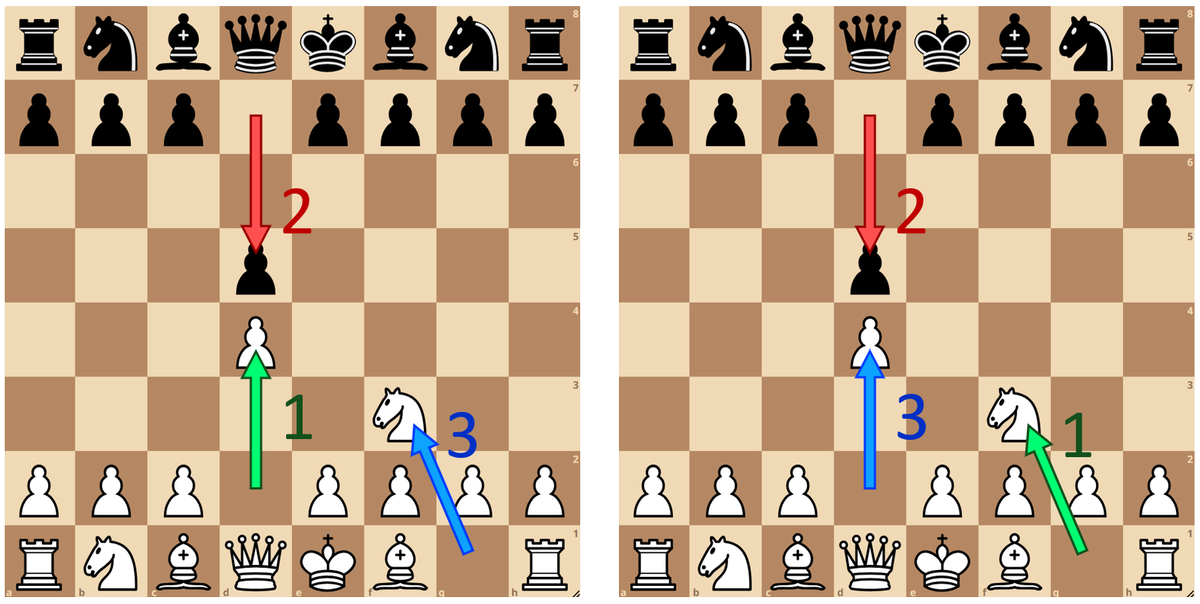
This is the puzzle we consider in our ICML paper: Learning Intuitive Policies Using Action Features. 1/N
https://t.co/07nVGynBb4
⚫ ✴
What is off-belief learning and how does it help us build agents that coordinate only in grounded ways ? Part 1 of a new blog series on intuitive summaries of key ideas in multi-agent RL: https://t.co/H7g1PIHn4D
Here's my conversation with Noam Brown (@polynoamial), co-creator of AI systems that achieve superhuman level performance in games of poker and Diplomacy that involves strategic negotiations with humans. This was a fascinating, technical conversation. https://t.co/e6BArJjnag