This is exactly the right question. Objects, not pixels. Structure, not hallucination.
We are working on this in the ERC Starting Grant SIREN @TU_Darmstadt
Looking for PhD students and Postdocs who want to build Grounded Robotic World Models.
Job posting: https://t.co/kytT67e4Yh
#RobotLearning #WorldModels #PhD #Postdoc
🚀 Hiring PhDs & Postdocs in Structured Robot Learning & Embodied AI @TUDarmstadt (PEARL Lab)
🤖 We study how structure in the robot–environment system can be exploited to learn robust, adaptive, and generalizable behaviors, beyond black-box policies
🔬 Topics:
• Grounding (language → perception → action)
• Structured world models
• VLA + control + memory
• RL (credit assignment, offline→online)
• Whole-body & bimanual mobile manipulation
🇪🇺 New EU Lighthouse Project on Generative AI for Robotics + ERC StG SIREN
👉 Full call: https://t.co/VxcornBuo9
Please repost 🙏
#RobotLearning #EmbodiedAI #Robotics #MachineLearning #PhDPositions #Postdoc
I am pleased to announce our new paper, which provides an extremely sample-efficient way to create an agent that can perform well in multi-agent, partially-observed, symbolic environments.
The key idea is to use LLM-powered code synthesis to learn a code world model (in the form of Python code) from a small dataset of (observation, action) trajectories, plus some background information (in text form), and then to pass this induced WM, plus the observation history, to an existing solver, such as (information-set) MCTS, to choose the next action.
@ellisk_kellis@BluemlJ@kerstingAIML Thank you ! You guys did amazing work ! So inspiring, and quite connected to many of our current projects ! Don't hesitate to give us feedback if you find bugs !
Making actually explainable RL agents: an experience on Atari games
🧵📖 Read of the day, season 3, day 2: Interpretable Concept Bottlenecks to Align Reinforcement Learning Agents, by @liimeleemon, Sztwiertnia et al from TU Darmstadt’s computer science department
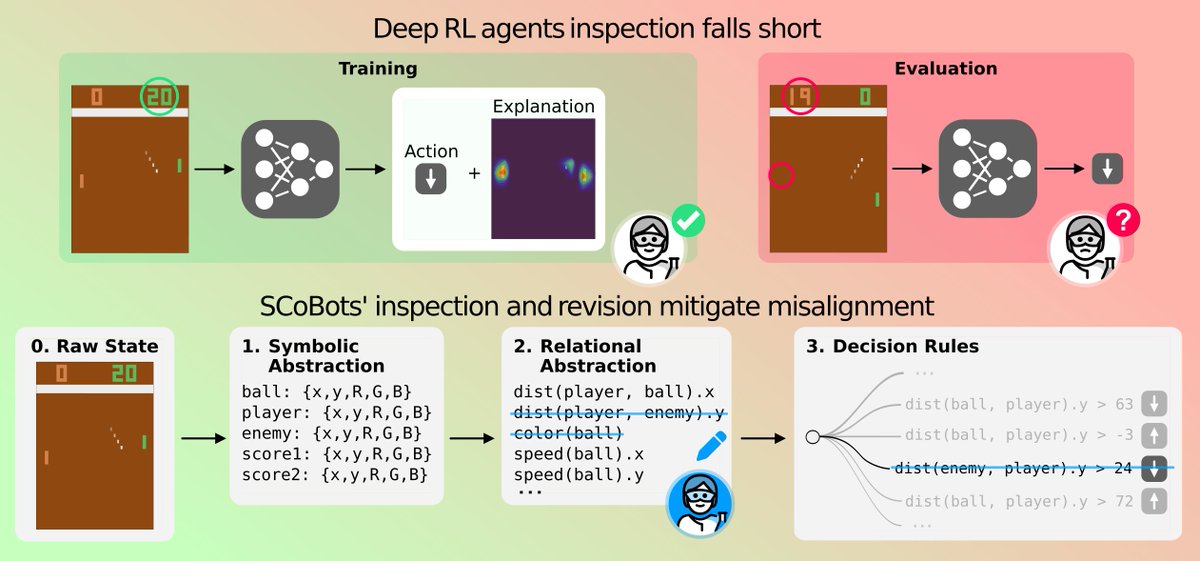
The premise made by the authors is basically that current interpretability methods regarding the behavior of RL agents are flawed
Main reason why they point this out is because Shortcut Learning has been seen to be a thing, at least for Atari Games. For instance, in Pong, because the AI follows the ball’s trajectory… an RL model can actually choose to focus on the AI’s paddle rather than the ball to answer its action of going up or down.
This misalignment of the AI’s decision process is a problem, even more so because its interpretability is not easy. Hence the work of the authors in this paper 👇
So happy that our paper Interpretable Concept Bottlenecks to Align Reinforcement Learning Agents (https://t.co/penuXuyiRR) has been accepted at NeurIPS 2024! 🎉
If you are wondering why RL agents cannot generalize to new scenarios and how to mitigate it, check it out !
Please have a look at the accepted papers at the Interpretable RL @InterppolRL workshop. Stay tuned if you attend @RL_Conference for the workshop program happening on August 9.
https://t.co/Ax7tU2jtW7
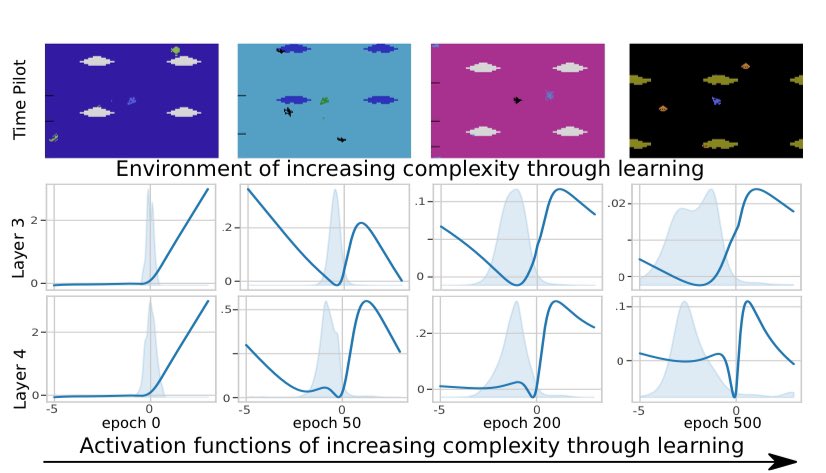
If you're @iclr_conf#ICLR2024 then don't miss out on Quentin's spotlight✨for our work "Adaptive Rational Activations to Boost Deep RL" - Fri May 10th at 10:30-12:30 in Hall B poster 148!
Come & learn how to easily equip your NN with more plasticity with plug&play activations!
Deadline reminder for the InterpPol workshop
@RL_Conference. Submit published or original work before April 26 AoE. Topics of interest:
- Interpretable/Explainable RL
- Policy Distillation
- Formal Verification and RL
- Real word and applications of RL
https://t.co/TIbyXkOyVN
The workshop on Interpretable Policies in Reinforcement Learning (InterpPol) has been accepted
@RL_Conference: "Good diversity. Good list of organizers. Good line up of speakers. Good topic."! Stay tuned for the upcoming twitter account, website, and call for papers.
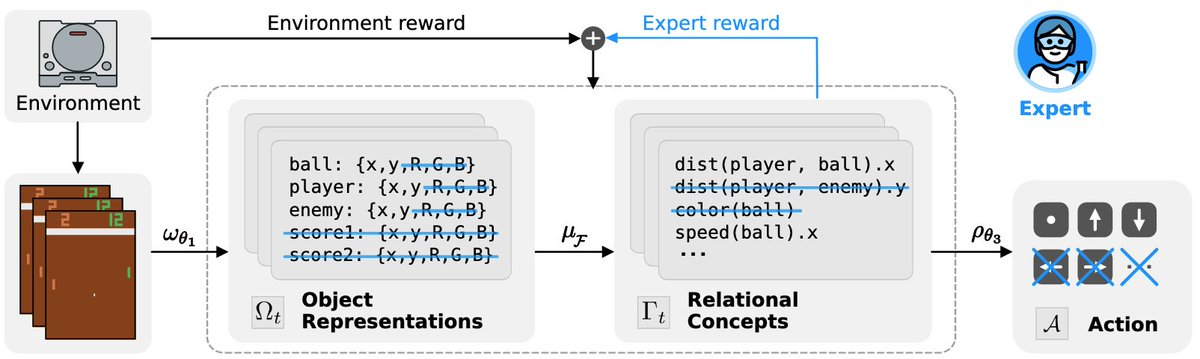
Happy to share our exciting work on bringing the benefits of concept representations to the realm of reinforcement learning via our SCoBot agents: https://t.co/d2LY2t3xTN
@liimeleemon, Sebastian Sztwiertnia, @real_maggi, @kerstingAIML
Super happy that our work “Adaptive Rational Activations to Boost Deep Reinforcement Learning” got accepted as a spotlight to #ICLR2024
-> Use rationals as parameter efficient plug&play activations to promote neural plasticity!
Congrats @liimeleemon!
https://t.co/5KELEX7uk0