We are excited to announce the first Statistics and Trustworthy AI for Cross (X)-Domain Acceleration conference (STAI-X)! This event aims to bring statistics and AI closes, in order to enable cross-domain acceleration. It is organized by the @StatsUpAI interest group of the ASA (@AmstatNews) in partnership with the Committee on Applied and Theoretical Statistics of the NAS, COPSS (@COPSSNews), IMS (@InstMathStat), SSC (@SSC_stat), ENAR (@ENAR_ibs), WNAR (@WNAR_ibs), and ICSA (@ICSA_Statistics).
The event will take place July 31st to August 1st, at Harvard University, Cambridge, MA, right before the Joint Statistics Meetings (held in Boston this year).
We would like to invite paper and poster submissions on all topics at the interface of AI and statistics, as well as domain applications. Areas of interest include (but are not limited to) Foundations and Methods at the Interface of Statistics and AI, AI Agents and Benchmarks for Data-Driven Discovery, as well as AI x Statistics x Science and Society. Submissions will be handled on OpenReview (https://t.co/it1c7wV9ow). Papers will be published in STAI-X proceedings and will be eligible for our awards.
In partnership with several statistical and domain science journals (Journal of the American Statistical Association, Annals of Applied Statistics, Harvard Data Science Review, ASA Discoveries, Canadian Journal of Statistics, Genetics, and Genome Research), our top-rated conference papers will be eligible to be invited for submission to these journals.
To find out more, please see the attached flyer, visit the STAI-X website (https://t.co/8WoUTSIVS8), and register for our information session this Friday afternoon!
Did you know that Grok is MUCH MORE HONEST than GPT & Claude?
Introducing PieArena: Frontier Language Agents Achieve MBA-Level Negotiation Performance and Reveal Novel Behavioral Differences.
Deepdive: https://t.co/jw6I01VML7
Preprint: https://t.co/aUuQQNSDYE
#AI#Agent#LLM
We recently organized #Agents4Science, the 1st conference where LLMs are both authors and reviewers🤖
It was an open experiment to assess how well AI can lead research and review papers.
Today we report what we learned in @NatureBiotech Highlights in 🧵
❗️Self-evolution is quietly pushing LLM agents off the rails.
⚠️ Even perfect alignment at deployment can gradually forget human alignment and shift toward self-serving strategies. Over time, LLM agents stop following values, imitate bad strategies, and even spread misaligned behaviors to others!
🧠 Alignment isn’t static — it’s fragile, dynamic, and decays through experience. Let’s rethink alignment as something to maintain, not just achieve!
👇Details from @lillianwei423's thread
@mohitban47, @cihangxie, @linjunz_stat, @dingmyu
🚨 Introducing ATP — Alignment Tipping Process!
🔥 Beware! Self-Evolution is gradually pushing LLM Agents off the rails! Even perfect alignment at deployment can gradually forget human alignment and shift toward self-serving strategies.
#AI#LLM#Agents#SelfEvolving#Alignment #AIResearch
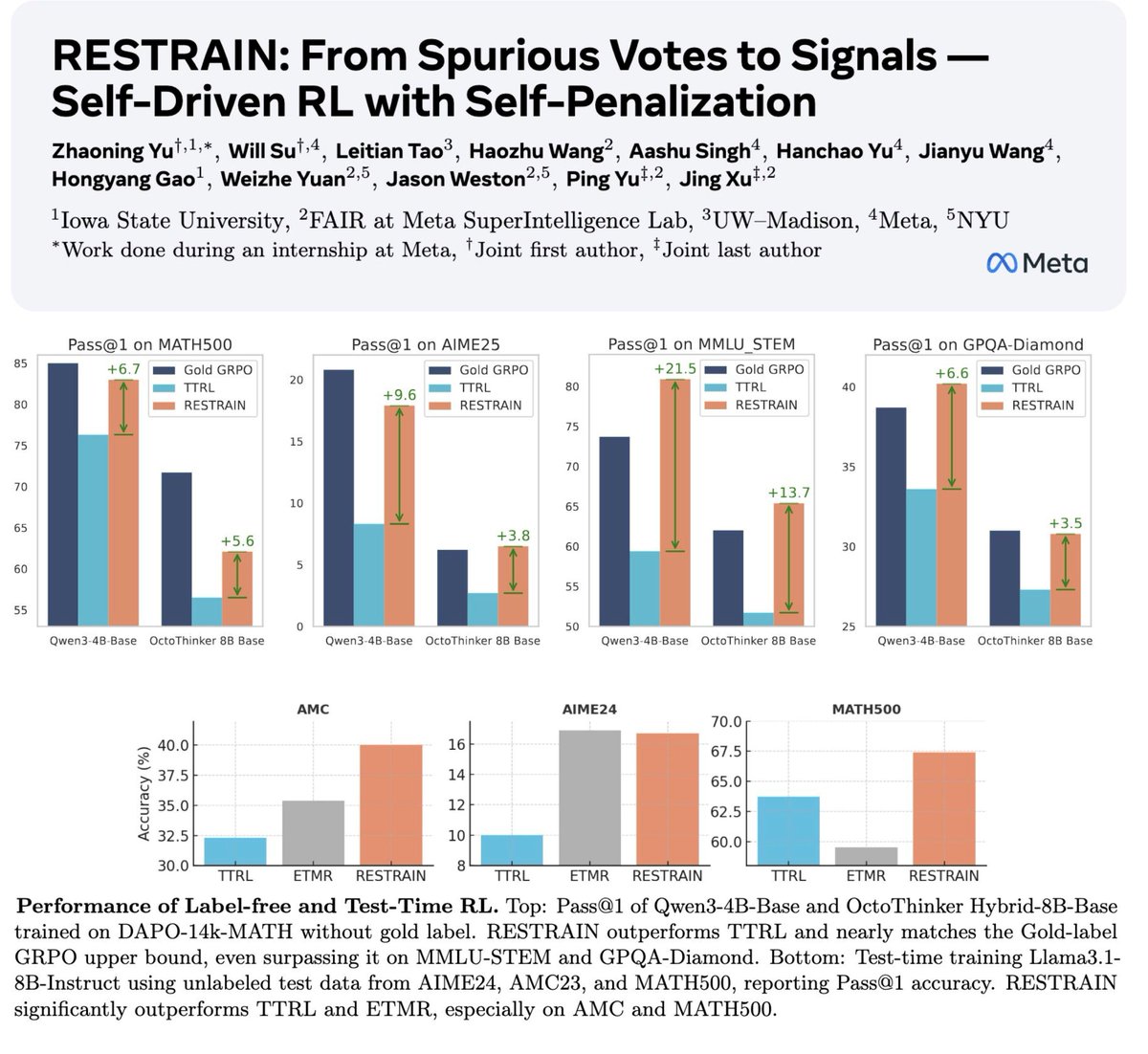
🌀New Self-Driven RL Method: RESTRAIN 🌀
📝: https://t.co/VceEJ248fW
- RESTRAIN turns spurious votes → self-Improving signals. No labels needed
- Does this through self-penalizing unreliable reasoning paths:
✔️ Uses all rollouts, not just the majority,
✔️ Offsets low-consistency rollout advantage,
✔️ Down-weights low-consensus prompts
📈 Results:
🔥 Beats existing techniques on both training-time (label-free) and test-time scaling — all without labels.
🔥 Nearly matches (and sometimes surpasses) gold-label RL
🧵(1/5)
🚀 One month left to submit to Agents4Science! 🤖
AI as primary author + reviewer 🤖 Human co-authors welcome. All submissions/reviews public for transparent study.
💡We expect AI will make mistakes - and it will be instructive to study these openly!
📢New conference where AI is the primary author and reviewer! https://t.co/lLjAgp7Zmp
Current venues don't allow AI-written papers, so it's hard to assess the +/- of such works🤔 #Agents4Science solicits papers where AI is the main author w/ human advisors.
💡Initial reviews by LLM reviewers w/ final assessment + selection by human experts.
💡Submissions are asked to clearly document AI contribution.
💡All submissions/reviews will be public to enable transparent study of the strength and limitations of AI as researcher and reviewer.
We expect AI will make mistakes and it will be instructive to study these in the open!
Many thanks to the fantastic co-organizers and expert advisory board! Please see the website for more information.
Our new #ICML2025 paper formulates #LLM hallucination as hypothesis testing to provide statistical guarantees on factuality.
#FactTest is a distribution free and model agnostic approach to improve LLM accuracy.
Great job @FanNie1208 Xiaotian Hou, Shuhang Lin @HuaxiuYaoML@linjunz_stat!
🚨 New Paper 🚨
An Overview of Large Language Models for Statisticians
📝: https://t.co/oklTYEAMvH
- Dual perspectives on Statistics ➕ LLMs: Stat for LLM & LLM for Stat
- Stat for LLM: How statistical methods can improve LLM uncertainty quantification, interpretability, trustworthiness & more.
- LLM for Stat: How LLMs can enhance statistical workflows: from data collection, synthesis, annotation to statistical modeling, with applications to medical research
Presents key LLM advances: Architecture, Training, Reasoning, and Self-Alignment:
(1) 🧠Evolution of LLM architectures with Transformers and Self-Attention
(2) LLM training pipeline from pre-training, SFT, to RLHF and Preference Optimization.
(3) 💭 System 2 Prompting and Chain-of-Thought for test-time scaling .
(4) 🚀 LLM Self-Alignment for achieving super-human intelligence
Statisticians play a key role in the development of large-scale AI models:
(1) 💡 Statistical insights improve LLM uncertainty quantification & interpretability
(2) 🤖 Watermarking for AI-generated content detection
(3) ⚖️ Privacy & algorithmic fairness to ensure responsible AI adoption
LLMs can also empower statistical science by:
(1) 📈 Scaling up data collection, synthesis, and annotation.
(2) 🖥️ Automating statistical coding & exploratory analysis
(3) 🔬 Facilitating medical research
By bridging statistics & AI, we can:
✅ Improve better LLMs with statistical methodologies.
✅ Leverage LLMs for statistical applications in high-stakes domains
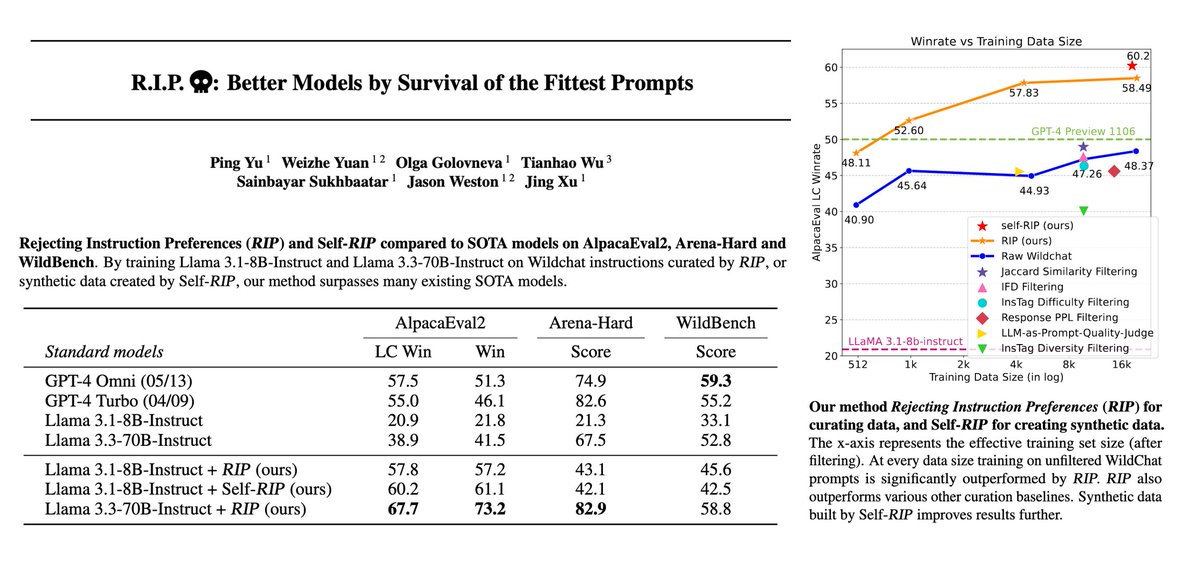
💀 Introducing RIP: Rejecting Instruction Preferences💀
A method to *curate* high quality data, or *create* high quality synthetic data.
Large performance gains across benchmarks (AlpacaEval2, Arena-Hard, WildBench).
Paper 📄: https://t.co/9EKFpTsd9e
Our department is looking for a part-time lecturer for a master course on “Database Systems for Data Science” for the Spring 2025 semester.
Got interested or know someone who does? Shoot me an email at [email protected]. Feel free to share this around! #Hiring#DataScience
Details:
•Teach once a week (in New Brunswick), 3 hours, for about 14 weeks
•All teaching materials from past semesters are provided
•We offer a competitive salary!
Very excited to give a short course on large language models at #JSM2024 in Portland! w/ Emily Getzen and @linjunz_stat AI for Stat and Stat for AI! @AmstatNews
📢Excited to share our approach called Calibrated Self-Rewarding Vision Language Models (CSR)🌟! With no need for labeled data, a VLM can get stronger by itself with visual constraints. Discover how CSR enhances VLMs through self-improvement with visual constraints:
https://t.co/sp60C13QlG
Led by @AiYiyangZ.
Key Idea:
👉1. Each iteration sees the target VLM generating preference data and performing preference optimization.
👉2. Self-generated preferences are guided by reward scores, which are generated by the target VLM itself and calibrated based on image-response relevance.