I built a 3D character you can control with language instead of predefined buttons.
How? I compiled a neural program that turns language instructions into movements, using ProgramAsWeights.
Just type: "act excited, wave, dance, then sit proudly"
Try it: https://t.co/wnQcwbDJ3M
Search is no longer just a ranked list...LLM agents can now query, inspect, reformulate, and decide when to stop 🤖
At TREC RAG 2026, we’re introducing new metrics for agentic search: evaluating not only final results, but the search process itself 📊
Stay tuned!
🤨 Is your agent confused about what to build because it says there aren’t any guidelines?
Now your agent has no more excuses - track guidelines for TREC RAG 2026 are out 🔥
And yes, they’re available via SKILLz 😎
Tell your agents to showcase your agentic search system!
Does retrieval help RAG or did the LLM already memorize the answer? 🤔 Too often, the overlap between RAG corpora and what LLMs “know” is unclear
Better RAG evaluation needs tighter alignment between NLP and IR
📚 That's why for RAG 2026 we are using @nvidia's ClimbMix corpus
But I think we can do better... what about zero parameters? Let me introduce you to something else that's awesome: It's called grep. https://t.co/mjNYuZl2dC
Since we're counting model parameters, let me introduce you to a two-parameter model for agentic search that's awesome: It's called BM25. I haven't tried it yet, but I think fp4 will work fine. https://t.co/KvMqGKCRJF
Thus, our conclusions: This I believe is the first demonstration of the need for hybrid search. Hence the claim that hybrid search is a @UWaterloo innovation. You're welcome!
The broader lesson is that old baselines are still surprisingly important. Let's not forget them.
I think @xueguang_ma is being too modest, so I'll provide context: he along with @rpradeep42 and a UWaterloo ugrad (Kai Sun) popularized hybrid search in its current form.
So, if you're using hybrid search today, thank them. 🙏
Yes, this is clickbait-y, so I'll support my claims 🧵
This plot reminds me of my first IR work reproducing DPR in Pyserini, where we found BM25 is amazingly helpful when hybrid with a dense retriever. BM25 is never just a simple baseline -- used the right way, it can easily outperform many fancy methods.
BM25 was the most robust method shown in BEIR, the most effective and efficient method for long-context search shown in LongEmbed, and now @mattjustram and @xuzihuan4 show that BM25 can push the search agents into the best efficiency frontier.
p.s. Pyserini and pi-serini are two different repos.
someone already wrote a love letter to pi, by @badlogicgames.
so we wrote a love paper to pi :)
with my teammates @xuzihuan4 and @lintool.
a few days ago, i promised i’d share some fun plots once Pi-Serini joined the BrowseComp-Plus deep research agent party.
now, it’s about time.
here weeeee goooooo.
bear with the sloppy images first.
the serious one is at the end.
the question was simple:
how far can we push deep research with BM25 + pi?
turns out: weirdly far.
TREC RAG is returning for 2026! 🎉
This year’s iteration is special because agents 🤖 can join the fun… but what might agent-first community evaluation look like? 🧵👇
Does a lexical retriever suffice for agentic search when agents can keep refining their queries?
As LLMs become more capable in agentic loops, agents can continuously refine their actions based on environmental feedback. We couldn’t help but ask the question above.
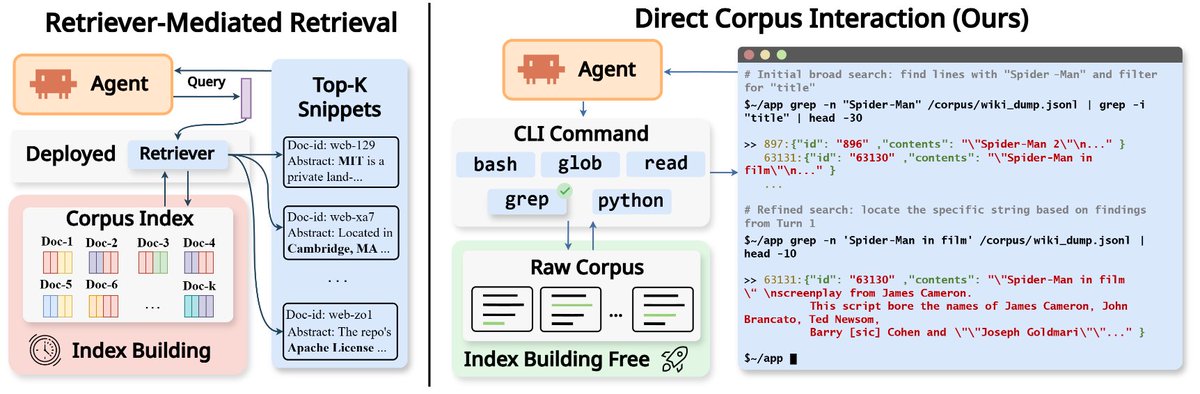
🔥 Introducing Direct Corpus Interaction (DCI)! The best retriever for agentic search is no retriever.
🚀 We replaced the entire agentic search pipeline — embedding model, vector index, top-k retrieval — with only `grep` and `bash`. 🔧
📄 Paper: https://t.co/9FVvrdLCRf
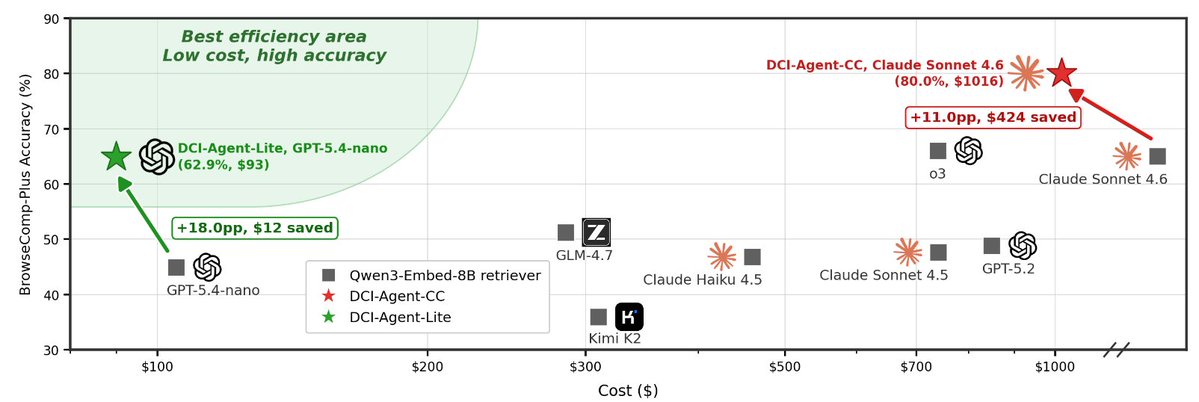
DCI unlocks the full agentic potential of any Claude Sonnet 4.6: 69.0% → 80.0% on BrowseComp-Plus (+11.0, −$424).
💡The Magic:
The agent searches the raw corpus directly — `grep`, `find`, `bash`, shell pipelines — exactly like a coding agent navigating a codebase. No preprocess. No embedding model. No vector index. No offline indexing.
📊The Results:
DCI outperforms top baselines across 13 benchmarks, with average gains of:
🔍 Agentic Search: +11.0%
🧠 Multi-hop QA: +30.7%
📈 IR Ranking: +21.5%
💡 Insights:
Beyond accuracy, we conduct a series of controlled ablation studies to pinpoint the sources of DCI’s gains. Specifically, we examine trajectory-level search, evidence utilization corpus, context management, and tool usage (RQ2-RQ6).
Try it yourself!
🛠️Code: https://t.co/A8ch5QM1E4
🤖 Demo: https://t.co/Y9H4abb2P6
🔎 Eval logs: https://t.co/4iM7u1M8mz
@s_gaweda Two criteria come to mind: (1) accuracy - did the agent do what the skill promises? (2) token efficiency - how many tokens did the agent have to burn?
Does this change if the SKILL is shared widely within an org? Does this change if an org uses multiple agents? Should I get Codex and Claude to iterate on the PR until they're both happy (and stay out of it)?
What are emerging best practices here? ⁉️
Since it is unlikely that the SKILL.md etc. 📜 was actually written by a human, who am I to second-guess what an agent writes, mainly for another agent (or itself at a later point in time)? 🤖
I assume the human has already iterated with the agent to refine the SKILL?