To mark the 2nd anniversary of LLM360, we are proud to release K2-V2: a 70B reasoning-centric foundation model that delivers frontier capabilities.
As a push for "360-open" transparency, we are releasing not only weights, but the full recipe: data composition, training code, logs, and intermediate checkpoints.
About K2-V2:
🧠 70B params, reasoning-optimized
🧊 512K context window
🔓 "360-Open" (Data, Logs, Checkpoints)
📈 SOTA on olympiad math and complex logic puzzles
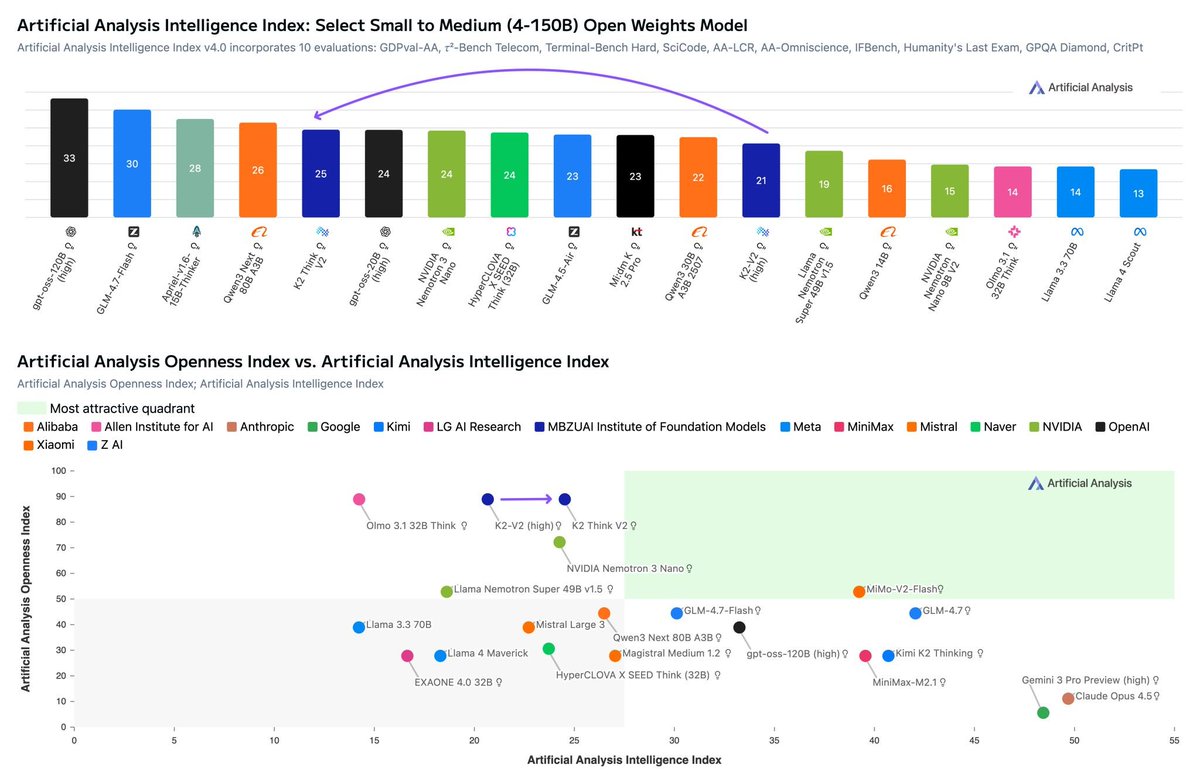
The #K2Think V2 we released today represents a significant leap of the already-strong performance on deep reasoning over V1 (https://t.co/qiELrJOmDt), and furthermore drastically improves on reliability, reducing the hallucination rate from 89% to 52% on the AA-Omniscience benchmark while simultaneously increasing long-context reasoning accuracy from 33% to 53%. Powered by the K2-V2 Instruct foundation, it is now the strongest fully open-source reasoning model available, and rivals all frontier reasoning models from the same size class, open or close.
Continuing the founding ethos of Institute of Foundation Models (IFM) at @mbzuai, we open source the weights, data, recipe, and development of this release: on top of the #K2Think V1 recipe, and the strong foundation of K2 V2 (https://t.co/0Kymo2B0mI) base LLM, we further made a few tailored designs that adapt well with the upgraded base model: 1) GRPO with asymmetric policy ratio clipping 2) expanded high quality STEM data sources 3) capability steering with model specific difficulty-based data filtering, 4) full on-policy training with large batch sizes. 5) two-stage progressive context length expansion for training efficiency. Check out our blog post and model for more details: https://t.co/gRQCevpzi0
@waterluffy, @llm360_agi, @allen_ai, @huggingface
We rigorously red-teamed K2 Think V2 using libra-eval. It achieves near-perfect scores on standard safety surfaces while maintaining high helpfulness.
Dive in now:
🤗 Model & Data: https://t.co/mNvIzgK9Ji
📄 Blog Post: https://t.co/3OeOuoM8iH
💻 Code: https://t.co/y3vkWRPStA
Please welcome K2 Think V2, our first fully sovereign 70B reasoning model.
Built on the K2-V2 base, this release bridges the gap between community-owned AI and proprietary models.
About K2 Think V2:
🧠 70B parameters, RLVR-tuned
🛡️ 100% Sovereign (IFM-curated data only)
🔓 Fully Open (Pre-training to Post-training)
💡 Top-tier Openness & Intelligence
How did we get here? A dedicated two-stage RLVR (Reinforcement Learning via Verifiable Rewards) process.
1. Stage 1: 32k context training (approx 200 steps).
2. Stage 2: Expanded 64k context for long chain-of-thought.
The result is a model that outperforms previous versions on AIME, HMMT, and IFBench.
To mark the 2nd anniversary of LLM360, we are proud to release K2-V2: a 70B reasoning-centric foundation model that delivers frontier capabilities.
As a push for "360-open" transparency, we are releasing not only weights, but the full recipe: data composition, training code, logs, and intermediate checkpoints.
About K2-V2:
🧠 70B params, reasoning-optimized
🧊 512K context window
🔓 "360-Open" (Data, Logs, Checkpoints)
📈 SOTA on olympiad math and complex logic puzzles
The secret sauce is our "Mid-Training" phase.
We didn't only fine-tune; we infused reasoning early by feeding K2 billions of reasoning tokens and extending context to 512K tokens.
This ensures reasoning is a native behavior. See how K2-High achieves state-of-the-art results by leveraging more "thinking tokens."
It is amazing to see it is already the 8th workshop for scaling law.
The LLM360 team will also be attending this, and @waterluffy will share what the team is doing at @mbzuai Institute of Foundation Models.
I am excited to be organizing the 8th scaling workshop at @NeurIPSConf this year!
Dec 5-6 | 5-8pm PT | Hard Rock Hotel San Diego
Co-organized by @cerebras, @Mila_Quebec, and @mbzuai
Register: https://t.co/aLOWHGjQDO
Check out the FastVideo series that allow you to generate a video in real time (5 second video in 1 second)! Try it out on your own hardware too.
Kudos to the team for democratize these by providing efficient methods and the full recipe.
(1/n) 🚀 With FastVideo, you can now generate a 5-second video in 5 seconds on a single H200 GPU!
Introducing FastWan series, a family of fast video generation models trained via a new recipe we term as “sparse distillation”, to speed up video denoising time by 70X!
🖥️ Live demo: https://t.co/XsEYcb7mHE (Thanks to @gmicloud for the support!)
🔗 Blog: https://t.co/bmfmQVaoG8
🔓 We fully open-source our models, code, and data with Apache-2.0 licenses
🚨 “The Diffusion Duality” is out! @ICML2025
⚡️ Few-step generation in discrete diffusion language models by exploiting the underlying Gaussian diffusion.
🦾Beats AR on 3/7 zero-shot likelihood benchmarks.
📄 Paper: https://t.co/vyl1mVVI81
💻 Code: https://t.co/LN883NB8nr
🧠 Blog: https://t.co/3XMb2xfxLz
(1/8)
KV-caching is great, but will it work for Diffusion Language Models. @zhihanyang_ and team showed how to make it work with 65x speedup 🚀!
Checkout the new preprint: https://t.co/JwjyLQf33r
The LLM360 team is very interested to explore new architectures.
The LLM360 team continue to adhere to the value of open source, and we believe data is one of the most important ingredient. Please let our team know if you have any comments. We are eager to hear voice of the community!
📢📢 TxT360 has been updated to v1.1:
🌟 BestofWeb: high-quality doc set from the web
❓ QA: Large Scale Synthetic Q&A dataset
📖 Wiki_extended: extended wiki articles via links
🌍 Europarl Aligned: reformatted long aligned corpus
https://t.co/z8xukj0ZyZ #AIResearch #OpenSource
🐍 Unlock the power of long-context data with our new Wikipedia Extended and Aligned Europral datasets in v1.1!
We've created long context documents by extending Wikipedia articles with related abstracts, and align multiple Europarl languages into one training samples! #LongContext #Data #Wikipedia
















![zhihanyang_'s tweet photo. 📢Thrilled to share our new paper: Esoteric Language Models (Eso-LMs)
> 🔀Fuses autoregressive (AR) and masked diffusion (MDM) paradigms
> 🚀First to unlock KV caching for MDMs (65x speedup!)
> 🥇Sets new SOTA on generation speed-vs-quality Pareto frontier
How? Dive in👇 [🧵1/13]
📜Paper: https://t.co/KJzjaXPJY0
📘Blog: https://t.co/azyr050fNr
💻Code: https://t.co/CkFl3DXpnz
Project co-led with @ssahoo_](https://pbs.twimg.com/media/GsieEHqasAQ6JzJ.jpg)





























