Transfer learning shines when:
Both tasks use the same input type.
You have much more data for Task A than Task B.
Features learned from Task A help Task B.
#LearnAI 🚀🤖
Transfer learning 🚀 lets you reuse a pre-trained neural network (like for image recognition) on new tasks (like radiology diagnosis) with less data & faster training! It's a game changer for #DeepLearning in real-world AI! 🔄🤖 #LearnAI
Why does AI always have to be this massive, generalized, 90%+ accuracy beast?
What if we just trained tiny, fast models built for one user only? Or train model using user data
#learnai
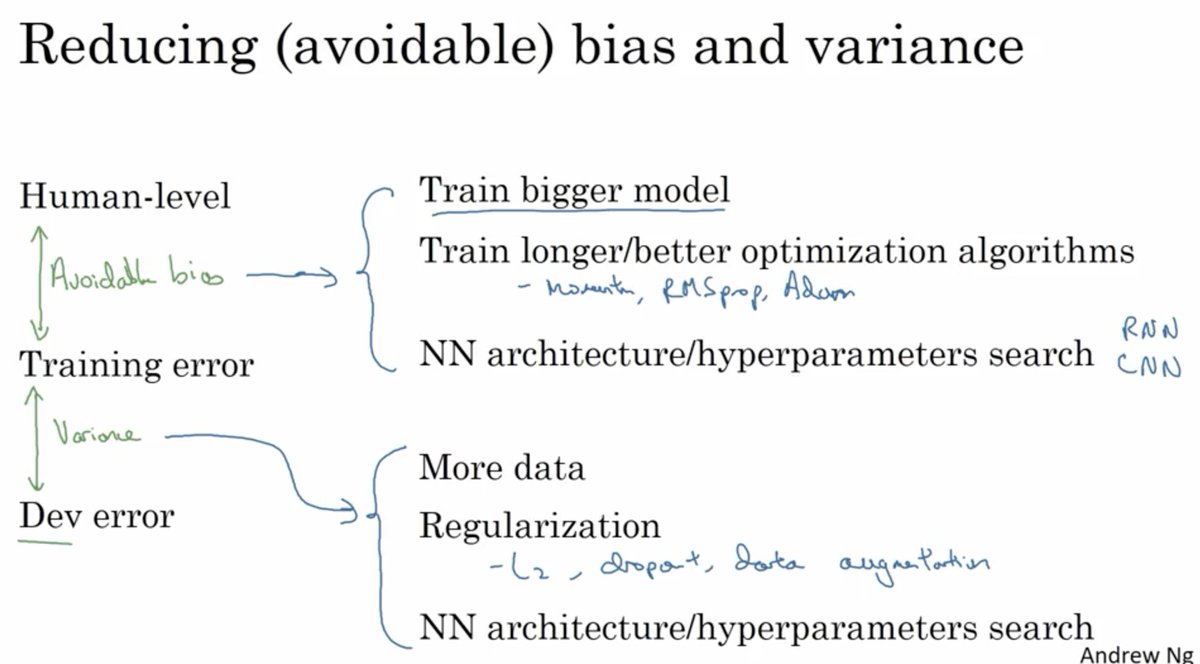
Battling high bias? ➡️ Try bigger models, better optimizers (Adam, RMSprop), or new architectures (CNN/RNN).
Fighting variance? ➡️ Add more data, or regularize (L2, dropout, data augmentation).
#LearnAI 🧠🔬 Which is your challenge right now?
🚀 When tuning ML models, always compare training/dev error with human-level error! If training error ≫ human error → fix bias. If dev error ≫ train error → fix variance. Human-level error = your north star for realistic model performance! #LearnAI 🧠🐱
Just Learnt:
If training error ≫ human error, fix bias;
if dev error ≫ training error, fix variance.
Always compare to human-level for realistic goals! #LearnAI 🐱🤖
Not all errors matter equally! 🚩 Even with just 3% error, Algorithm A is riskier if it lets pornographic images slip by. Always tune your loss function to penalize critical mistakes more heavily, not just minimize error rate. #LearnAI
Cluely isn't just for hacking meetings — it's how AI understands your screen. A top tool for hands-on learning and AI research. 🧠💻 #LearnAI#Cluely#ResearchTools
BatchNorm isn't just about speeding up training—it adds noise to each mini-batch by normalizing with its own mean/variance. This acts like a gentle regularizer, a bit like Dropout, making your model more robust! 🚀 #LearnAI
🚨 Just learnt - Neural networks can struggle due to internal covariate shift! Batch normalization (BN) helps stabilize and speed up training by normalizing activations layer by layer. 🔥 #LearnAI#MachineLearning
🚀 Mini-batch & BatchNorm in deep learning: Using mini-batches boosts efficiency, and BatchNorm replaces bias b with learnable β for better normalization & training stability! #LearnAI
Normalizing inputs in neural networks accelerates learning by ensuring all features have similar scales. This reduces training time and improves convergence. Always normalize your data before training for optimal results! 🚀 #LearnAI
🚀 Hyperparameter tuning: Don’t “babysit” one model like a panda 🐼. Run many experiments in parallel like caviar—test lots of models, find the best fast! 🔥 #LearnAI#deeplearning
💡Hyperparameter tuning tip:
Sampling uniformly isn’t always smart.
Learning_rate: use log scale
→ 10^r, with r ~ U[-4, 0]
Beta for moving average:
→ beta = 1 - 10^r, with r ~ U[-3, -1]
Why?
🔍 Sensitivity is nonlinear
📉 You waste resources if you don’t scale right
#LearnAI