AI-powered medical writing for CROs, consultancies & life sciences companies. Generate compliant docs faster across clinical, regulatory & strategic workflows.
Heading to #MedTech2025? Join us at The MedTech Rendezvous — curated, invite-only networking hosted by Log10 | Everest.
📅 Oct 6 | San Diego
🔗 Request access: https://t.co/4SqpmVm3t2 (space is limited)
#LifeSciences#AIinMedTech
Tomorrow night at Dev&Data Night ⚡️
@coffeephoenix, CEO of Log10, will share how Everest is transforming regulatory writing with agentic AI—helping life sciences teams and CROs move at lightning speed while maintaining precision and compliance.
🔗 RSVP: https://t.co/vwfg9eo0tE
In San Diego on July 29th? @coffeephoenix brings his insights on AI to a panel of industry leaders.
Secure your spot: https://t.co/vwfg9eo0tE
#HealthTech#AI#SDTech
Everest now supports Gemini 2.5 Pro, now GA on Vertex AI—congrats to the Google team!
🧠 Better multi-doc memory
📄 Improved scientific precision
⚙️ Extended workflows for protocols, CERs, CSRs & more
See what’s under the hood → https://t.co/UnMf3uQvnt
#Gemini25#VertexAI
🔐 Everest is now SOC 2 Type II & HIPAA compliant! 🎉
Our AI platform helps CROs, consultancies & life sciences teams generate accurate clinical & regulatory documents—faster, safer, and at scale.
Now fully certified for security & privacy.
🔗 https://t.co/sklsGObQu0
🚀 Introducing Everest: AI-powered medical writing for life sciences!
Our new platform helps medical device, pharma & diagnostic companies (and their CROs) bring products to market faster with:
Speed up development with an #AI system that scales expert review, enables real-time error detection, and empowers your team to achieve production-level accuracy.
Evaluation ⤵️
Establish evaluation-driven development with a declarative test suite that seamlessly utilizes…
[Watch] Our Co-Founder and CTO, @NiklasQuarfot, demonstrates how Log10's AutoFeedback can assist in the quality of tasks like summarizing long content.
Vibe checks are the way you get started building AI applications, but there comes a time when they're no longer a sufficient approach.
Our Co-Founder and CTO, @NiklasQuarfot, shares the alternative and how Log10 changes the approach.
Large Language Models (LLMs) are reshaping healthcare by automating tasks like after-visit summaries (AVS).
Using the MIMIC-IV dataset, we evaluate their accuracy and reliability in clinical settings. 👇 https://t.co/Bqvhy8QPIK
.@OpenBB_Finance transformed its AI-powered Copilot for financial analysts by integrating Log10's advanced observability tools.
Improved accuracy, faster debugging, and user insights now ensure reliable performance, reducing churn and boosting confidence.
Discover how observability is reshaping AI! 👉 https://t.co/YsGg6nGu87
💡 Case Study Spotlight: See how Assort Health transformed patient experiences with Log10's observability tools!
🔍 Challenges:
- Complex scheduling rules
- Latency-sensitive AI
- Debugging inefficiencies
✅ Solutions:
- 5x faster debugging
- Real-time insights with Log10's dashboard
- Scalable observability for AI growth
Result? Frustrating calls turned into personalized care.
📖 Read the full story: https://t.co/Em2gVmq3JJ
Your dev team needs an end-to-end solution. Look no further than Log10!
Get a glimpse at how it works in this quick demo video with Log10 CEO and Co-Founder Arjun Bansal (@CoffeePhoenix).
Log10 CEO and Co-Founder Arjun Bansal (@CoffeePhoenix) outlines what AI apps need to break into healthcare:
📊 Better data sets
🔏 Data privacy (SOC2, HIPAA)
🔎 Role responsible for AI oversight
Here's how Log10 can help bridge the gap:
💡 Intuitive UI and workflow
✔️ Checkpoints for human review of evaluation models
📈 Continuously improving data quality
Stop deploying AI based on "vibes"! 🛑
Discover how Latent Space Readout (LSR) revolutionizes GenAI app evaluations with better accuracy, 20x sample efficiency, and faster customization. 👇 https://t.co/JRkhWz3Sf5
LLMs have a hard time reliably self-evaluating accuracy for a variety of reasons:
• Biases in models
• Tendency to prefer their own output
• Positional + verbosity bias
• Preferring outputs with more diverse tokens over accuracy
• Model output inconsistency
In this video, Log10 CEO and Co-Founder @CoffeePhoenix dives deeper into this subject.
💡 Advice for new #AI developers: Start with small tests, capture data and use it as a reference for those tests, and create offline evaluations.
💬 What advice would you add? #LLM
LLMs are transforming healthcare workflows by reducing provider burnout and streamlining administrative tasks.
But many wonder if they deliver the accuracy required for processing complex medical domain text in high-stakes scenarios.
In this blog, we evaluate their performance and highlight limitations.
⚡ Want a quick overview? Here are some key takeaways:
1️⃣ Accuracy Issues Remain: Human expert review of clinical text generated by gpt-4o and Claude-3.5-Sonnet uncovers consistent errors.
2️⃣ Common Error Patterns Result in Varying Risk: A recurring issue is LLMs’ tendency to infer or fill in information based on contextual cues, resulting in inaccuracies that vary in severity depending on the context.
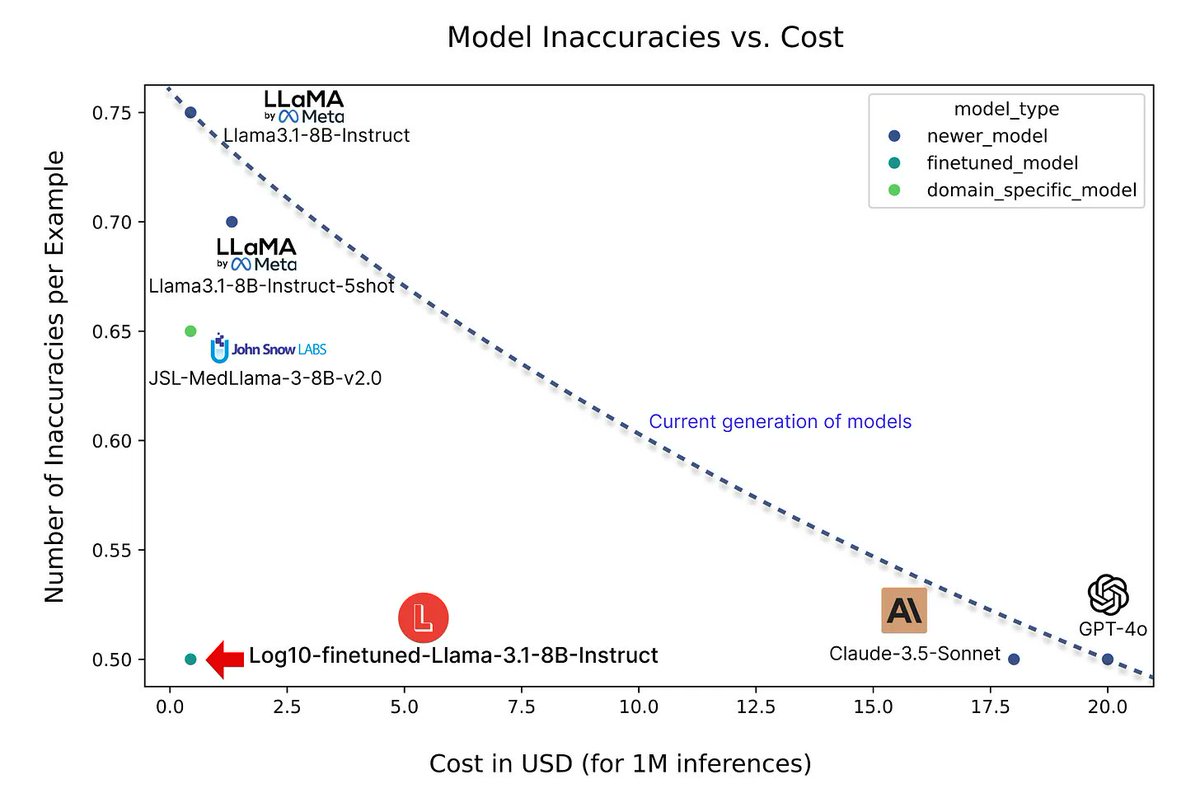
3️⃣ Fine Tuning is Still a Good Bet: Fine-tuned, open-source models match the accuracy of proprietary systems at a fraction of the cost.
4️⃣ LLM-as-Judge Falls Short: Automated evaluation is fast but prone to biases and inconsistencies, making human oversight essential for clinical tasks.
5️⃣ Innovation Is Key: Techniques like Latent Space Readout, developed at Log10, surpass LLM-as-Judge in accuracy, offering a more reliable solution for healthcare.
Why It Matters ⤵️
Clinical applications demand uncompromising accuracy while maintaining cost-effectiveness.
While LLMs show great promise, achieving trustworthiness requires innovative methods and expert oversight.
Take a deeper dive here: https://t.co/hEZd1Gn4My
Log10 CTO and Co-Founder, @NiklasQuarfot, shares insights on bridging the gap between traditional software engineering and LLM application development in this short video.