Quick announcement- I no longer maintain yolo or work on adding features & answering issues. I appreciate all the lovely DMs and emails and I try not to ignore any. Also, I haven't kept up with latest developments from past months so I can't really answer those anyways. Thanks!
glad that we share the thesis with @EngramLab
model specialization is not nice to have; but is a requirement for building truly autonomous agents
congrats to @dan_biderman and the whole team
Noam is a legend. This is the conclusion of his GLU paper
```
We offer no explanation as to why these architectures seem to work; we attribute their success, as all else, to divine benevolence.
```
https://t.co/Kzd851d3uc
We're launching Macrodata Labs.
Me and @gui_penedo have spent the past three years in the trenches working on data for training LLMs. This gave us a unique perspective on how the field has progressed - from GPT-3-era models capable of little more than simple completions to today, where agents are writing a substantial share of the code being shipped.
This progress was enabled by just two components: scaling data and compute while being extremely deliberate about what data to use and what not to use. Look at failed training runs and ask researchers what caused them - poor data quality is almost always at the top of the list.
While LLMs have undergone this Cambrian explosion, robotics today feels exactly like LLMs did back then. There is still no clear recipe for what will work. Every team has its own opinions on embodiment and architecture, yet they all agree on one thing: the most important problem to solve is data and how to scale it.
Nobody knows yet whether the answer lies in simulation data, egocentric data, IMU data, or something completely different.
Whatever the answer turns out to be, every team still has to go through the same process: acquiring the data, filtering problematic episodes, synchronizing sensor values, annotating episodes using VLMs, splitting episodes into subtasks, or, in the case of egocentric data, extracting 21-DOF hand annotations. Finally, all of this has to be converted into training-ready datasets before training starts as choosing a bad format for training will waste GPU cycles.
These pipelines need to run continuously. Every day, new episodes arrive from in-house data collection efforts and external vendors. Teams not only have to deal with the peculiarities of working with video data, ensuring sensor streams are error-free and avoiding unnecessary video decoding, but also need to support ingestion from whatever formats their data vendors provide.
Many teams are solving these problems today, yet you'll quickly discover that 99% of the solutions are collections of one-off scripts, which everyone hates the moment something goes wrong. Researchers end up digging through repositories trying to find the script that performed a particular operation three months ago, not even knowing whether they're looking at the version that was actually run.
What people want is something as scalable as Spark and as trackable as Weights & Biases.
That is what we created Macrodata Labs to build.
Our first step is Refiner, an open-source framework for processing robotics datasets.
We designed Refiner to help robotics teams turn raw demonstrations into training-ready datasets. Instead of maintaining collections of one-off scripts, teams can use Refiner to ingest heterogeneous robotics data, synchronize sensors, run annotation workflows, extract signals like hand tracking, split trajectories into subtasks, and continuously process new data as it arrives.
Alongside Refiner, we're also launching Refiner Cloud. With a one-line code change, the same pipeline can scale on our platform, with sharding, checkpointing, failure recovery, lineage tracking, and observability built in—so teams can focus on what matters most: data, not infrastructure plumbing.
We're incredibly fortunate to have the support of @airstreet , @DrysdaleVC , OPRTRS Club, @kimaventures , YG (Alex Yazdi), >commit, @Thom_Wolf , and an amazing group of angels from leading AI labs and technology companies who share our belief that data will be one of the defining challenges in robotics.
If this resonates with you, give Refiner a try, and don't hesitate to shoot me a message. We'd love to chat.
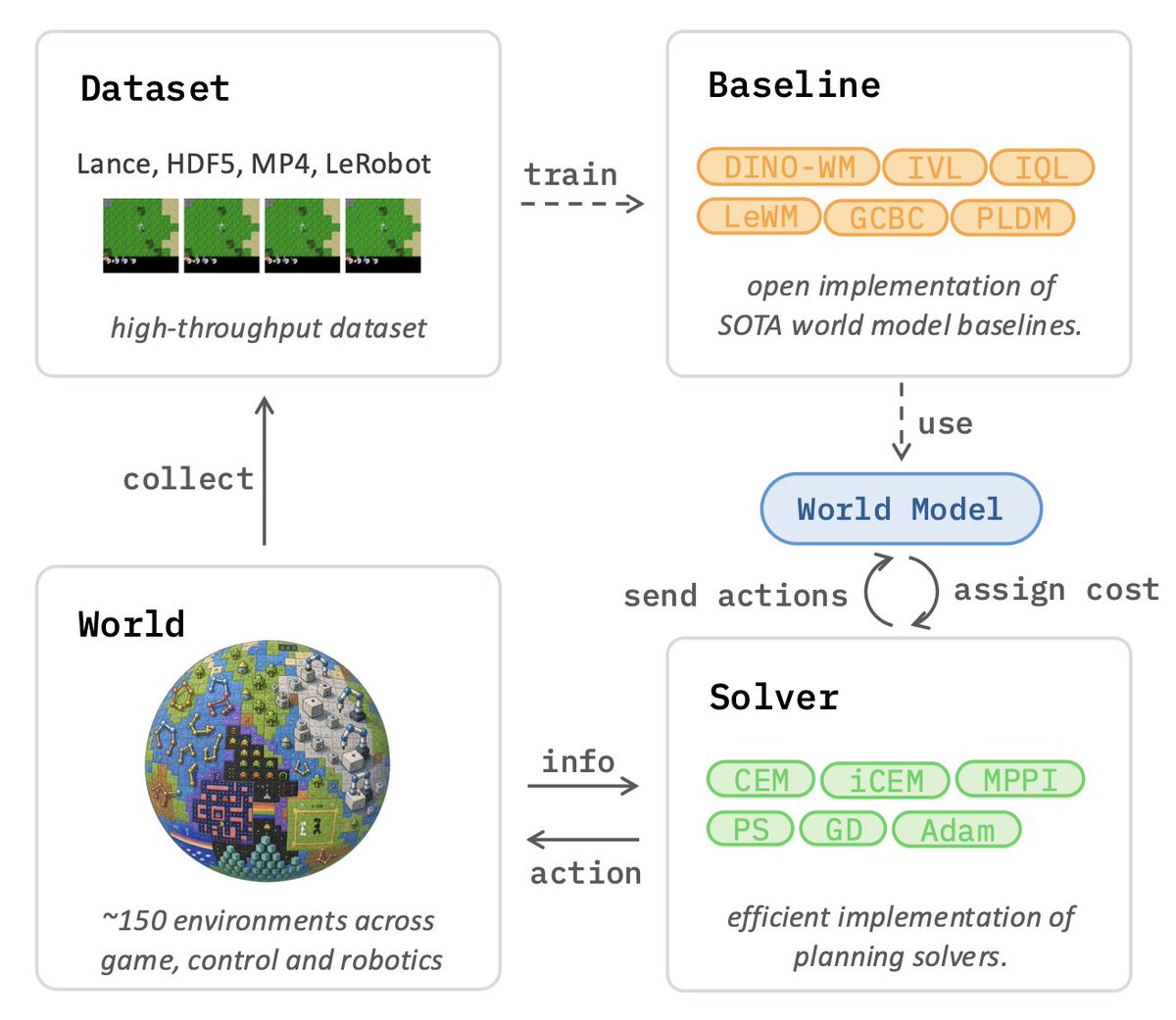
1/ May's highlight: stable-worldmodel paper published, standardizing world model pipelines on Lance, with Lance-backed S3 streaming several times faster than HDF5 for small-batch random access.
1/ 3-4x faster data loading on Push-T vs HDF5 or video formats at a fraction of the disk size. stable-worldmodel uses Lance as the data layer — here's the training walkthrough.
Our stable-worldmodel library:
- open-source
- well tested and documented
- comes with tons of envs and supports your custom ones
- collect data, pretrain, plan, evaluate, ...
- scalable to any cluster (thanks to our stable-pretraining backend)
Time to focus on research!
Most work still relies on MP4 videos ... creating a major bottleneck that kills GPU utilization and training throughput.
Not anymore.
We teamed up with the incredible @lancedb team to build blazing-fast data loading with native @huggingface bucket streaming support! ⚡
This work was co-created with @quentinlldc!
Huge thanks to all our incredible contributors and collaborators: @rwgao @luizfysouza@_fracapuano@ylecun@randall_balestr and the whole team 🙏
Paper: https://t.co/52HS8grawi
Code: https://t.co/0w3peE2suD
Would you like to join the research effort on JEPA and World Models easily?
After a full year of hard work, we’re excited to finally release stable-worldmodel:
an open-source, scalable platform built to accelerate JEPA & World Model research!
📄: https://t.co/gnxGvens5A
@kunchenguid the argument for harness is that a custom built harness augments the model. so the model doesnt have to do the heavy lifting alone.
if you can get by with a simpler post-training/fine-tuning the model with some harness engineering, its a win.
@HKydlicek@lhoestq@tech_optimist Yeah exactly i agree 🤣 but there’s a bunch of decoding-on-fly flows online so i just wanted to confirm the workflow.
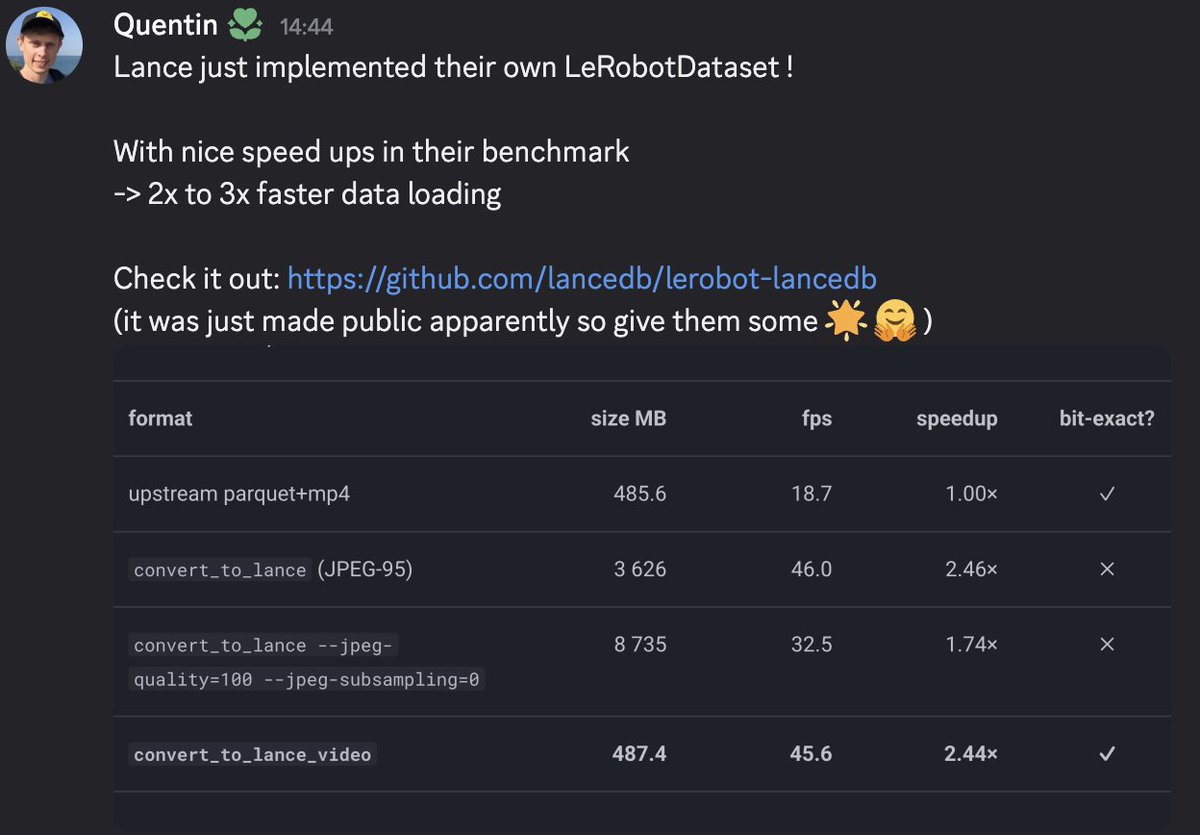
I’m working on something similar for training/dataloading with lance for VLM in general. Maybe some of it could be helpful. I’ll DM you!