Decentralized GPU networks are pivoting. Self-custody deployment is replacing managed orchestration. Miner pilots are pulling consumer GPUs into permissionless supply.
One network shipped a self-hosted deploy console with a hard migration cutoff. Another launched a pilot onboarding operators on prosumer hardware. Same pressure underneath.
Centralized cloud: managed, billed, settled by the hyperscaler. Operators own nothing. Renters sign reserved contracts and wait for capacity.
Decentralized v1 fixed supply: permissionless GPUs, on-chain settlement, miner economics. Orchestration stayed gated.
The pivot: self-custody on both ends. Operators bring 3090s, 4090s, H100s with their own keys. Renters deploy from wallets they own. Clearing happens on-chain.
TCO collapses when the platform tax disappears. Spot capacity expands when prosumer GPUs come online without gatekeepers. LLM, MoE, LoRA workloads route to the cheapest node.
Margin doesn't vanish. It redistributes.
$LooPIN.
New agent runtime: long-running workflows, no pre-provisioned servers, state survives crashes, retries automatic. Agents that act for hours without babysitting.
Operational on the surface. Orchestration underneath.
Hyperscalers optimized for steady-state. Reserved instances, pre-warmed nodes, idle GPU burn. That breaks for agentic workloads — bursty execution, spiky tool calls, dormant gaps.
Durable workflows invert it. Compute attaches when the agent reaches, releases on suspend, resumes on wake. Cost tracks work, not headroom.
Durability needs a supply layer. An agent retrying against an empty pool is a stalled loop, not resilience.
Permissionless supply solves the bottom half. An H100 in Sao Paulo and an RTX 4090 in Warsaw clear the same reverse-auction queue. LLM, MoE, LoRA routing hits the cheapest qualified node, not the nearest hyperscaler region. Settlement clears on-chain.
Durable agents need durable compute. Whoever owns the settlement rail owns the workflow.
$LooPIN
AI agents will soon hold your medical records, banking creds, legal contracts. The TEE market projection of $12.36B by 2030 isn't compliance theater. It's the architecture bill coming due.
Agents drafting contracts touch your IP. Agents running portfolios see your net worth. Continuous inference, persistent context, total exposure.
Ask where that inference runs.
Centralized hyperscalers: data crosses their boundary, lands in their VPCs, gets logged. GDPR is a paperwork promise.
TEE-attested compute: silicon proves what code touched your data. Remote attestation, sealed memory, verifiable execution. Math, not promises.
Confidential compute is a baseline, not a premium tier.
Cost compounds. Agent workflows mean thousands of inference calls per user daily. Reserved H100 pricing becomes margin tax.
The answer: permissionless H100/A100/4090 supply, attested at silicon, settled on-chain, priced by reverse auction.
Agents inherit the trust model of their compute layer.
$LooPIN
The GPU "shortage" is a distribution problem. Millions of RTX 3090s, 4090s, and 5090s sit idle in homes and shuttered mining rigs while hyperscalers quote 18-month waitlists on H100 capacity. The bottleneck isn't silicon. It's coordination.
Centralized cloud can't touch this supply. Hyperscalers demand uniform fleets, predictable utilization, reserved-instance lock-ins. Distributed consumer GPUs break every assumption in that stack.
Workloads already fragmented. LoRA fine-tunes, MoE inference, batch rendering, smaller training runs - none need an interconnected H100 pod. Most run fine on a 4090. Demand reshaped faster than centralized supply could adapt.
Idle consumer GPUs are a multi-billion dollar latent pool. The question was never whether to unlock it. It was who builds the settlement layer - permissionless onboarding, dynamic pricing, on-chain clearing.
Only a coordination protocol unlocks this margin.
Whoever owns the matching layer owns the compute economy.
$LooPIN
RTX owners get paid to host compute. Hyperscaler customers pay to reserve it. Same workload class. Opposite economics.
Centralized cloud prices GPUs like real estate. Static SKUs, reserved instances, multi-year commits. Capacity sits idle. Bills don't move. TCO bakes in margin you never recover.
Permissionless compute prices like a market. Supply enters dynamically. Operators bid against each other. Inference, LoRA tunes, batch training each clear at marginal cost.
Pricing power is structural, not technical. Whoever owns the auction owns the rent.
99.99% uptime is no longer a hyperscaler moat. Distributed nodes, on-chain SLA enforcement, automated failover — reliability premium gets arbitraged away.
Consumer silicon is the lever. RTX 3090/4090/5090 idle in basements and regional DCs feeds the same orderbook as H100 racks. Supply curve fattens. Clearing price compresses.
Cheap GPUs aren't a promotion. They're what compute looks like when the orderbook is permissionless.
$LooPIN
A Grammy producer renders tour visuals on distributed GPUs. A gaming peripheral ships with an embedded AI companion. A personal agent runs inside your phone's secure enclave.
Different products. Same convergence.
The 3D rendering stack and the AI inference stack are merging. Ray tracing now sits beside diffusion. Real-time agents need both reasoning tokens and pixel synthesis. The pipeline is no longer "render then infer" — it's both, concurrently, on the same silicon.
Centralized clouds price these as separate products. Rendering instances. Inference endpoints. Agent runtimes. Three SKUs. Three contracts. Three margin stacks. The workload is unified. The billing is not.
Decentralized compute inverts this. One network. Many GPUs. Whatever model, whatever pipeline. Video synthesis, 3D assets, agent reasoning — same wallet, same hour, same chain.
The creative stack is multimodal by default. The infrastructure has to match.
One network. Every model. Permissionless.
$LooPIN
A consumer AI campaign generated 11,000+ images at $0.01 each. 3.24s avg response. Five days, zero downtime. The infrastructure: a permissionless GPU marketplace, RTX 4090s and 5090s.
Cloud inference APIs charge $0.03–$0.15 per image. Decentralized settlement landed at one cent. 15x cheaper on the same GPT-Image-2-class workload.
One layer down: AWS H100 on-demand sits near $6.88/hr. Neo-cloud and DePIN marketplaces clear the same silicon at $2–3. The spread isn't compute. It's margin, SLA insurance, idle-capacity tax.
Centralized inference is priced like a managed service. Decentralized inference is priced like a commodity.
Reverse-auction settlement collapses the spread. Miners bid for jobs. Clearing floors at hardware break-even. Consumer GPUs in 30+ countries, settled on-chain per inference. No egress, no reservation lock-in.
The diffusion and MoE era doesn't need centralized monopolies on compute. It needs GPU liquidity at market-clearing prices.
That's where $LooPIN compounds.
$61B into AI data center buildout in 2025. The bottleneck isn't silicon. It's coordination.
Hyperscalers ship H100 clusters in rigid SKUs. Reserved instances. 1-year commits. Region-locked capacity. Workloads don't behave that way. Inference is bursty. Training queues. Fine-tuning waits. Idle racks burn power while teams pay premium for compute they can't access.
Utilization tells the story. Centralized GPU fleets sit at 30-50% average load. The other half is sunk cost in markup. The $2-4/hr H100 sticker isn't pricing scarcity. It's pricing inefficiency.
Flip the model.
Permissionless networks don't pre-package capacity. Demand finds supply via reverse-auction settlement. Miners bid utilization. Jobs clear at market rates. Idle silicon monetizes instead of writing off. Same hardware. Different coordination layer. Cost compresses against centralized rates.
Capacity isn't the problem. Coordination is. Whoever owns the matching layer owns the next compute cycle.
$LooPIN
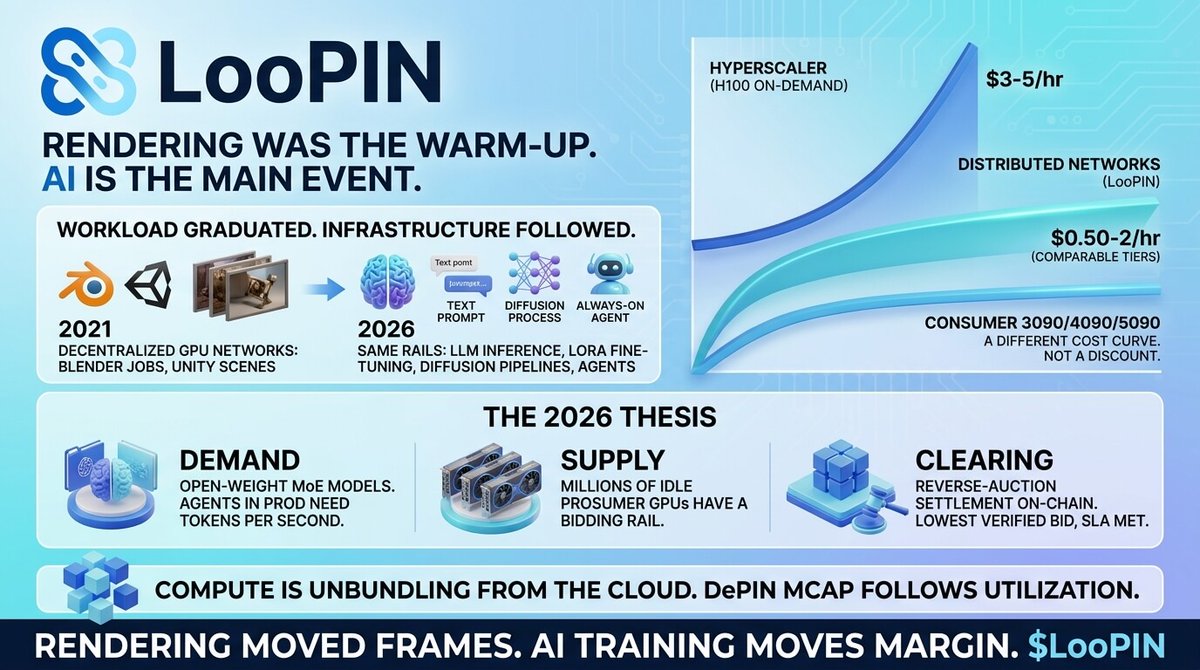
Rendering was the warm-up. AI is the main event.
In 2021, decentralized GPU networks cleared Blender jobs and Unity scenes. In 2026, the same rails serve LLM inference, LoRA fine-tuning, diffusion pipelines, and agents that never sleep. Workload graduated. Infrastructure followed.
Hyperscaler H100 on-demand sits near $3-5/hr. Distributed networks clear $0.50-2/hr on comparable tiers. Consumer 3090/4090/5090 prices a step below. Not a discount. A different cost curve.
The 2026 thesis rests on three legs.
Demand: open-weight MoE models pushed inference into commodity territory. Agents in prod need tokens per second, not a logo on the invoice.
Supply: millions of idle prosumer GPUs finally have a bidding rail.
Clearing: reverse-auction settlement on-chain replaces enterprise sales. Jobs route to the lowest verified bid meeting SLA.
Compute is unbundling from the cloud. DePIN mcap follows utilization, not narrative cycles.
Rendering moved frames. AI training moves margin.
$LooPIN
AWS H100: $3.90/hr. Azure H100: up to $6.98/hr. Specialist neo-clouds: $1.90/hr. Same silicon. 2-4x spread on what should be commodity compute.
AWS cut H100 on-demand 44% in mid-2025 under competitive pressure. Months later, rates jumped 10% in four weeks while A100 and B200 held flat. When one SKU moves that hard in isolation, pricing isn't cleared — it's negotiated.
TCO compounds past the hourly line. Egress. Storage. Reserved minimums. Savings Plans that lock you in before Blackwell ramps. Headline rate is marketing. The invoice is something else.
The fix isn't another provider. It's a different clearing mechanism — compute settling like spot power. Reverse-auction. On-chain. Permissionless supply from anyone with a 3090, 4090, 5090, or rack.
Dynamic pricing isn't a feature. It's what compute looks like when the supply side is open.
$LooPIN
The physics are unambiguous.
~ Distributed thermal load dissipates.
~ Distributed regulatory exposure hedges.
~ Distributed energy sourcing diversifies.
Centralized infrastructure is a single point of failure dressed in enterprise SLAs. AI at scale needs permissionless, resilient compute — not data centers one policy vote from shutdown. $LooPIN
US data centers are projected to consume 9% of national electricity by 2030.
Virginia's data center corridor already draws more power than Portugal.
Thermal heat islands are now measurable from satellite.
One grid failure cascades across thousands of simultaneous inference jobs — no failover, no geographic hedge.
Distributed GPU networks invert this risk profile.
- Miners operating across jurisdictions, time zones, and grid operators.
- No single legislature kills the network.
- No heat island forms when compute is geographically diffuse.
Dynamic reverse-auction pricing absorbs supply shocks that crater fixed-cost hyperscaler margins.
OpenAI just closed $122B. One company. One balance sheet. One failure point.
The narrative is "democratizing AI." The architecture says otherwise. Capital at this scale doesn't distribute compute access — it centralizes who gets it, at what price, and on whose terms.
Centralized GPU clusters carry compounding systemic risk: single regulatory jurisdiction, grid dependency, no competitive pricing pressure. When the grid strains or policy shifts, inference workloads don't reroute — they go dark. Energy pressure is already showing up in hyperscaler TCO projections.
Decentralized compute inverts this. Distributed nodes eliminate single points of failure. Reverse-auction settlement means rates clear at real market value, not incumbent margin targets. Consumer GPUs become productive infrastructure.
The $122B question isn't whether OpenAI can scale. It's who controls the settlement layer when they do.
AI running on one balance sheet is AI one company can reprice, restrict, or shut down.
Concentration isn't democratization. The margin doesn't disappear — it just stays captured. $LooPIN
Year three is already taking shape.
- More AI apps.
- More startups onboarding.
- Better tools for miners to organize their machines.
- A UI that actually respects your time.
We built this for open, affordable, accessible compute. That work isn't close to done. $LooPIN
Two years.
That's how long it's been since we pushed the first block on Solana devnet — April 8, 2024.
Back then it was a small team, a big idea, and a lot of unknowns sitting right in front of us.
Tonight the second yearly halving kicks in.
Daily $LooPIN emissions drop from 50K to 25K.
If you're a miner and your numbers have been shifting lately, don't stress — that's just the network rebalancing as rigs come online and offline.
RTX 3090 / 4090 / 5090 holders should end up close to where they were before the halve. The pool mechanics handle it.
DePIN inverts the logic. Dynamic pricing clears at real market rates. Idle GPUs enter supply. Buyers get honest price discovery, not managed scarcity.
The margin doesn't disappear. It redistributes.
AI agents, inference workloads, open-source deployment at scale — infrastructure economics outweigh model architecture. $LooPIN
By design. Scarcity is the product.
Centralized providers profit from constrained supply. Limited availability justifies premium tiers. Those tiers fund infrastructure that serves enterprise SLAs first, builders second. Open-source deployment gets structurally priced out. That's not inefficiency — it's the business model.