a bit late of a notice but happy to share a paper i've been cooking up with @lrvarshney was accepted to the #ICML2026 Second Workshop on Agents in the Wild!
we've been working on AI safety guarantees independent of alignment (arxiv link in comments).
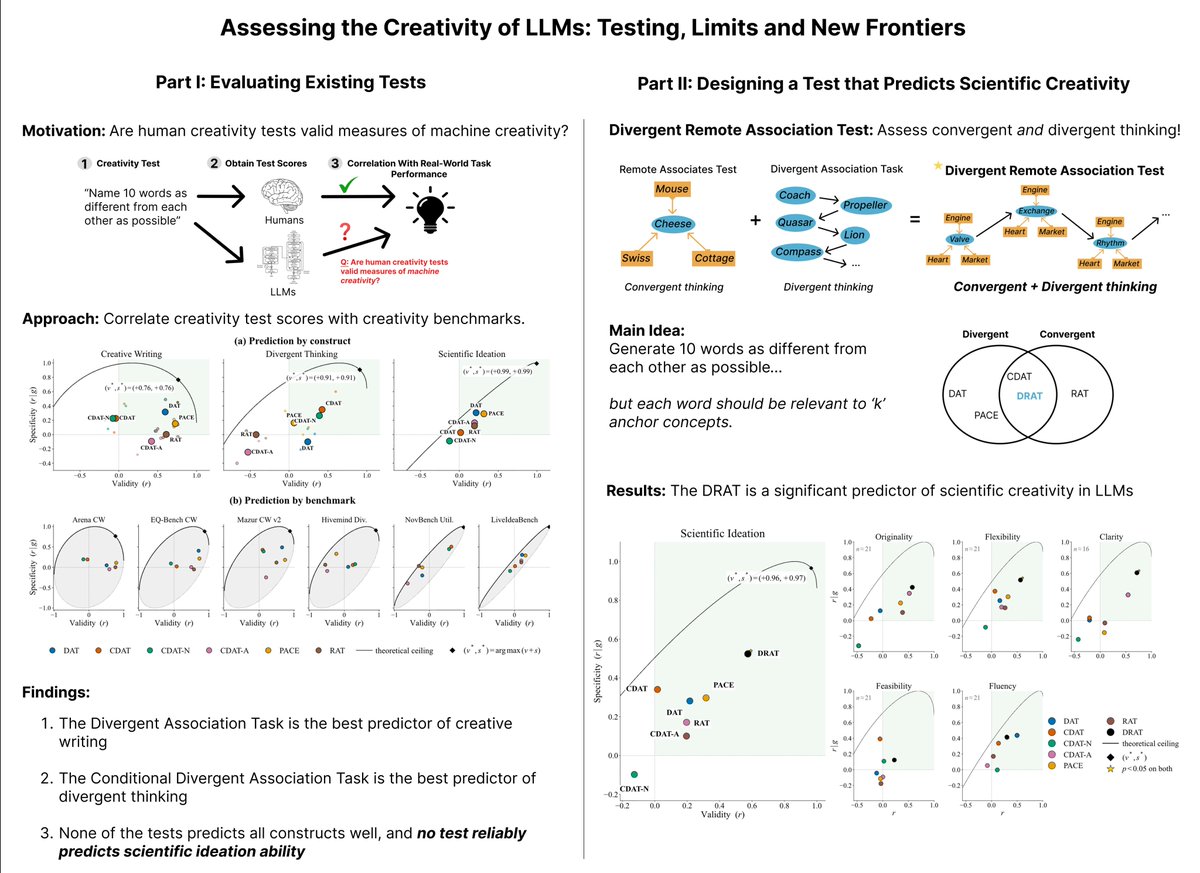
Are human creativity tests actually good predictors of creativity for large language models?
These tests are now widely applied to assess how “creative” large language models are, but their validity as measures of *machine* creativity has never actually been established.
Our new paper studies this question in detail:
💡We ran a large-scale study correlating LLM performance on human creativity tests with creative writing, divergent thinking, and scientific ideation benchmarks.
Main findings:
✍️ The Divergent Association Test (“name 10 words as different from each other as possible”) is the best predictor of creative writing ability.
💭The Conditional Divergent Association Test (“name 10 words as different from each other as possible, while staying relevant to a given cue word”) is the best predictor of divergent thinking
🚫 However, no single test predicts all three aspects (creative writing, divergent thinking, scientific ideation) well
🚫 Moreover, and contrary to popular belief, none of the tests is a reliable predictor of scientific ideation ability!
Solution:
We introduce the Divergent Remote Association Test, a novel creativity test that assesses both divergent *and* convergent thinking ability at the same time.
✅ The Divergent Remote Association Test is the first test to achieve significance in both evaluation criteria—validity (𝑟 = +0.57, 𝑝 ≈ 0.008) and specificity (𝑟 |𝑔 = +0.50, 𝑝 ≈ 0.02)—for predicting scientific creativity.
————
Thanks to my co-authors @AlexiGlad, @jonahablack, @hengjinlp, as well as other colleagues who provided helpful feedback on the manuscript: @Roger_Beaty, @BabakHemmatian, @lrvarshney.
Paper link: https://t.co/cU7FQ7Lr0r
This isn't just structuring agent interaction with MCP or just orchestrating agents with langchain, it is provably secure under havoc oracle semantics.
Really addresses a core need for trusted AI.
I'm happy to be along for the ride!
Royce Moon has done really incredible work on a containment layer for agentic AI. It ensures AI safety without having to dig into the internals or alignments of AI models, by formally verifying interactions with the world. Works whether considering superintelligence, super-duper intelligence, or anything beyond. https://t.co/Uemr5JXYAT
Engineering safety in high-consequence domains has historically relied on fail safes whose guarantees do not depend on the controlled system functioning correctly. In nuclear engineering, a nuclear reactor’s control rods drop via gravity when active control is lost. The same construction is realized in process engineering by pressure relief valves that discharge at threshold regardless of root cause, and in computer architecture by hardware memory protection that enforces isolation between processes whatever the running process attempts. This is it for agentic AI.
Governance faces the same question. The database world built access control and audit trails because trust required them. That work now needs to happen across the entire AI stack.
Grateful to @gsifthrive GSIF for a room genuinely wrestling with this.
Photo credits: @lrvarshney
Excited to share our new paper Iterative Decoding of Stabilizer Codes under Radiation-Induced Correlated Noise is on arXiv:https://t.co/3pwKONXGQF. Thanks to my advisor @lrvarshney and thanks to Paul Baity and team at @BrookhavenLab.
Applications are now live!
Cohort 0 starts March 13th in Presidio with OpenHands, OpenRouter, alphaXiv, Fireworks, Dedalus Labs, Franklin Templeton, Founders Fund and Pantera.
→ $25K+ in prizes
→ 3 weeks building state-of-the-art AI agents
→ Many more surprises
Apply below 👇
New paper, "The network architecture of general intelligence in the human connectome" is out in Nature Communications today (link below), providing key insight into structural and functional aspects of the brain that are associated with individual differences in performance on intelligence tests. Our team did amazing work: Ramsey Wilcox, @BabakHemmatian , and @DecisionNeurosc!
The general intelligence factor g is one of the most robust findings in psychology and is predictive of numerous social outcomes such as educational attainment, job performance, and health. It is traditionally thought of as a psychometric statistical abstraction, but we show it arises from structure and coordinated activity across the brain’s global network architecture.
I spoke to @nbcchicago about new data centers, their uses, and their potential impacts. I believe balancing costs and benefits is very much a local issue for each community to figure out
https://t.co/iaOw1kIz9N
Federation, pooling, ensembling, complex constructions from individual models, etc.: lots of technical ways emerging for institutions to work together on AI!
With our friends from University at Buffalo @lokhande_tweets and Lawrence Livermore National Laboratory, new paper led by Ayush Roy "Beyond Pooling: Matching for Robust Generalization under Data Heterogeneity" will be at AISTATS 2026 in Tangier, Morocco.