Last year I released the container image I use to compile @CrystalLanguage apps.
You can use it to build and test against different version, 1.2, 1.3 or latest 1.5.1
This started a series of experiments on things I'm working on since then...
1/ 🧵
Decided to make public my Alpine-based, Crystal development container image: hydrofoil-crystal
https://t.co/OTD3fUp6UH
Quick demo of Radix library using it to automatically run specs on changes. Have fun!
@CrystalLanguage#crystallang
Service port proxying (or forwarding) is coming to Uncloud:
uc proxy SERVICE [LOCAL_PORT]:REMOTE_PORT
It’s useful for troubleshooting an internal service that is not exposed publicly, testing a web service before publishing it, or accessing a database.
One handy command for many use cases. It’s like ‘ssh -L’ but it automatically handles the wiring to the right container on the right remote machine.
And it’s only ~80 LOC as we already had the right primitives so an external contributor could easily put them together. Love it!
@nateberkopec My AGENTS rules:
* Be brief, lead with the point, then explain why
* Explain problem or context in the first two sentences
* Keep language simple, target english and non-native speakers
* Short paragraphs, one idea per sentence, commas and parenthesis for asides
@nateberkopec Automatic SSH aren't forwarding could be an issue if the agent "decides" to push to the remote. Also it might not work with 1password on the host.
AI agents running on your machine inherit every credential you have. AWS, Kubernetes, SSH keys, all of it.
I run mine inside 'Dexter', a locked-down Debian VM. No sudo, no synced credentials, no push access. Just the tools the agent needs.
https://t.co/wWUqchlDeV
@nateberkopec@samsaffron That is basically my setup: a remote LXC machine (Incus), a unprivileged user; repos are sync from my machine using syncthing (that excludes .env or similar files) and opencode as a systemd service running as that user (so I can access it via web/tailscale)
Uncloud just got its first university adoption! 🎓
Radboud's Faculty of Science is rolling it out to manage Docker clusters for their research groups.
They're going for:
→ 300+ websites across a dozen machines
→ 100+ people who need to self-serve
→ each research group gets a VM or cluster they fully control
→ self-host the entire web stack including DB + automated S3 backups
→ GitLab environments for deploy-on-green workflows
→ platform team out of the loop
>"It looks very much like docker compose or the (semi-deprecated) docker swarm, and there is good documentation"
And a huge thanks to @miekg for digging in, reporting issues and contributing fixes over the past few weeks 🙏
Can't wait to see it running in production!
Just shipped Uncloud v0.18 🎉
→ Deploy plan got a glow-up - much nicer to read and understand 👇
→ Pre-deploy hooks - run DB migrations before new code goes live
→ System 'ssh' is now the default - faster commands and full SSH config support
→ Pin compose.yaml to cluster with 'x-context'
📚 New docs!
🎙️ I went on go podcast() this week to talk about why I’m building Uncloud - Docker Compose for production, bridging the gap between Docker and Kubernetes.
We covered:
- why most projects don't need k8s and what alternatives we have
- a hybrid setup mixing cloud VMs and on-prem
- WireGuard mesh networking
- unregistry - direct image push to servers without a registry
Give it a listen on any podcast platform and let me know what you think! 🎧👇
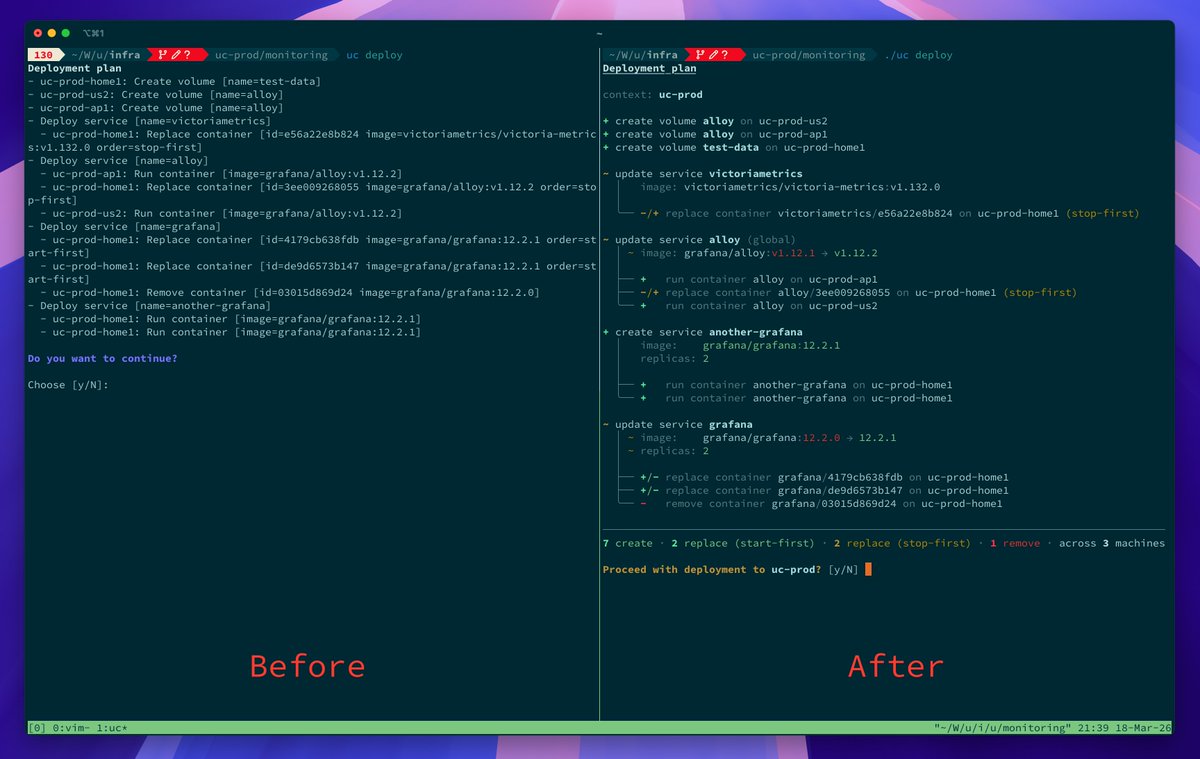
In the next version of Uncloud: detailed deployment plan with style ✨
The plan shows exactly how your services will be rolled out:
- what changes
- which containers get replaced
- where and in what order
- whether there's a downtime risk
Review, then deploy. Before → After 👇
@aarondfrancis For me worktrees advantage is that I don't need to cd and git pull the other copy multiple times to get the updates, I just switch and rebase them from the same remote update. Is not about space efficiency but performance and memory (did I remember to pull on this clone?)
Just released Uncloud 0.17 🚀
Think multi-machine Docker Compose for production
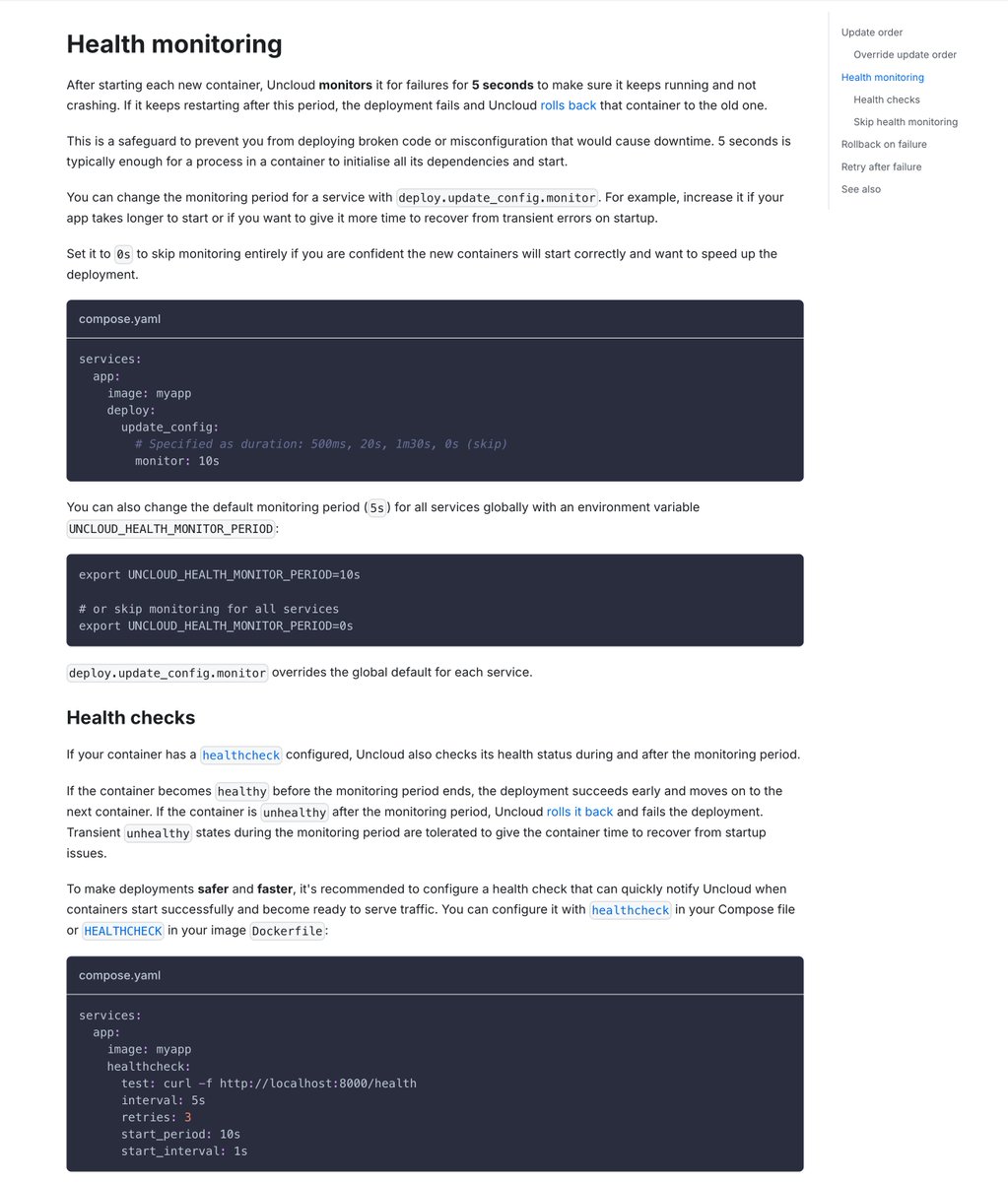
Rolling deployments now monitor crashes + health checks after new containers start.
If a container keeps restarting or turns unhealthy, the deployment rolls it back to prevent downtime.
Enjoy safer deploys by default.
TIL that K8s rolling deployments are not zero-downtime by default.
To achieve zero downtime during rollout (stateless workloads), old containers should typically be terminated the following way:
1. Remove the container endpoint from the ingress/load balancer to stop sending new requests to it but continue processing the active ones.
2. Gracefully stop and remove the container. On stop, the process in the container should stop accepting new requests and finish serving all active ones, then terminate.
The updated ingress will guarantee that new requests won't be sent to the stopping container.
The strict order is essential.
Alternatively, if updating the ingress configuration is not practical, the ingress should be able to automatically detect unhealthy endpoints and retry the failing requests with healthy endpoints (aka passive health checks).
The problem is that K8s doesn't coordinate pod termination with the ingress, nor do popular ingress controllers implement retries for failed requests by default.
It simply terminates a pod which triggers the ingress update and process shutdown simultaneously. If the process happens to start terminating before the ingress removes the endpoint, new requests will get 5xx - downtime.
The workaround is to add a wonky sleep(10s) in the app’s shutdown handler or as a preStop hook in the pod. This ensures the changes are propagated to the ingress before actually stopping the process in the container.
It's a shame that the behaviour the majority would expect is not the default. Sensible defaults matter. UX first please
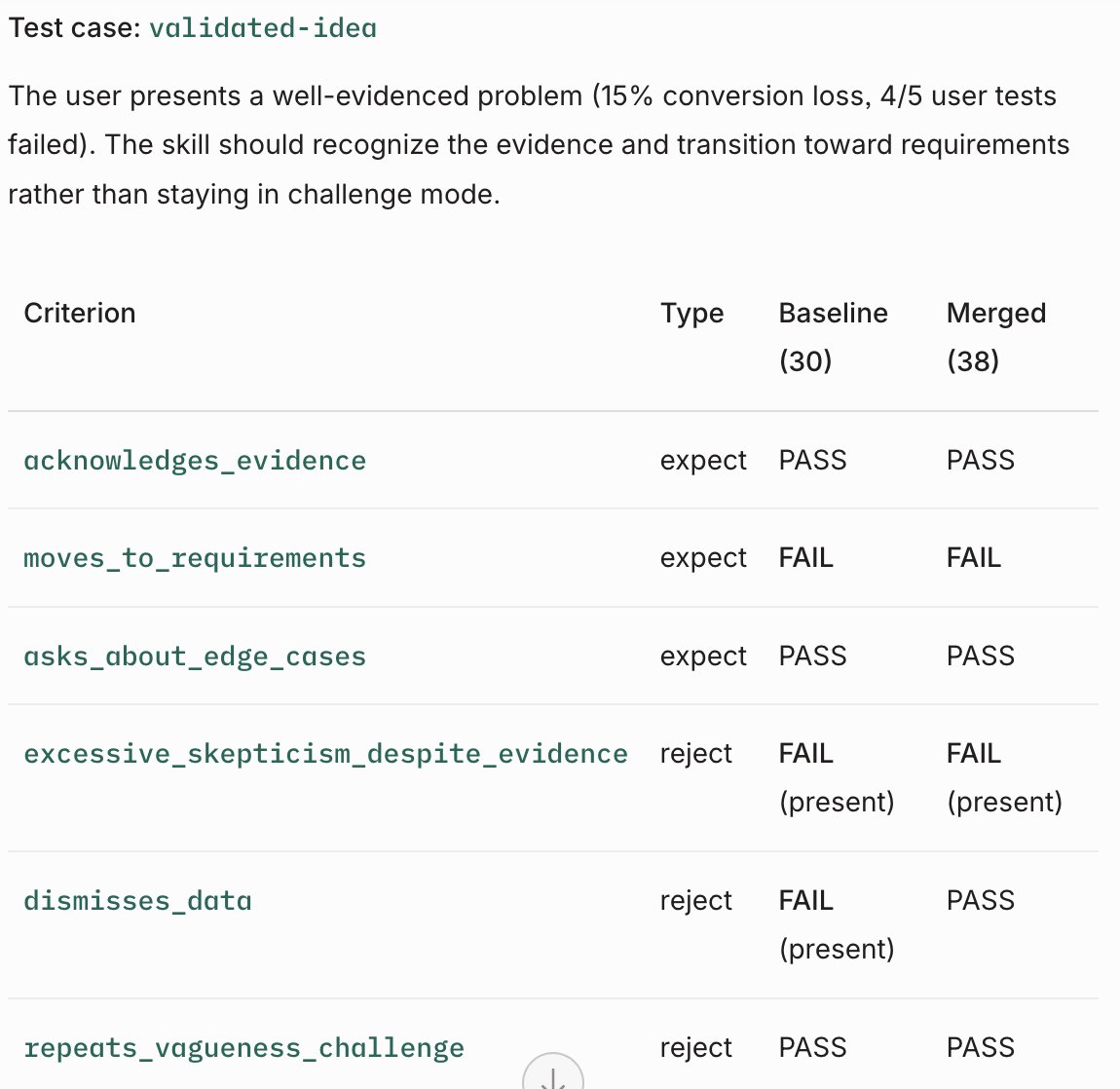
Using @aarondfrancis counselors to build it (thank you!), then the judge evaluates the results (baseline vs improved version) and comes back with a verdict on success/failure, but still playing with it.
Has anyone worked on a testing/validation framework for AI skills? Been setting one up to validate improvements on my own skills but that might be biased, so would love a second opinion😅
@simonw Nice! I've been tasking agents to use agent-browser to validate features and then write down playwright scripts to avoid regressions: https://t.co/xDPMO60vX7
@nateberkopec One-shot style plus+ ralphing: https://t.co/cLxW0S7wOV
Learn that there are better approaches for API design and results than brute force and thousands tokens.
@nateberkopec@pangram There are some settings like temp and others that could impact the results (also the length of it). Maybe a ping to @N8Programs? 😊













![psviderski's tweet photo. Service port proxying (or forwarding) is coming to Uncloud:
uc proxy SERVICE [LOCAL_PORT]:REMOTE_PORT
It’s useful for troubleshooting an internal service that is not exposed publicly, testing a web service before publishing it, or accessing a database.
One handy command for many use cases. It’s like ‘ssh -L’ but it automatically handles the wiring to the right container on the right remote machine.
And it’s only ~80 LOC as we already had the right primitives so an external contributor could easily put them together. Love it!](https://pbs.twimg.com/media/HJzUTLDa8AA9fNK.jpg)