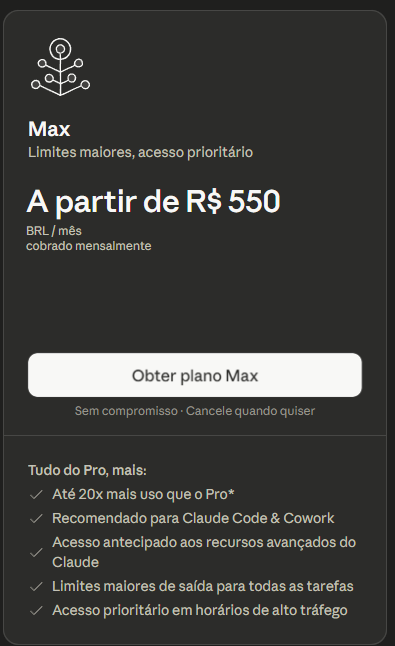
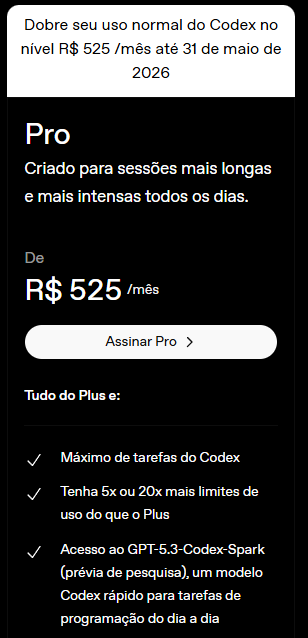
A-CA-BOU a taxa das blusinhas!
Compras internacionais até 50 dólares não são mais tributadas pelo Governo do Brasil. O imposto de importação acabou.
O Governo do Brasil tá do lado do povo brasileiro.
Qwen3.6 35B-A3B dropped yesterday, so I ran it on 4 GPUs to see how it performs:
🟣 RTX 3090 — 49.78 tok/s, TTFT 852ms
🟡 RTX 4090 — 118.93 tok/s, TTFT 686ms
🟢 RTX 5090 — 160.37 tok/s, TTFT 409ms
🔵 DGX Spark — 59.98 tok/s, TTFT 228ms
I went with ollama as the backend because honestly, it's the easiest way for most people to get started. One command, model pulled, done.
I used Q4_K_M (24GB) across all four cards. The reason is the 3090 and 4090 don't support NVFP4 (only the 5090 and DGX Spark could use it). Keeping the same quant everywhere felt like the fairest way to compare.
And yes, you can absolutely squeeze more performance out of every card with vLLM, SGLang, or TensorRT-LLM. But that's not what this test is about. This is just the out-of-the-box experience for folks who own a GPU and want to try the new model tonight.