Hello wonderful people!
I’m thrilled to announce that my new book, “Grokking Concurrency,” has officially hit the shelves!
You can find it here: https://t.co/TwSqRbNfJF
I could really use your support in spreading the word!
The rest of it
Joins that explode (broadcast, skew, bucket)
JDBC reads that are silently single-threaded
Spark 4.x defaults you probably haven't turned on yet
What to actually look at in the UI before you guess
A data engineer on Reddit got drunk and wrote down everything he learned in 10 years. The post lives on.
I agree with almost all of it. Preserved it here: https://t.co/xo5RgUbu0g
"How many unique users did X AND Y?" - simple question, brutal at scale.
Theta sketches solve it. But the gap between the algorithm and not getting burned in production is huge. Wrote the guide I wish existed: https://t.co/Ye4LTkOuGa
#dataengineering
The full sketch family:
- Theta/HLL → COUNT DISTINCT
- KLL/REQ → percentiles & distributions
- Frequent Items → heavy hitters
- Reservoir Sampling → representative samples
Each has sharp trade-offs. I break them all down in the full post:
https://t.co/QzAH5jjuCT
Your COUNT DISTINCT has been running for 3 hours. Your cluster is on fire.
Nobody tells you early on: exact answers to simple questions can be impossibly expensive at scale.
Data sketches fix this. Here's how 👇
#dataengineering
The real breakthrough: sketches are mergeable.
Build them in parallel on hundreds of machines. Merge in milliseconds. Handle late-arriving data by merging it in. Pre-compute at ingestion and store a 2KB "unique users" column instead of 2GB.
Built it in Vue + TypeScript. The irony of a data engineer building a frontend game is not lost on me.
More data eng stuff (the serious kind): https://t.co/KJgcxCGU3w
Built a tycoon game about data engineering. You start at the ground level. Goal: reach AGI before you go bankrupt.
Spoiler: the cash flow problem is just as real as in actual startups.
Free, browser, no signup: https://t.co/hnJXcxuPHB
My favorite design decision: if you hire AI researchers, Meta shows up after 60 seconds and takes half of them.
I didn't even need to make that part up.
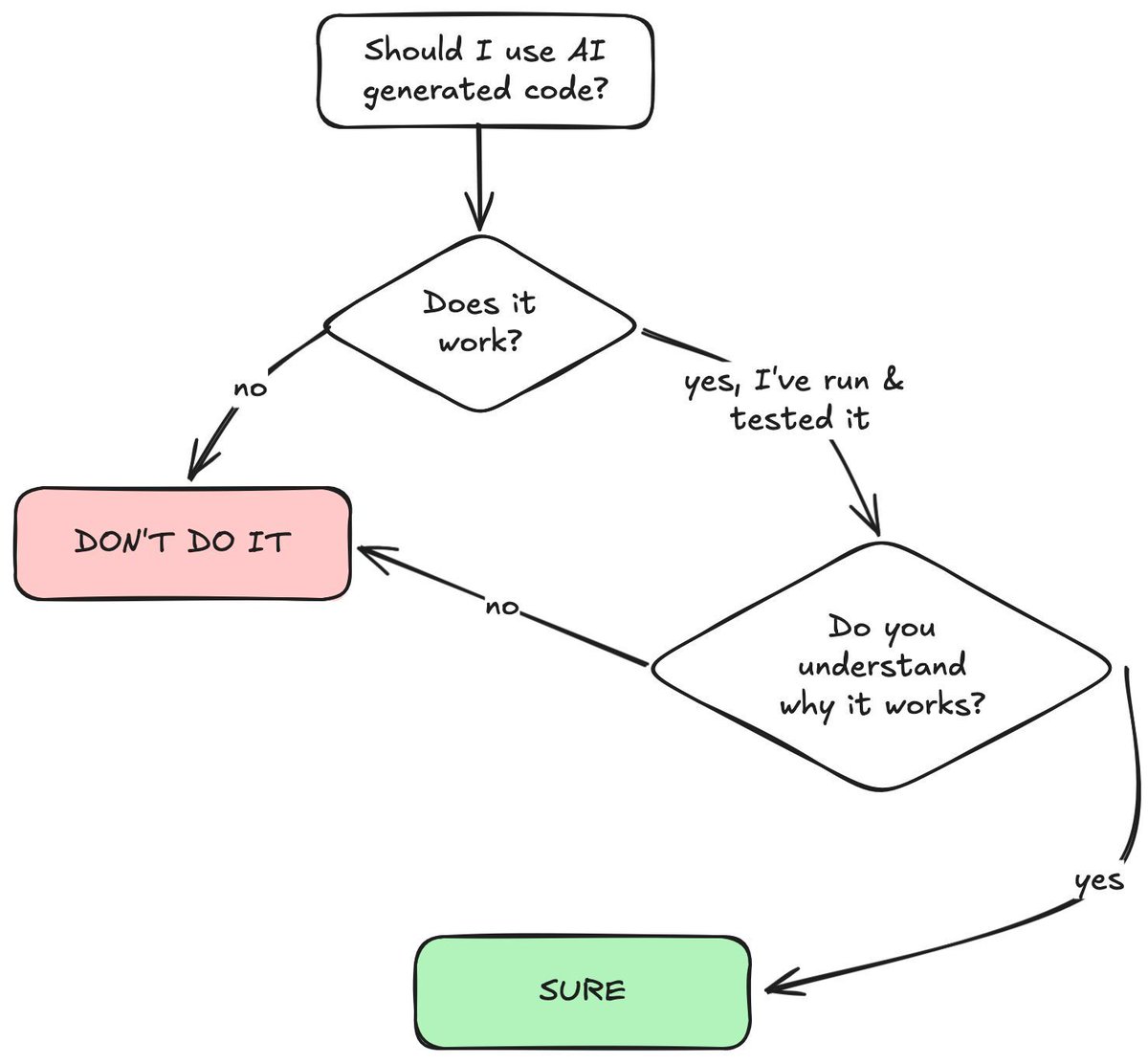
Made this for engineers who aren't sure if they're using AI correctly or just laundering their thinking.
Full rant on my Substack: https://t.co/RUVILA3N25
Spark is powerful. It scales. It's fast out of the box. And yeah, the defaults are surprisingly decent - until your dataset grows, your joins get messy, or you start mixing Scala with PySpark and Arrow and some eager ML engineer starts throwing 200MB Pandas UDFs at the cluster.