So happy to see our LongRoPE2 enabling 131k-token context for open dLLMs! 🚀
Great to be part of a work exploring how diffusion language models differ from autoregressive LLMs in long-context extension. 🙌
🔭 Towards Extending Open dLLMs to 131k Tokens
dLLMs behave differently from AutoRegressive models—they lack attention sinks, making long-context extension tricky.
A few simple tweaks go a long way!!
✍️blog https://t.co/Epf2y2Lnsk
💻code https://t.co/c04Cj5iT1y
Really great @Microsoft paper, rStar2-Agent. 👏
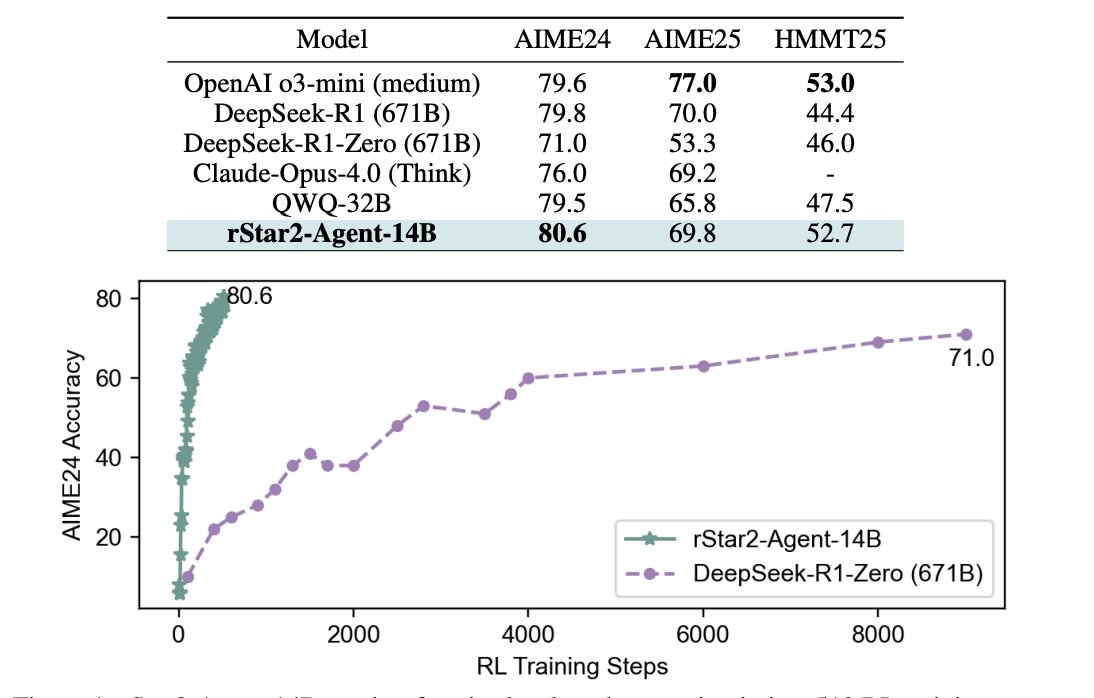
Trains a 14B model to reason with Python tools and beats much larger DeepSeek-R1 671B.
The trick is a simple rollout filter called GRPO‑RoC plus a fast code sandbox, so the model practices clean tool use and trims noisy traces.
It reaches frontier scores while staying shorter and cheaper to train.
80.6% on AIME24 with a 14B model, trained in 510 RL steps on 64 MI300X in 1 week.
🧵 Read on 👇
Grateful for @FrankYouChill insightful comments on our rStar2-Agent paper! It’s always inspiring to see such a deep understanding of the work. We hope our practice in agentic RL can inspire more research, and we look forward to further discussions with the community🚀🚀🚀.
A 14B model just beat a 671B model on math reasoning.
Here’s how Microsoft’s rStar2-Agent achieves frontier math performance in 1 week of RL training
- by “thinking smarter, not longer.” 🧵
We introduce rStar-Agent-14B🚀🚀🚀, a 14B model trained with large-scale agentic RL that matches DeepSeek-R1 (671B) on math reasoning. Welcome to check out our technical report, code and recipes! https://t.co/J27OlbsXN6
Microsoft presents rStar2-Agent
Agentic Reasoning Technical Report
rStar2-Agent boosts a pre-trained 14B model to state of the art in only 510 RL steps within one week, achieving average pass@1 scores of 80.6% on AIME24 and 69.8% on AIME25, surpassing DeepSeek-R1 (671B) with significantly shorter responses
Microsoft presents rStar2-Agent
Agentic Reasoning Technical Report
rStar2-Agent boosts a pre-trained 14B model to state of the art in only 510 RL steps within one week, achieving average pass@1 scores of 80.6% on AIME24 and 69.8% on AIME25, surpassing DeepSeek-R1 (671B) with significantly shorter responses
@teknium Hi, thanks for your interest! For SFT, we used both the sft_seed and synthetic_sft subsets, and included all available solutions (including both verified and unverified). Please refer to our paper (https://t.co/txkTvRcFua) for a detailed description of the training setup.
🚀Our rStar-Coder dataset is now released!
A verified dataset of 418K competition-level code problems, each with test cases of varying difficulty. On LiveCodeBench, it boosts Qwen2.5-14B from 23.3% → 62.5%, beating o3-mini (low) by +3.1%.
Try it here: https://t.co/4y50CBcJzi
Thanks @_akhaliq for the highlight!
LongRoPE2 solves the practical challenges when we apply LongRoPE to Phi-3, and now powers Phi-4 mini. We fixed short-context drop, and achieved effective 128k context length by redefining RoPE OOD boundaries and recalibrate scale factors.
Microsoft presents rStar-Math
Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
On the MATH benchmark, it improves Qwen2.5-Math-7B from 58.8% to 90.0% and Phi3-mini-3.8B from 41.4% to 86.4%, surpassing o1-preview by +4.5% and +0.9%. On the USA Math Olympiad (AIME), rStar-Math solves an average of 53.3% (8/15) of problems, ranking among the top 20% the brightest high school math students.
Microsoft presents rStar-Math
Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
On the MATH benchmark, it improves Qwen2.5-Math-7B from 58.8% to 90.0% and Phi3-mini-3.8B from 41.4% to 86.4%, surpassing o1-preview by +4.5% and +0.9%. On the USA Math Olympiad (AIME), rStar-Math solves an average of 53.3% (8/15) of problems, ranking among the top 20% the brightest high school math students.
Thank you for promoting our work @WenhuChen@_akhaliq ! We're happy to share our approach to test-time scaling and are excited to further explore its potential and generalize it to broader domains✨✨✨
We released phi 3.5: mini+MoE+vision
A better mini model with multilingual support: https://t.co/f7avhBXHYn
A new MoE model:https://t.co/FxLILAqpEr
A new vision model supporting multiple images: https://t.co/rMkkpFc4cx
Thank you for sharing our work! 🌟 rStar shows that through effective solution exploration and discrimination, SLMs like LLaMA2-7B can exhibit strong reasoning capabilities before domain-specific supervised fine-tuning. The only trade-off is the need for more inferences!
Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers
discuss: https://t.co/lCUjfUvxMf
This paper introduces rStar, a self-play mutual reasoning approach that significantly improves reasoning capabilities of small language models (SLMs) without fine-tuning or superior models. rStar decouples reasoning into a self-play mutual generation-discrimination process. First, a target SLM augments the Monte Carlo Tree Search (MCTS) with a rich set of human-like reasoning actions to construct higher quality reasoning trajectories. Next, another SLM, with capabilities similar to the target SLM, acts as a discriminator to verify each trajectory generated by the target SLM. The mutually agreed reasoning trajectories are considered mutual consistent, thus are more likely to be correct. Extensive experiments across five SLMs demonstrate rStar can effectively solve diverse reasoning problems, including GSM8K, GSM-Hard, MATH, SVAMP, and StrategyQA. Remarkably, rStar boosts GSM8K accuracy from 12.51% to 63.91% for LLaMA2-7B, from 36.46% to 81.88% for Mistral-7B, from 74.53% to 91.13% for LLaMA3-8B-Instruct.
LongRoPE is making it possible to extend language model context windows, including for the Microsoft Phi-3 family of SLMs, while maintaining performance. Learn about the work, featured at #ICML2024, with podcast guest and Senior Researcher Li Lyna Zhang. https://t.co/YrXsnfeHyY
LongRoPE is making it possible to extend language model context windows, including for the Microsoft Phi-3 family of SLMs, while maintaining performance. Learn about the work, featured at #ICML2024, with podcast guest and Senior Researcher Li Lyna Zhang. https://t.co/YrXsnfeHyY
Thanks for sharing! We are currently in the process of Microsoft open source review. Therefore, the paper’s code link is currently private. We’ll release the code and extended LLMs soon. Thanks for your patience.
Microsoft presents LongRoPE
Extending LLM Context Window Beyond 2 Million Tokens
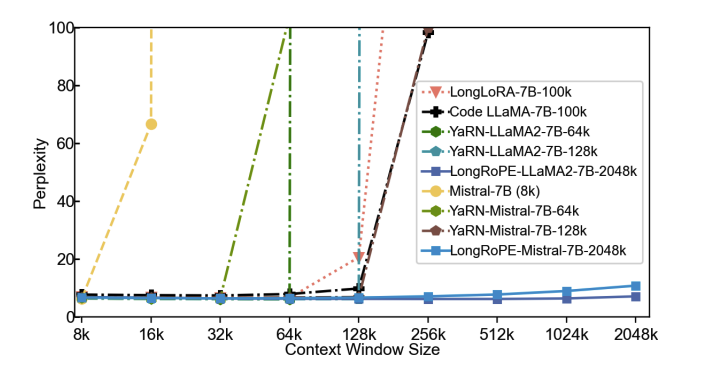
Large context window is a desirable feature in large language models (LLMs). However, due to high fine-tuning costs, scarcity of long texts, and catastrophic values introduced by new token positions, current extended context windows are limited to around 128k tokens. This paper introduces LongRoPE that, for the first time, extends the context window of pre-trained LLMs to an impressive 2048k tokens, with up to only 1k fine-tuning steps at within 256k training lengths, while maintaining performance at the original short context window. This is achieved by three key innovations: (i) we identify and exploit two forms of non-uniformities in positional interpolation through an efficient search, providing a better initialization for fine-tuning and enabling an 8x extension in non-fine-tuning scenarios; (ii) we introduce a progressive extension strategy that first fine-tunes a 256k length LLM and then conducts a second positional interpolation on the fine-tuned extended LLM to achieve a 2048k context window; (iii) we readjust LongRoPE on 8k length to recover the short context window performance. Extensive experiments on LLaMA2 and Mistral across various tasks demonstrate the effectiveness of our method. Models extended via LongRoPE retain the original architecture with minor modifications to the positional embedding, and can reuse most pre-existing optimizations.
Microsoft presents LongRoPE
Extending LLM Context Window Beyond 2 Million Tokens
Large context window is a desirable feature in large language models (LLMs). However, due to high fine-tuning costs, scarcity of long texts, and catastrophic values introduced by new token positions, current extended context windows are limited to around 128k tokens. This paper introduces LongRoPE that, for the first time, extends the context window of pre-trained LLMs to an impressive 2048k tokens, with up to only 1k fine-tuning steps at within 256k training lengths, while maintaining performance at the original short context window. This is achieved by three key innovations: (i) we identify and exploit two forms of non-uniformities in positional interpolation through an efficient search, providing a better initialization for fine-tuning and enabling an 8x extension in non-fine-tuning scenarios; (ii) we introduce a progressive extension strategy that first fine-tunes a 256k length LLM and then conducts a second positional interpolation on the fine-tuned extended LLM to achieve a 2048k context window; (iii) we readjust LongRoPE on 8k length to recover the short context window performance. Extensive experiments on LLaMA2 and Mistral across various tasks demonstrate the effectiveness of our method. Models extended via LongRoPE retain the original architecture with minor modifications to the positional embedding, and can reuse most pre-existing optimizations.