🔭 Towards Extending Open dLLMs to 131k Tokens
dLLMs behave differently from AutoRegressive models—they lack attention sinks, making long-context extension tricky.
A few simple tweaks go a long way!!
✍️blog https://t.co/Epf2y2Lnsk
💻code https://t.co/c04Cj5iT1y
Very excited to announce the v1.0 of SlopCodeBench release:
- Doubling the size of the dataset
- @harborframework support
- scb-check: a CLI that flags slop anti-patterns
- Way more model results
https://t.co/RQkB8wdzAu
https://t.co/36qQR3azeE
🧵
The growing KV-cache of attention is the key component for the long-context understanding of LLMs, but what holds back long-term memory modules (e.g., Titans)? What if we could have the compression power of Titans but with a growing memory similar to Transformers?
Memory Caching: A class of architectures that compress the context into a slow growing memory (not as fast as Transformers, but not as static as RNNs), resulting in recurrent neural networks with non-fixed-sized memory (hidden states). Building on this formulation, we present Sparse Selective Caching, an architecture with growing effective memory (similar to attention) but with almost constant inference cost per token (similar to RNNs).
We've been in GRPO-tweaking mode for months (entropy bonuses, clipping hacks, length penalties). But what if the entire objective is wrong?
Today, we're releasing LAD (Learning Advantage Distributions), the most elegant rethink of RL for LLM reasoning I've seen this year. #ACL2026
Here's the idea, how it works, and why we think it changes things. 🧵
The problem we kept hitting
GRPO, DAPO, RLOO, and many other variants do the same thing at their core: maximize expected reward. And when you do that, your policy can collapse onto a single dominant reasoning path. Entrop regularization can act as a bolt onto the framework, but it doesn't fundamentally fix it from the ground up.
The key insight
💡Stop maximizing. Start matching.
We reframe the policy update as a distribution matching problem. Instead of pushing toward the single best response, we make the policy's output distribution match the full advantage-weighted target distribution by minimizing an f-divergence between the two (see our theory in Section 3.1).
When you match the full advantage distribution, you naturally preserve probability mass across multiple valid reasoning paths. High-advantage responses get upweighted, yes, but the objective also suppresses overconfident probability growth on any single mode.
Collapse prevention isn't an afterthought.
What validated the theory
We tested six divergence families. The result that convinced us we were on the right track:
- Strict divergences (Total Variation, Hellinger, Jensen-Shannon) that enforce exact distributional matching consistently outperform weaker ones (such as KL).
- The more faithfully you learn the full advantage distribution, the better the reasoning. This is exactly what the framework predicts.
The results
- In a controlled bandit setting. LAD recovers multiple-mode advantage distributions (see plot below). GRPO fundamentally cannot. This is the clearest demonstration that the paradigm difference is real, not just theoretical
- In math and code reasoning tasks across multiple LLM backbones. LAD consistently outperforms GRPO on both accuracy AND generative diversity across benchmarks.
Why this matters beyond benchmarks
Pass@k scaling: If your model knows 5 valid reasoning paths instead of 1, sampling at inference becomes massively more effective.
Simplicity: Instead of stacking "GRPO + entropy hack," you get one principled objective. Diversity preservation comes by design.
Paper: https://t.co/Vs8TpzjiGH
Code is available; link in the paper.
Huge credit to my amazing student @Wendi_Li_, who drove this work, thinks boldly, and made things happen.
🎉 Super stoked to share that our work is accepted to the main conference of ACL 2026!!
See you in sunny San Diego 🌞
#ACL2026#NLProc
Paper thread below 🧵
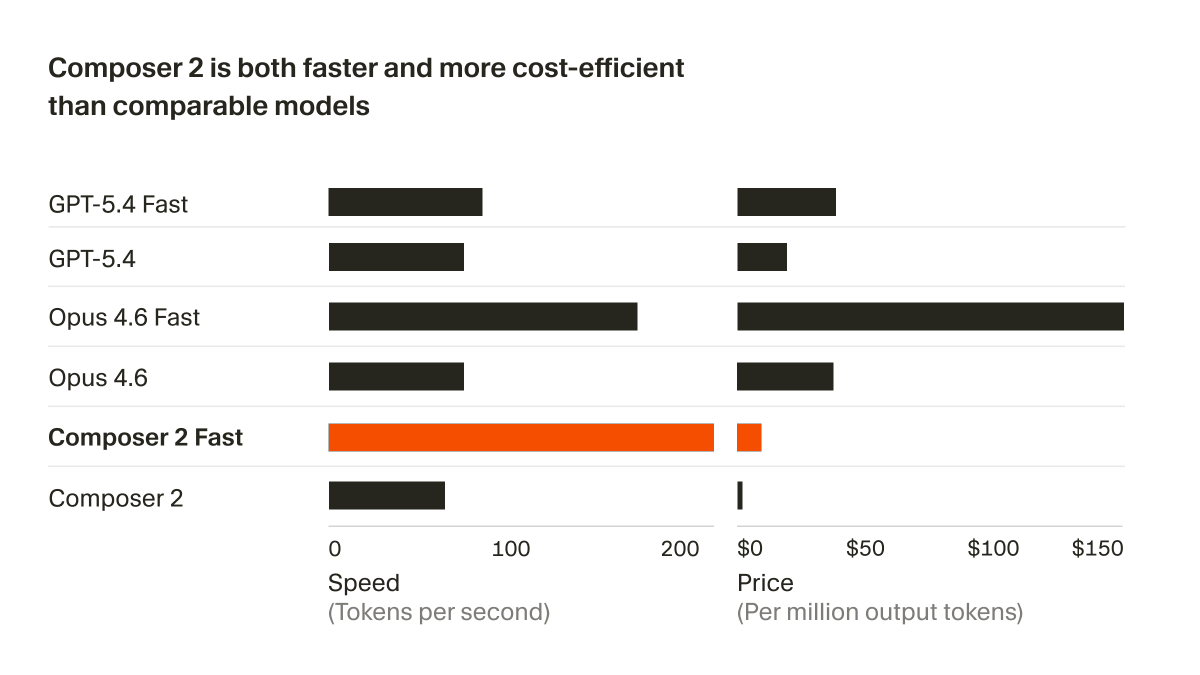
That new LFM2.5-350M is super overtrained, right? And everyone was shocked about how far they pushed it?
As it turns out, we have a brand new scaling law for that! 🧵
[1/n]
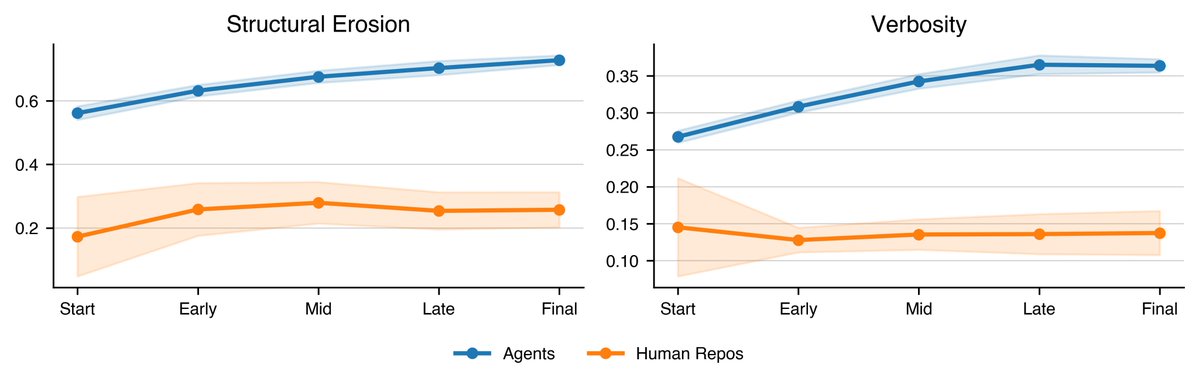
We found that agents generate progressively worse code with each iteration. Real developers do not.
SlopCodeBench is the only eval that faithfully measures quality degradation on iterative, long-horizon coding tasks.
https://t.co/JXGHC4w0bv
https://t.co/RQkB8wdzAu
🧵
Hi ML Twitter!
My Summer 2026 internship unfortunately fell through last minute 😵💫
If your team is looking for interns, I’d love to connect - RTs appreciated 🙏
My website: https://t.co/rNih6t6Emb
Personal AI should run on your personal devices. So, we built OpenJarvis: a personal AI that lives, learns, and works on-device.
Try it today and top the OpenJarvis Leaderboard for a chance to win a Mac Mini!
Collab w/ @Avanika15, John Hennessy, @HazyResearch, and @Azaliamirh. Details in thread.
Scaling expert-annotated image captions is expensive. Supervised distillation from VLMs helps but has a diversity ceiling: models memorize the teacher's style and generalize poorly. Can RL fix this without a verifiable "ground truth"?
Introducing RubiCap: https://t.co/wRnZcIm4xf
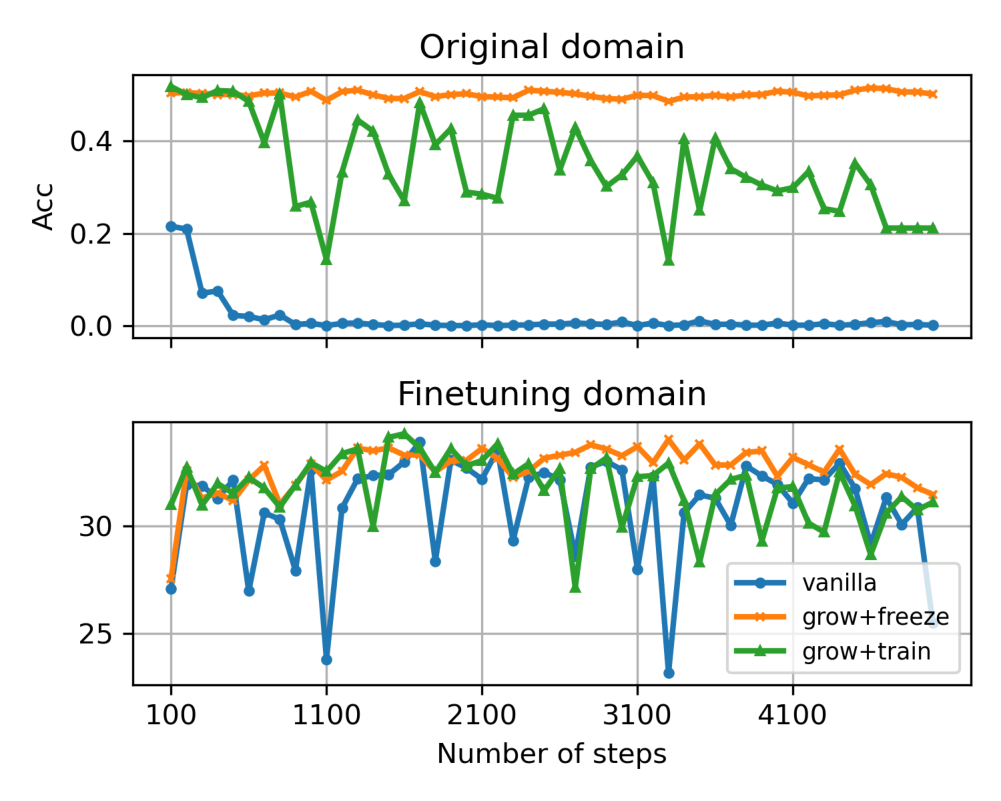
🌟 Psyched to finally share our paper from my internship w/ Google Research last summer: "Grow, Don't Overwrite: Fine-tuning Without Forgetting"
A very simple method that matches full fine-tuning on new tasks with almost zero forgetting.
📄https://t.co/XeoxSBoJOY
🧵 below
One of the biggest promises of Diffusion LLMs is parallel generation: predicting multiple tokens at once to bypass the sequential bottleneck of autoregressive models.
However, parallel generation comes with a price. For example:
Should the sentence “He is from [MASK] [MASK]” be filled with [New] [York] or [San] [Diego]?
If a diffusion model predicts both at the exact same time, it assumes independence and may produce... [San] [York]. 🤦♂️
We argue this arises from a structural misspecification: models are restricted to fully factorized outputs because parameterizing the full joint distribution would require a prohibitively massive output head.
This is the Factorization Barrier crippling parallel generation. Here is how we broke it with CoDD.

































![nick11roberts's tweet photo. That new LFM2.5-350M is super overtrained, right? And everyone was shocked about how far they pushed it?
As it turns out, we have a brand new scaling law for that! 🧵
[1/n] https://t.co/vj2CZ2GNoE](https://pbs.twimg.com/media/HFOWCzBW8AAr8bY.jpg)



![IanLi1118's tweet photo. One of the biggest promises of Diffusion LLMs is parallel generation: predicting multiple tokens at once to bypass the sequential bottleneck of autoregressive models.
However, parallel generation comes with a price. For example:
Should the sentence “He is from [MASK] [MASK]” be filled with [New] [York] or [San] [Diego]?
If a diffusion model predicts both at the exact same time, it assumes independence and may produce... [San] [York]. 🤦♂️
We argue this arises from a structural misspecification: models are restricted to fully factorized outputs because parameterizing the full joint distribution would require a prohibitively massive output head.
This is the Factorization Barrier crippling parallel generation. Here is how we broke it with CoDD.](https://pbs.twimg.com/media/HCi1OlrbEAA9BAi.jpg)




















