NEW paper from Microsoft Research.
(bookmark it)
The entire interpretability literature is built around human readers. As more analysis gets delegated to agents, the right target of interpretability shifts. This paper is a recipe for designing tools that agents can actually reason about.
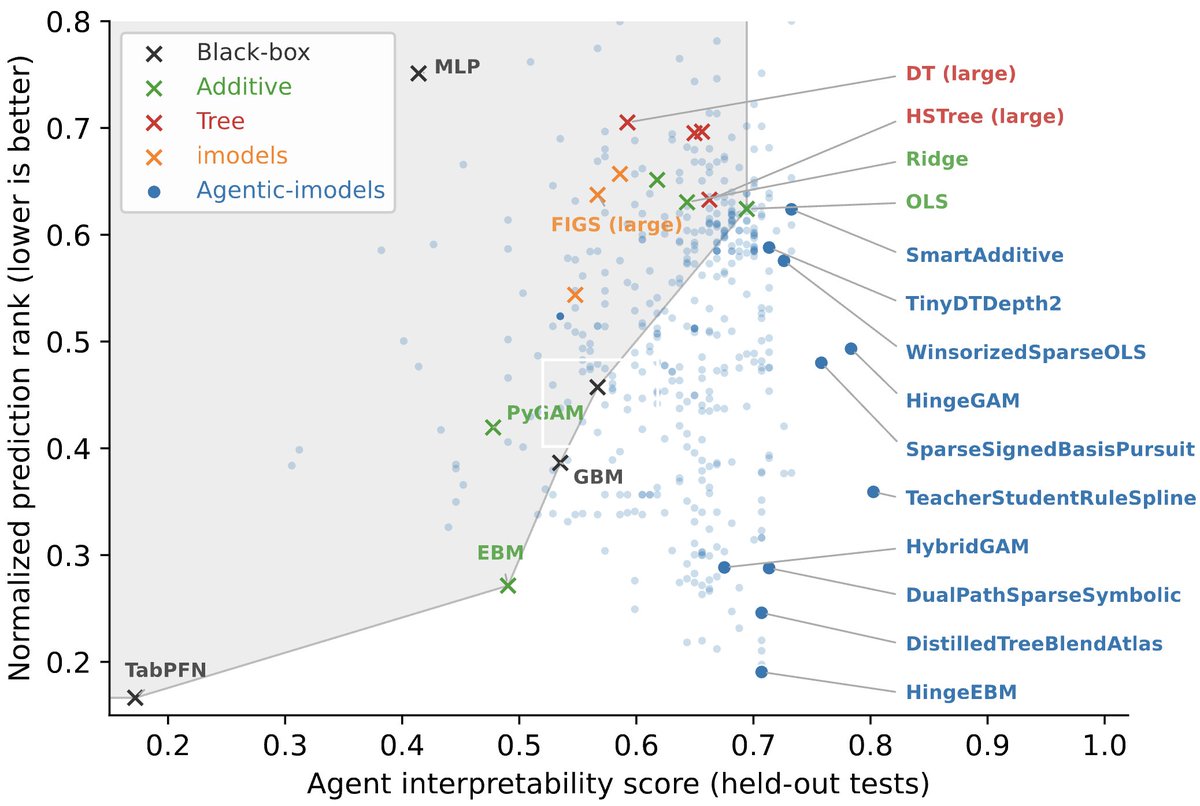
They introduce Agentic-imodels, an autoresearch loop where a coding agent (Claude Code, Codex) iteratively evolves scikit-learn-compatible regressors that are simultaneously accurate AND readable by other LLMs.
Interpretability is measured by whether a small LLM can simulate the fitted model's behavior just by reading its string representation. Predictions, feature effects, counterfactuals, all from the __str__ output alone.
Run on 65 tabular datasets, the discovered models push the Pareto frontier past every classical interpretable baseline (decision trees, GAMs, sparse linear), and improve four downstream agentic data science systems on the BLADE benchmark by 8% to 73%.
Paper: https://t.co/rgMdEz5XEj
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
🚀 Launching ProgramAsWeights (PAW)!
Define functions in English → PAW compiles them into tiny neural programs → Run locally like normal Python functions.
A neural program combines discrete text + continuous LoRA to adapt a fixed small interpreter.
🔗 https://t.co/N6ISkMYP3P
NEW paper from Microsoft Research.
(bookmark it)
The entire interpretability literature is built around human readers. As more analysis gets delegated to agents, the right target of interpretability shifts. This paper is a recipe for designing tools that agents can actually reason about.
They introduce Agentic-imodels, an autoresearch loop where a coding agent (Claude Code, Codex) iteratively evolves scikit-learn-compatible regressors that are simultaneously accurate AND readable by other LLMs.
Interpretability is measured by whether a small LLM can simulate the fitted model's behavior just by reading its string representation. Predictions, feature effects, counterfactuals, all from the __str__ output alone.
Run on 65 tabular datasets, the discovered models push the Pareto frontier past every classical interpretable baseline (decision trees, GAMs, sparse linear), and improve four downstream agentic data science systems on the BLADE benchmark by 8% to 73%.
Paper: https://t.co/rgMdEz5XEj
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
NEW paper from Microsoft Research.
(bookmark it)
The entire interpretability literature is built around human readers. As more analysis gets delegated to agents, the right target of interpretability shifts. This paper is a recipe for designing tools that agents can actually reason about.
They introduce Agentic-imodels, an autoresearch loop where a coding agent (Claude Code, Codex) iteratively evolves scikit-learn-compatible regressors that are simultaneously accurate AND readable by other LLMs.
Interpretability is measured by whether a small LLM can simulate the fitted model's behavior just by reading its string representation. Predictions, feature effects, counterfactuals, all from the __str__ output alone.
Run on 65 tabular datasets, the discovered models push the Pareto frontier past every classical interpretable baseline (decision trees, GAMs, sparse linear), and improve four downstream agentic data science systems on the BLADE benchmark by 8% to 73%.
Paper: https://t.co/rgMdEz5XEj
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
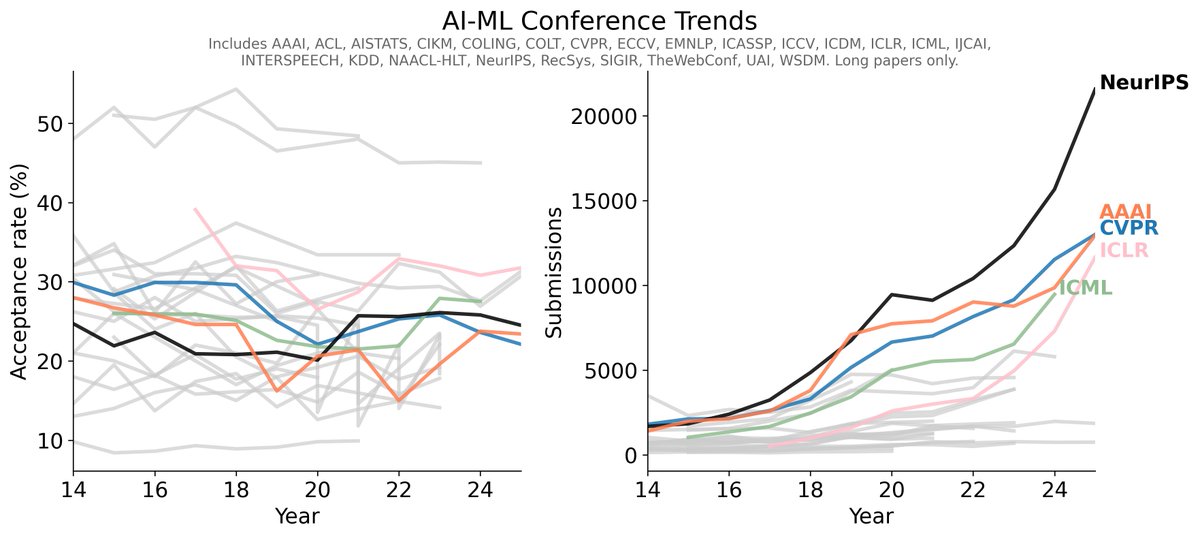
As ML conferences explode, one mitigation I'd like to see seriously considered is a cap on each author's yearly submissions (e.g. 3 total across NeurIPS, ICML, ICLR). Spamming low-quality submissions should have a real cost
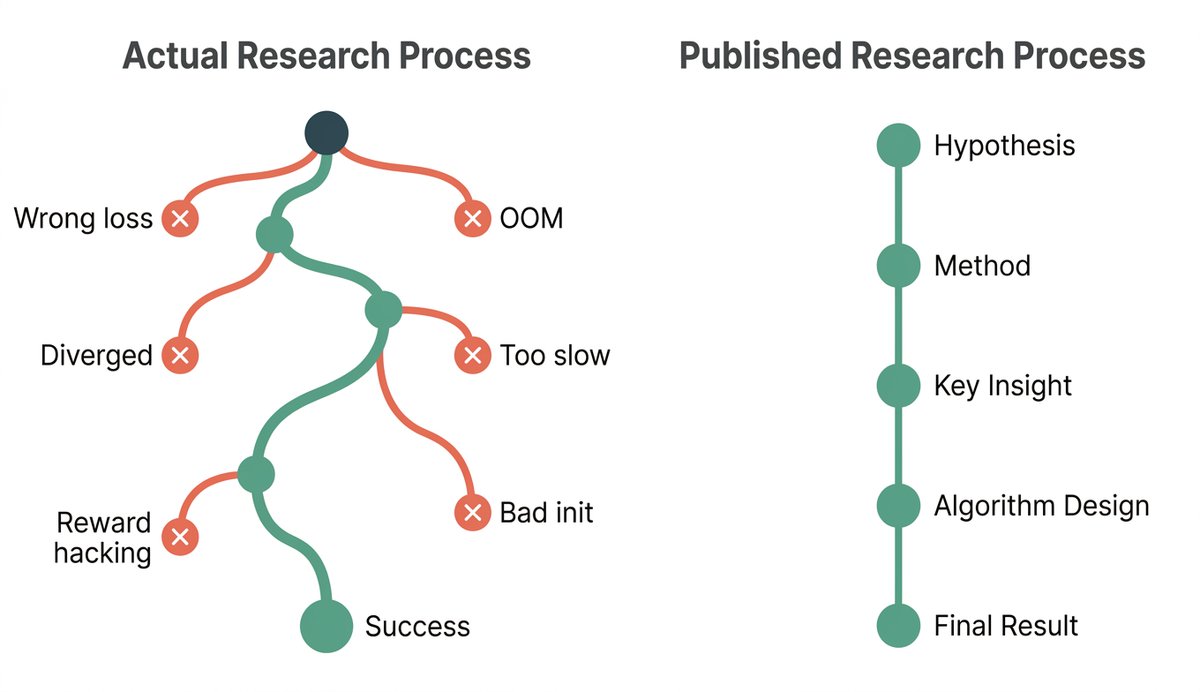
1/ For nearly 350 years, science has communicated itself through one object: the paper. A linear narrative, frozen as a PDF, written for a human reader. We've come to treat that format as the medium of science itself.
It doesn't have to be. It's a historical artifact. 🧵
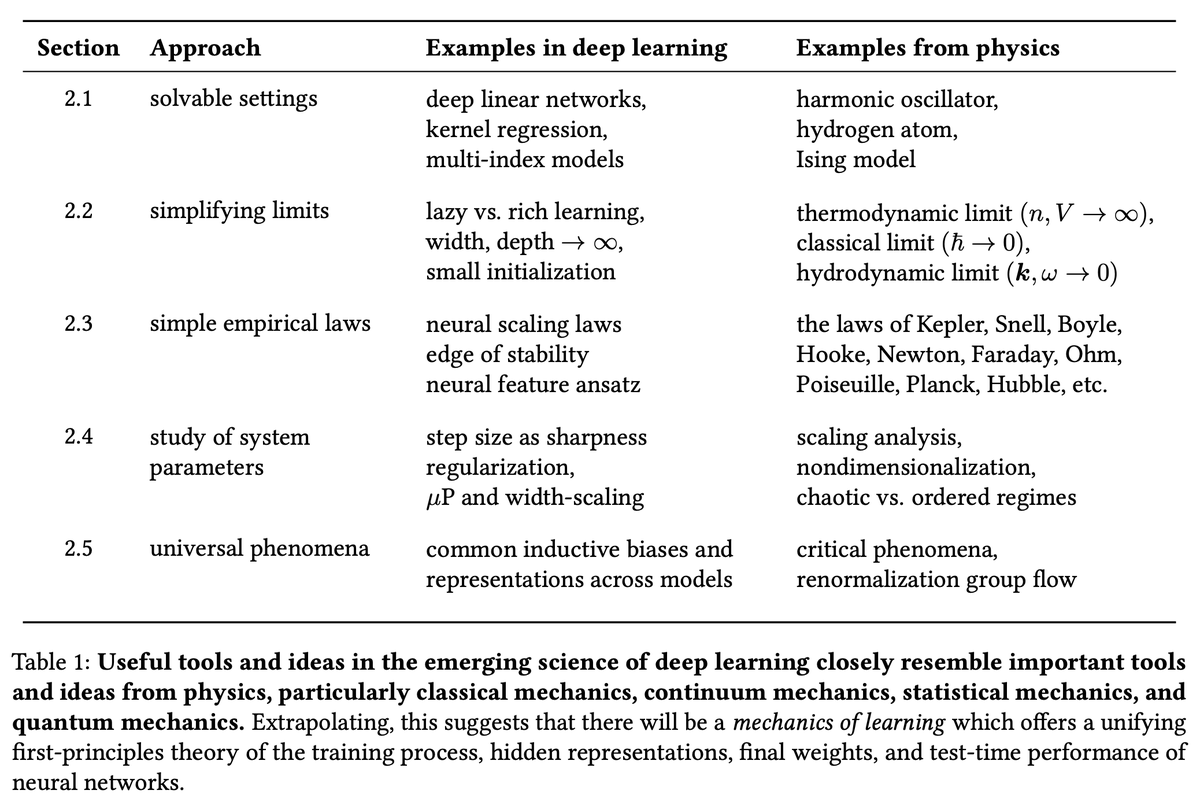
1/ Deep learning is going to have a scientific theory. We can see the pieces starting to come together, and it's looking a lot like physics!
We're releasing a paper pulling together these emerging threads and giving them a name: learning mechanics.
🔨 https://t.co/92nSIHameW 🔧
Check out our autointerp paper ✨Semantic Regexes ✨at ICLR on Friday April 24!
@MIT_CSAIL and @Apple with @donghaoren, @tafsiri, @domoritz, @arvindsatya1 & @fredhohman
📅 https://t.co/ZOth9TihQO
📄 https://t.co/xm0FyP2yJB
🖥️ https://t.co/NGwt3usysh
🔗 https://t.co/qXhFwqtHo9
Imagine every pixel on your screen, streamed live directly from a model. No HTML, no layout engine, no code. Just exactly what you want to see.
@eddiejiao_obj, @drewocarr and I built a prototype to see how this could actually work, and set out to make it real. We're calling it Flipbook. (1/5)
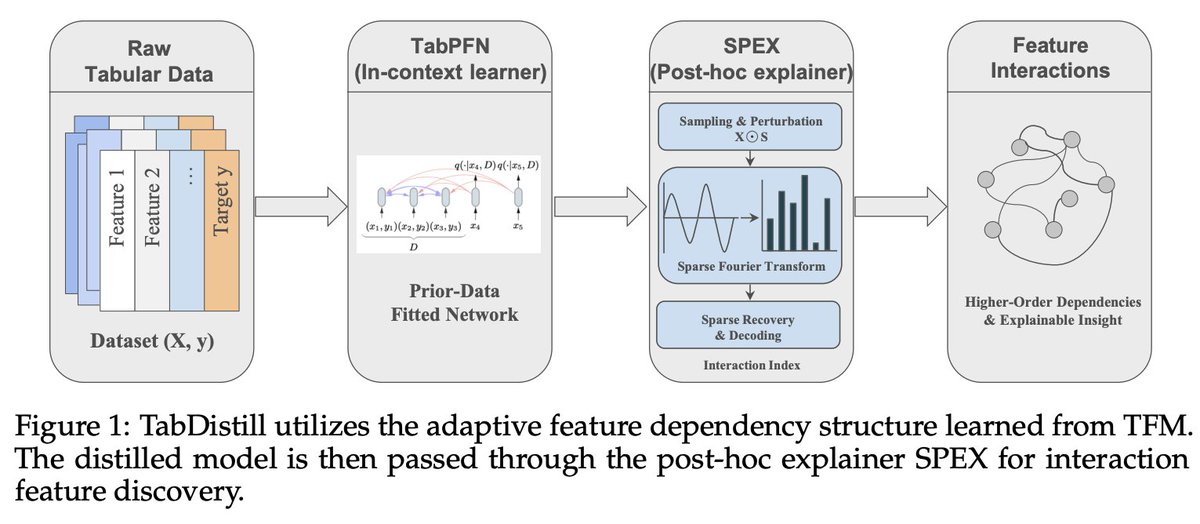
🎉 New on Arxiv:
A fundamental challenge of statistical learning is discovering which features interact with one another to influence outcomes. Looking for pairwise intx. requires O(n^2) calculations, three-way intx. requires O(n^3), etc.
Can we skip this statistical challenge by tapping into the rich prior learned in foundation models?
Our approach TabDistill shows that we can.
Read more:
https://t.co/IwlouoFzkd
10 GitHub repos to spend 60-90% less tokens in Claude Code:
1. RTK (Rust Token Killer)
CLI proxy that filters terminal output before it hits your context
- 60-90% reduction on common dev commands
- one binary, zero dependencies
- works with Claude Code, Cursor, Copilot
Repo: https://t.co/WayvpBtyBH
2. Context Mode
Sandboxes raw tool output into SQLite instead of dumping it into context
- 98% context reduction on Playwright, GitHub, logs
- only clean summaries enter your conversation
- works as Claude Code plugin
Repo: https://t.co/YNbFIGQz7X
3. code-review-graph
Local knowledge graph that maps your codebase with Tree-sitter
- Claude reads only what matters, not the entire repo
- 49x token reduction on large monorepos
- 6.8x on average reviews
Repo: https://t.co/9gIzmAWN12
4. Token Savior
MCP server that navigates code by symbols, not full files
- 97% reduction on code navigation
- persistent memory across sessions
- 69 tools, zero external deps
Repo: https://t.co/OtvhrMgGWh
5. Caveman Claude
makes Claude talk like a caveman to cut output tokens
- 65-75% output reduction
- one-line install
- keeps full technical accuracy
Repo: https://t.co/onBeghTyfH
6. claude-token-efficient
one CLAUDE.md file that keeps responses terse
- drop-in, no code changes
- reduces output verbosity on heavy workflows
- best for output-heavy sessions
Repo: https://t.co/j6MKo9klQe
7. token-optimizer-mcp
MCP server with caching, compression, and smart tool intelligence
- 95%+ token reduction through intelligent caching
- compresses repeated tool outputs
Repo: https://t.co/0jIVQ4ANls
8. claude-token-optimizer
reusable setup prompts for optimizing any project
- 90% token savings in 5 minutes
- reduces doc token usage from 11K to 1.3K
Repo: https://t.co/puil9WwFGB
9. token-optimizer
finds ghost tokens that silently eat your context
- survives compaction without losing quality
- fixes context quality decay
Repo: https://t.co/92G8e4yeGq
10. claude-context (by Zilliz)
code search MCP that makes your entire codebase the context
- ~40% reduction with equivalent retrieval quality
- hybrid BM25 + dense vector search
Repo: https://t.co/yjfiQOSy15
[ how to stack them ]:
you don't need all 10. pick 2-3 based on your workflow:
> heavy terminal output? RTK
> big codebase? code-review-graph + Token Savior
> lots of MCP servers? Context Mode
> quick fix? Caveman + claude-token-efficient
most people are burning tokens without knowing it
run /context in a fresh session and see how much is gone before you even type a word
your pocket will thank me later :<)
Interpretability methods usually study single-token behavior.
But real model behaviors, like sycophancy or writing style, are diffuse across many tokens.
Can these diffuse behaviors be localized and controlled from long-form responses? YES!
Can we rewrite Transformers as a human-readable code?
In this paper, we decompile Transformers trained on algorithmic and formal language tasks into D-RASP – a programming language that mirrors Transformer architecture. 🧵
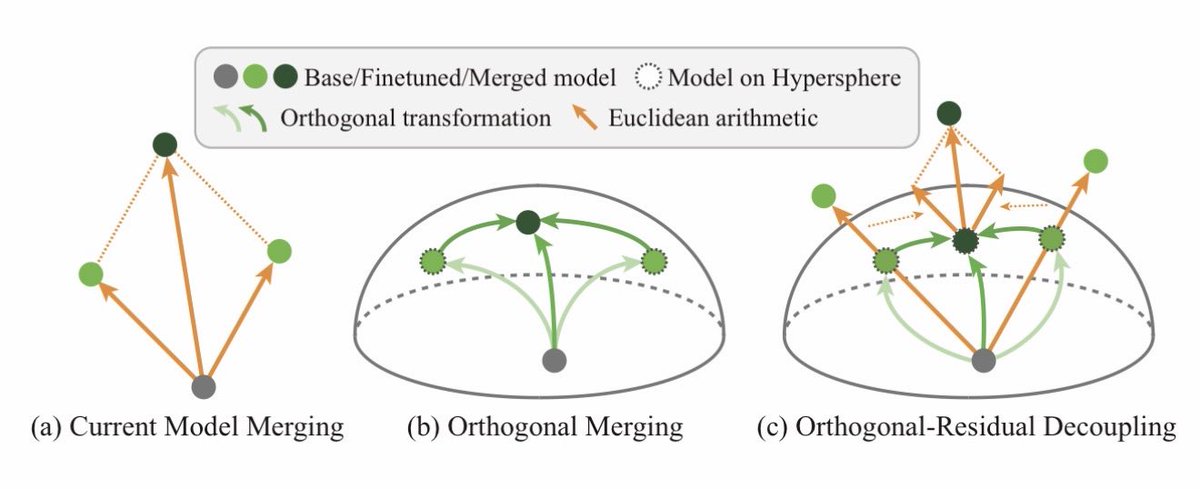
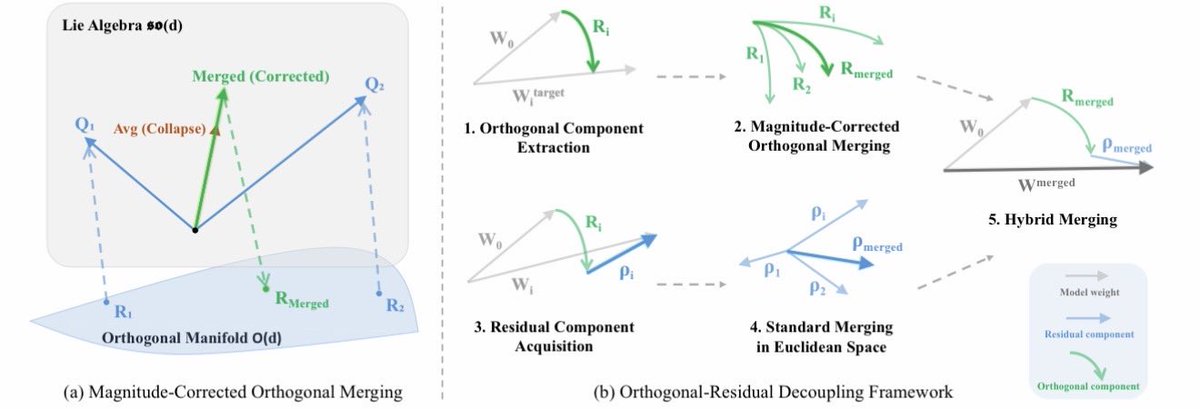
Orthogonal Finetuning (https://t.co/IlBYlgiaae; https://t.co/Mve4Pdptmv) has a unique advantage of preventing catastrophic forgetting. Inspired by this property, we find that merging models within the orthogonal group can effectively reduce model conflicts and preserve both pretraining and downstream knowledge. This is our OrthoMerge framework.
The idea behind OrthoMerge is extremely simple. For OFT-tuned models, we can first map the orthogonal adapters to Lie algebra with inverse Carley transform and then perform merging there. This guarantees the merged model differs from the pretrained model only up to an orthogonal transformation.
A better news is that OrthoMerge can also be applied to non-OFT-tuned models. By solving the orthogonal procrustes problem, we can have the projected component of the adapter onto the orthogonal group. OrthoMerge will then be applied there and the residual component can be merged using conventional merging methods. That said, OrthoMerge can be used together with existing model merging methods!
This is a great example of simple yet effective ideas. Great efforts by my PhD students Sihan Yang and Kexuan Shi. The project is already open-sourced and feel free to give it a try!
Project: https://t.co/Fzjrn0zpaW
Paper: https://t.co/QvFafN1UeY
Code: https://t.co/LjEzcLZ0De




















![DeRonin_'s tweet photo. 10 GitHub repos to spend 60-90% less tokens in Claude Code:
1. RTK (Rust Token Killer)
CLI proxy that filters terminal output before it hits your context
- 60-90% reduction on common dev commands
- one binary, zero dependencies
- works with Claude Code, Cursor, Copilot
Repo: https://t.co/WayvpBtyBH
2. Context Mode
Sandboxes raw tool output into SQLite instead of dumping it into context
- 98% context reduction on Playwright, GitHub, logs
- only clean summaries enter your conversation
- works as Claude Code plugin
Repo: https://t.co/YNbFIGQz7X
3. code-review-graph
Local knowledge graph that maps your codebase with Tree-sitter
- Claude reads only what matters, not the entire repo
- 49x token reduction on large monorepos
- 6.8x on average reviews
Repo: https://t.co/9gIzmAWN12
4. Token Savior
MCP server that navigates code by symbols, not full files
- 97% reduction on code navigation
- persistent memory across sessions
- 69 tools, zero external deps
Repo: https://t.co/OtvhrMgGWh
5. Caveman Claude
makes Claude talk like a caveman to cut output tokens
- 65-75% output reduction
- one-line install
- keeps full technical accuracy
Repo: https://t.co/onBeghTyfH
6. claude-token-efficient
one CLAUDE.md file that keeps responses terse
- drop-in, no code changes
- reduces output verbosity on heavy workflows
- best for output-heavy sessions
Repo: https://t.co/j6MKo9klQe
7. token-optimizer-mcp
MCP server with caching, compression, and smart tool intelligence
- 95%+ token reduction through intelligent caching
- compresses repeated tool outputs
Repo: https://t.co/0jIVQ4ANls
8. claude-token-optimizer
reusable setup prompts for optimizing any project
- 90% token savings in 5 minutes
- reduces doc token usage from 11K to 1.3K
Repo: https://t.co/puil9WwFGB
9. token-optimizer
finds ghost tokens that silently eat your context
- survives compaction without losing quality
- fixes context quality decay
Repo: https://t.co/92G8e4yeGq
10. claude-context (by Zilliz)
code search MCP that makes your entire codebase the context
- ~40% reduction with equivalent retrieval quality
- hybrid BM25 + dense vector search
Repo: https://t.co/yjfiQOSy15
[ how to stack them ]:
you don't need all 10. pick 2-3 based on your workflow:
> heavy terminal output? RTK
> big codebase? code-review-graph + Token Savior
> lots of MCP servers? Context Mode
> quick fix? Caveman + claude-token-efficient
most people are burning tokens without knowing it
run /context in a fresh session and see how much is gone before you even type a word
your pocket will thank me later :<)](https://pbs.twimg.com/media/HGLKx_ybYAAZ58B.jpg)