Virtual cells are supposed to help drug discovery. Why aren't they evaluated on drug discovery tasks? In our new preprint "Cell-Level Virtual Screening," we investigate this and other fundamental questions about practical applications of virtual cells for drug discovery.
Computer systems have long been developed to consider adaptive memory problems (e.g. cache invalidation, hierarchical storage, speculative reuse, routing, and scheduling). Some people say "Hashing and caching is 50% of computer science."
As generative models scale, many of these same problems are starting to reappear inside the generative models.
Two new papers from our group, both led by Dong Liu, explore this idea through adaptive caching and memory management:
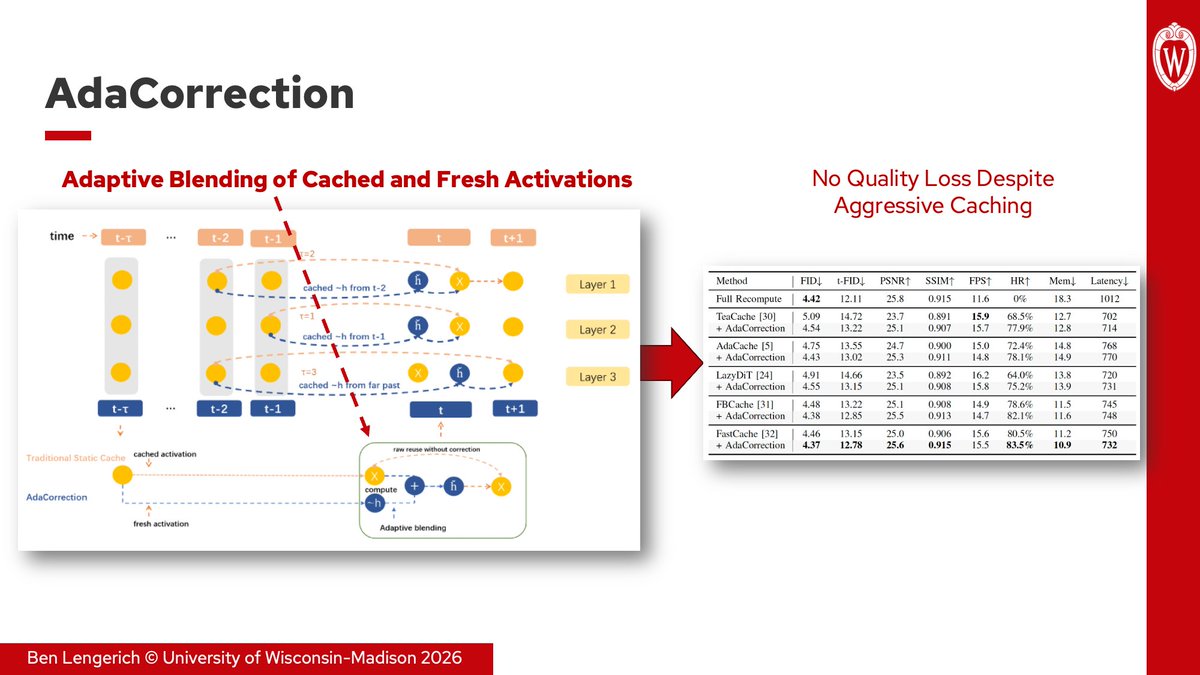
1. AdaCorrection (ICIP 2026, https://t.co/T3UikwZ81H) measures activation drift during diffusion inference and adaptively blends cached and fresh features instead of relying on static reuse schedules. Combined with FastCache, AdaCorrection reduces memory by 40% and latency by 30% without any loss to FID.
2. Memory-Keyed Attention (Computing Frontiers 2026, https://t.co/VenSWKsehY) organizes KV memory into local, session, and long-term tiers, then learns per-token routing across them. It achieves up to 5× faster training and 1.8× lower decode latency vs. MLA with comparable perplexity.
These build on our earlier PiKV work (ICML ES-FoMO 2025, https://t.co/UGsjQ00opE), which explored adaptive KV cache management for MoE serving.
Common thread across all three: reuse policies cannot remain static as models scale. Efficient generative systems increasingly require adaptive decisions about what to reuse, when to refresh, and what memory should be attended to for a given token or timestep.
I'm excited to help organize the Midwest Machine Learning Symposium (MMLS) 2026, which will happen at Purdue University this summer!
📍 West Lafayette, IN
📅 June 24–25, 2026
📌 *Poster submission deadline: May 24*
🔗 https://t.co/XNOcoBGbCu
We have a great lineup of plenary speakers: Tong Zhang (UIUC), Jennifer Neville (Purdue), Mohit Bansal (UNC), and Joyce Chai (Umich).
🎉 New on Arxiv:
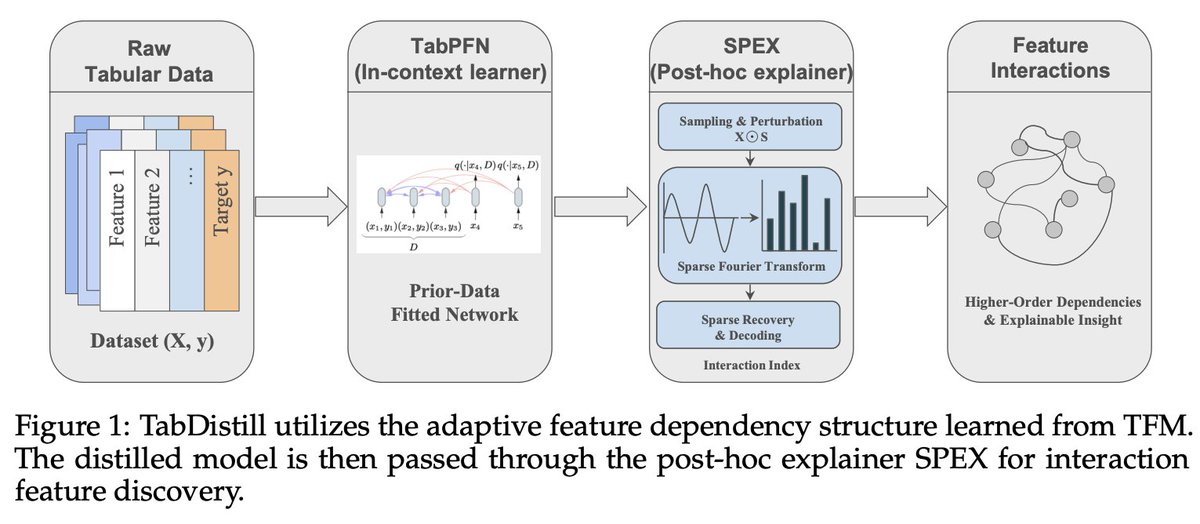
A fundamental challenge of statistical learning is discovering which features interact with one another to influence outcomes. Looking for pairwise intx. requires O(n^2) calculations, three-way intx. requires O(n^3), etc.
Can we skip this statistical challenge by tapping into the rich prior learned in foundation models?
Our approach TabDistill shows that we can.
Read more:
https://t.co/IwlouoFzkd
Out now in @npjDigitalMed “The Hidden Risk of Round Numbers and Sharp Thresholds in Clinical Practice”
tl;dr: sometimes the highest-risk patients are not those at extreme biological risk, but rather those *just below the threshold for treatment*.
https://t.co/APWGqxabZN
Recently, we used https://t.co/ohybt5ts9W to go beyond physical limits in biology and medicine, inferring n-of-1 models for 7997 of patients and generating models of unseen diseases on-demand. This hints at how to develop accurate and personalized biological simulators like AIDO.
At #ICML long context (#lcfm) tomorrow, we’ll present “Memory-Keyed Attention”(MKA), which asks:
How can we cut the cost of long context attention?
Our answer: use a learned hierarchy of memory to focus attention where it matters.
Read the paper: https://t.co/bm1HY4GRed
Had fun talking with Arseniy on "Tomorrow’s Medicine". We got into foundation models, anomaly detection, and the tradeoffs between personalization and generalization in healthcare AI.
Here's the YT link: https://t.co/jUt6QQu62M
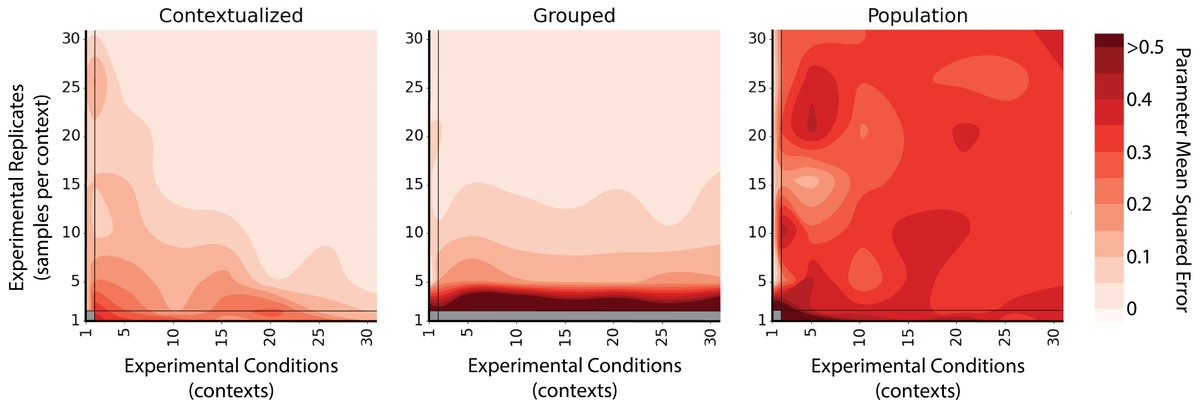
If you're interested in using or developing contextualized models, reach out to myself or @ben_lengerich. Ben just started his new lab at UW Madison focusing on language as context and LLMs, and I'm working on multi-modal bio contexts and bio FMs with @genbioai.
Honored to share a major thread of my PhD research, out now in PNAS. We address a core issue with how models are used for scientific discovery.
Models are so important that they define the entire scientific process... 1/n
Enjoyed this conversation about AI in medicine—grateful for the chance to share ideas about how understanding AI systems can help us build better, more effective healthcare tools.
Struggling to keep up with the rapidly-changing world of efficient foundation models and inference strategies? Our review covers the latest in quantization, distillation, pruning, and system co-design: https://t.co/ipPKIv7RPv
with updating repo of refs: https://t.co/H2J8Udl4kh
🚀I’m excited to share that we’re launching OpenContext, a new Slack group growing out of the ContextualizedML project! What started as a simple open-source repo (led by @probablybots) has blossomed into a community of developers and researchers united by an interest in context-adaptive statistical modeling. DM me or @probablybots for an invite to the Slack group.
Our first initiative is an open, collaborative review paper on Context-Adaptive Inference. This paper will offer a perspective on some timely questions in statistical learning like how foundation models can be used as context. We're looking to include insights from across disciplines, so please join us. If you’re interested in contributing or just staying updated, get involved directly on Github:
https://t.co/5R2e1TIxWZ