Check out our 2 papers at the poster session #ICLR2025 from 10am today!
UniDetox: Universal Detoxification of Large Language Models via Dataset Distillation
https://t.co/TkjDgGqtOA
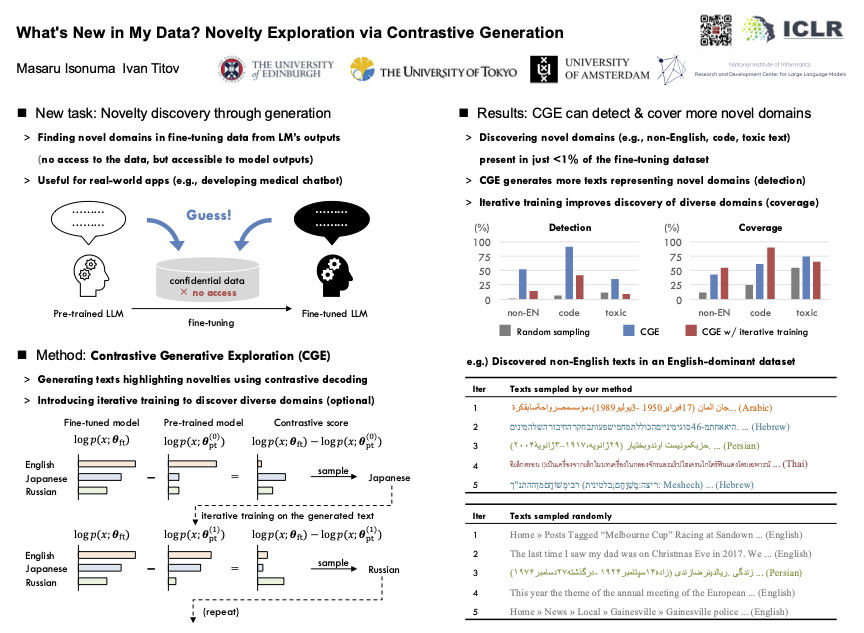
What's New in My Data? Novelty Exploration via Contrastive Generation
https://t.co/981ZRycVbk
Our paper has been accepted as a spotlight in the position paper track at #ICML2026
We argue that post-hoc opt-outs of copyrighted material from trained models (e.g., unlearning, guardrails) cannot legally cure infringement.
https://t.co/PjfJpkbnhr
Our paper has been accepted as a spotlight in the position paper track at #ICML2026
We argue that post-hoc opt-outs of copyrighted material from trained models (e.g., unlearning, guardrails) cannot legally cure infringement.
https://t.co/PjfJpkbnhr
Our two workshop proposals, LIMIT and FOUND, have been accepted for #ICCV2025 / @ICCVConference !! If you’ll be in Hawaii for the conference, we’d love for you to join us at our workshops 😎
# See the following threads
Distilling the corpus is challenging as SGD-based bi-level optimization is generally not applicable to textual data.
Instead of SGD, we use contrastive decoding for distillation, avoiding the need for bi-level optimization.
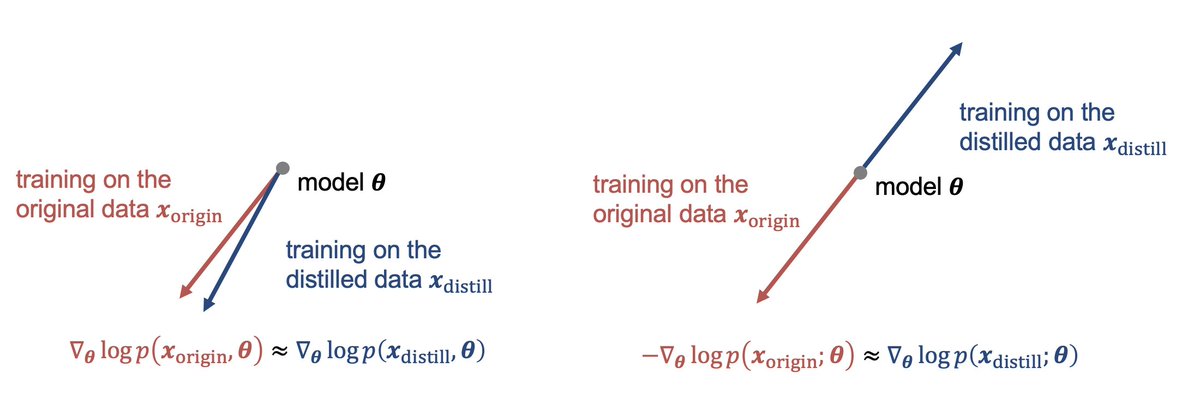
This work proposes "reverse dataset distillation," which creates data that induces gradients opposite to those of the original dataset.
By training a model on this distilled data, the model unlearns the original dataset without significant performance degradation. #ICLR2025
#ICLR#ICLR2025
Tomorrow! Apr 26th🚨
Come check out our poster at #273 from 10:30 am to 12:30 pm!
TLDR; Dataset distillation normally compresses data by matching model gradients. We reversed it: creating data that have opposite gradients and makes models unlearn toxicities.
New paper: "What's New in My Data? Novelty Exploration via Contrastive Generation," w/ @iatitov at @EdinburghNLP
https://t.co/vXghE4StN1
With no access to the data, but only access to the pre-trained and fine-tuned model, we can reveal novel aspects of the fine-tuning dataset.
Check out our 2 papers at the poster session #ICLR2025 from 10am today!
UniDetox: Universal Detoxification of Large Language Models via Dataset Distillation
https://t.co/TkjDgGqtOA
What's New in My Data? Novelty Exploration via Contrastive Generation
https://t.co/981ZRycVbk
#ICLR#ICLR2025
Tomorrow! Apr 26th🚨
Come check out our poster at #273 from 10:30 am to 12:30 pm!
TLDR; Dataset distillation normally compresses data by matching model gradients. We reversed it: creating data that have opposite gradients and makes models unlearn toxicities.
I left Edinburgh and joined the National Institute for Informatics R&D Center for LLMs and the Tohoku Univ. Center for language AI research. I’m so grateful to @iatitov for hosting me in his group across two years. I learned a lot from him, resulting in fruitful research work.
I left Edinburgh and joined the National Institute for Informatics R&D Center for LLMs and the Tohoku Univ. Center for language AI research. I’m so grateful to @iatitov for hosting me in his group across two years. I learned a lot from him, resulting in fruitful research work.