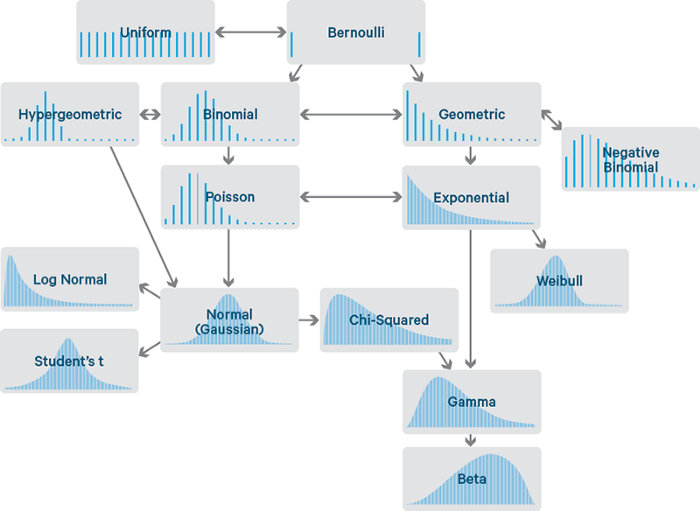
Ну всё, сдаюсь (( Мне нужен Opus Claude AI из РФ. Никак не могу получить доступ. Номер для смс-авторизации никак не подходит. И как это побороть? Может есть какие-то волшебные симки?
Instead of watching Netflix this weekend, watch this 2-hour Stanford lecture on AI careers.
It will teach you more about winning in the AI race than all the AI content you have scrolled past this year combined.
Stanford just released a 1.5-hour lecture on “LLM Architecture.”
This is the exact thing systems engineers at Anthropic and OpenAI require to understand at a deep level.
Give it some time.
This might be the highest-ROI learning you do this month.
Делюсь одним сайтиком который лежит на черный день у меня для поиска работы.
Все вакансии для айтишника в одном месте с разными фильтрами.
📲 https://t.co/rHBUYmZ6nn
Claude Code стоит 200 долларов в месяц. GitHub Copilot стоит 19 долларов в месяц.
Компания Джека Дорси опубликовала в открытом доступе бесплатную альтернативу, имеющую 35 000 звезд на GitHub.
Его зовут Гусь.
- Работает с любым LLM — Claude, GPT, Gemini, Llama, DeepSeek
- Читает и редактирует весь ваш код.
- Выполняет команды оболочки и устанавливает зависимости.
- Автоматически выполняет и отлаживает код.
- Настольный, интерфейс командной строки и веб-интерфейс
— Написано на Rust. Без лишних функций.
Block — это компания с оборотом в 40 миллиардов долларов. Они создали её для своих инженеров, а затем раздали всем остальным.
📷Срочная новость от 1 апреля*. Шторм выбросил на берег Анапы морской контейнер с грузом айфонов и других гаджетов примерно на МИЛЛИАРД рублей. Владелец неизвестен, а народ уже изучает содержимое. По закону моря — кто успел, тот и «спасатель».
*Не забываем какой сегодня день.
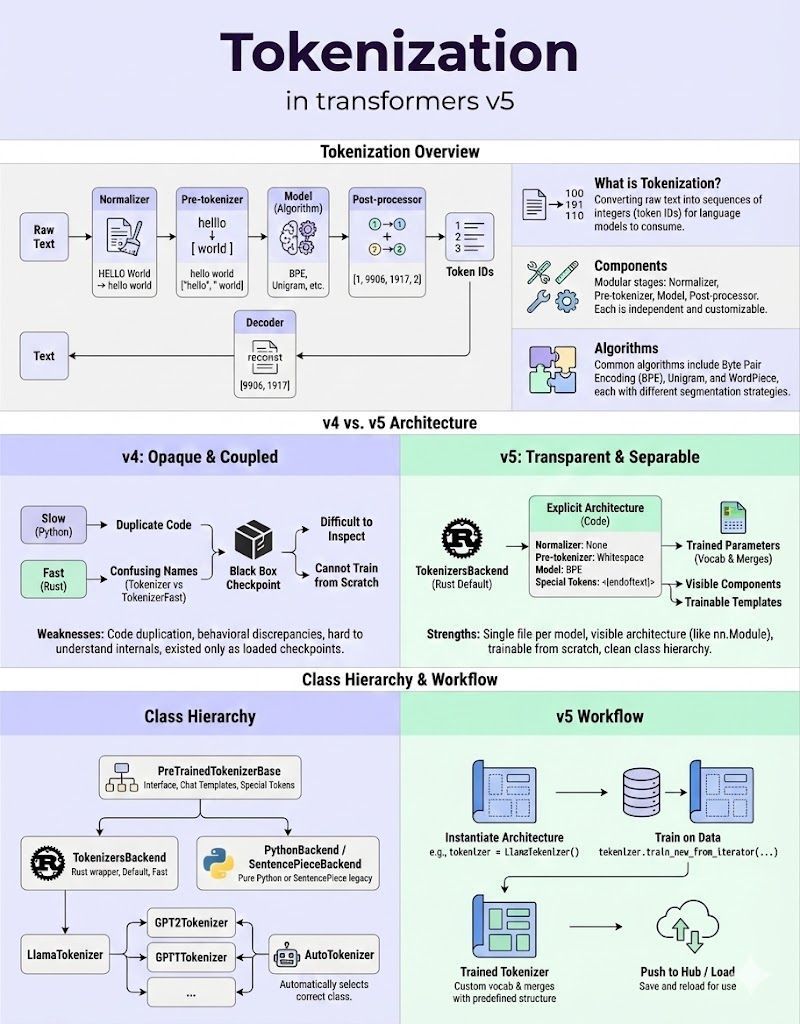
Tokenization is changing.
It has been the part of the stack nobody cared about until models started eating tons of text for breakfast.
Tokenization is the step that turns raw text into token IDs so a model can actually do math on it, deciding whether “Steve job's daughter btw” becomes two chunks, three chunks, or ten.
A “good” tokenizer squeezes your text into as few tokens as possible while still being reversible, which means more usable context for the same compute and fewer weird edge cases when you decode back.
In earlier transformer versions this whole process was basically a black box: slow Python vs fast Rust code paths, duplicated implementations, and checkpoint files that hid everything about how text was actually split. You often couldn’t answer simple questions like “Is this BPE or Unigram?” or “What does the normalizer do?” without spelunking through configs. Training a LLaMA‑style tokenizer on your own corpus meant re‑implementing half the pipeline by hand.
With the v5 release of Transformers v5 we have got proper, inspectable, debuggable architectures. You define the pipeline explicitly - normalizer, pre‑tokenizer, model (BPE/Unigram/WordPiece), post‑processor, decoder - and then load or train vocab + merges on top, similar to defining a neural net before loading weights. That means you can start from a blank llama tokenizer, feed in your own domain data, and get a custom tokenizer that behaves like LLaMA but speaks “legal”, “medical”, or “logs” fluently.
The library also cleans up the class hierarchy and workflow: one main Rust‑backed tokenizers backend instead of parallel slow/fast paths, a clear base class with chat templates and special‑token handling, and a straightforward loop of
“instantiate architecture → train on data → push to Hub / reuse.”
this removes a ton of subtle bugs around padding, truncation, and BOS/EOS handling, and makes it far easier to reason about why a model saw a particular sequence of IDs.
The result is that tokenization stops being an afterthought and becomes a real design lever. Teams that actually understand and customize their tokenizers will quietly win on context length, stability, and domain fit, while everyone else keeps losing quality in the first milliseconds of the pipeline - before a single attention head even wakes up.