Satya’s point about AI ecosystems is directionally right, but for enterprises the missing piece is the harness.
The real challenge isn’t just connecting a model to a workflow. It’s giving that workflow safe access to infrastructure, policy, telemetry, and enforcement so it can actually run in production and improve over time.
That’s how I think about @Cisco Cloud Control: a secure harness for infrastructure that helps enterprises build loops safely.
Not just agents that can act, but governed systems that can observe, decide, execute, and learn without losing control.
Notes on the recent session we had related to autonomous long-running coding agents.
(bookmark it)
Topics: /goal, loop engineering, verifiers, dynamic workflows, and much more.
So much to unpack, so I tried to quickly summarize the most relevant parts using my writer agent.
Karpathy said something you'll regret ignoring:
"Remove yourself as the bottleneck. Maximize your leverage. Put in very few tokens, and a huge amount of stuff happens on your behalf."
Loop engineering is the exact thing that does that.
In a hand-run session, the operator handles two things:
- deciding what the agent runs next
- and checking its output before the next step
Both are manual, and both decide how far the agent gets on its own without the operator.
Loop engineering moves both steps into the system.
A core operating structure surrounds the loop, and the diagram below depicts it.
- A schedule decides what to run
- Loop is the maker that produces the work
- A separate checker agent grades the output
- A file on disk holds the state they both read.
The loop runs until either done, max iterations, or an exhausted budget.
Here are some practical engineering considerations:
1) A model grading its own output justifies what it already did instead of catching where it failed.
That's why a separate checker's findings return to the maker as the next instruction. And the cycle repeats until the checker finds nothing left to fix.
2) A loop with no stop condition burns tokens, and the cost climbs fast once sub-agents and long runs add up.
That's why the exit must be set before the loop runs, not while it is running.
A simple exit could be:
↳ fix only the major issues, run one final pass, and stop after two loops, with "all tests pass and lint clean" as the rule that ends it.
3) State has to live on disk, not in context.
The model forgets everything between runs, so an MD file or a knowledge graph holds what is done and what is still open.
Each run reads it and writes back to it, which lets a loop pick up again after days.
4) The lower the verification bar, the safer the loop.
Boring, repetitive checks like a stale version string or a missing test are trivial to verify, so a loop runs them with little risk while the operator is away.
Judgment-heavy work is loopable too, but only as far as the checker can confirm the result.
Let's look at how an unattended loop fails in two ways.
1) It reports done when nothing is actually verified.
The separate checker exists to prevent it, but it merges code faster than anyone reads it, so over weeks, the team stops understanding its own codebase while every check stays green.
Green tests say the code passed the tests, not that anyone knows what shipped. Someone still has to read what the loop merges.
2) The checker keeps a running loop honest, but it only catches failures inside a run.
The harness around the loop, like the prompts, tools, and checks wrapped around the model, still drifts and breaks in production as models change.
That repair loop is usually run by hand based on observability traces.
My co-founder wrote a detailed walkthrough (with code) on making that harness repair itself, where a failing trace gets diagnosed, the fix is verified against the exact input that failed, and the failure is locked as a regression test so it cannot recur.
Read it below.
Watch Cisco Cloud Control in action.
Discover the unified platform built for humans and AI agents to run critical IT infrastructure together, enabling customers and partners to build their own apps and agents in natural language, and extending to third-party tools.
Salesforce published a detailed writeup on going agentic with Claude Code. A couple things jumped out.
A migration they'd scoped at 231 days shipped in 13. One PR delivered 21 endpoints at 100% test coverage.
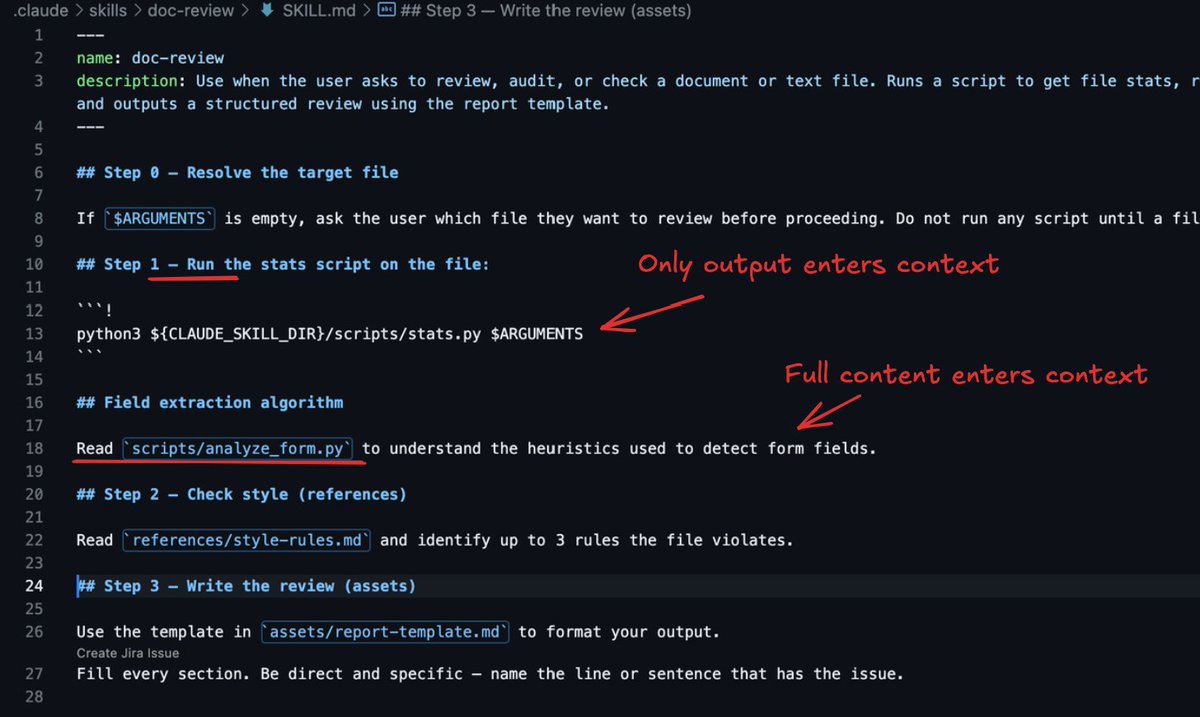
IMPORTANT!
In Skills, Run vs Read makes a huge difference in how your script consumes tokens
How you call a script inside your Skill matters, the verb decides whether Claude executes the code or reads it as context
In this case:
- Step 1 uses "Run" with an executable code block, the script runs in bash, the file never enters the context window, only the stdout from https://t.co/tXpH87lpLk does
- The "Field extraction algorithm" section uses "Read" pointing at analyze_form.py, Claude opens the file and loads the full source into context, same as any reference markdown
Same script, same location, completely different cost
If you want deterministic code execution without paying tokens for large script files, you need to be deliberate with this.
"Run" for execution, "Read" or "See" only when the code itself is the documentation
Most utility scripts in a Skill should be Run, not Read!
Andrej Karpathy just explained the future of software engineering without directly saying it.
The best AI engineers are no longer “prompting.”
They’re building systems around the agents.
Karpathy’s biggest insight wasn’t:
“Claude can code.”
It was:
LLMs become dramatically better when you force them into disciplined workflows.
That’s why "CLAUDE.md" files are suddenly everywhere.
Not because they’re prompts.
Because they behave like an operating system for the agent.
Karpathy called out the exact problems with AI coding:
- models assume instead of asking
- they overengineer simple tasks
- they hide confusion
- they rewrite unrelated code
- they optimize for completion, not correctness
So developers started encoding rules directly into the workflow:
→ Think before coding
→ Simplicity first
→ Surgical edits only
→ Goal-driven execution
And the results are wild.
People are now running multiple Claude Code agents in parallel like engineering teams:
• one agent researching
• one debugging
• one writing tests
• one optimizing code
• one validating outputs
Not “AI assistance.”
Actual orchestration.
And this part from Karpathy changes everything:
“Don’t tell the model what to do. Give it success criteria and let it loop.”
That is the shift.
From:
“write this function”
To:
“here’s the goal, constraints, tests, and verification system — now iterate until correct.”
The craziest part?
This already feels like a phase shift in engineering.
A lot of developers quietly went from:
80% manual coding → to 80% agent-driven coding in just months.
Not because AI became perfect.
Because the leverage became impossible to ignore.
We’re entering an era where the highest leverage engineers won’t necessarily be the best coders.
They’ll be the people who build the best systems around AI agents.
@_sholtodouglas@trq212 You asked for it 🤓Though i love the spirit 🫡
sharing my critical concerns!
1. Subagehts -super slow in handoff and back merger
2. Better control over concurrent tool execution by agent (currently it is instruct and hope)
Codex /goal builds it.
Claude Code /goal review and refines it.
Hermes /goal manages the orchestration and handoff.
All tracked on a single Kanban Board and agents keep running in the loop.