Exciting news: I am announcing my campaign for Ward 2 City Council! With 20 years of supporting our public schools, advancing climate resilience, and advocating for responsive government—I am ready to bring my energy to City Hall. Get involved at: https://t.co/COWyKi8l8E
Happy Thanksgiving, Xitter!
And because I can't get enough of DevOps & InfoSec, have a look at my article about the importance of culture in a DevOps to DevSecOps transformation
https://t.co/fJTts2st6a
#devOps#devSecOps#InformationSecurity#infoSec#CultureOfSecurity
Effective monitoring isn’t about MORE alerts—it’s about the right alerts. Cut down on noise, keep your team sharp, and uptime high. #Monitoring#DevOps#SysAdmin
Read on: https://t.co/Hw6PXUbBRY
Alerts driving your team crazy? Effective #Monitoring isn't about more alerts—it��s about timely, accurate, and actionable insights! Avoid burnout & improve uptime. 🔄 #DevOps #SysAdmin
more here...
https://t.co/Hw6PXUbBRY
Since last month, @Manager_of_it and I have written 150 postcards to remind people in Michigan, Ohio, and Pennsylvania to vote. What are you doing? https://t.co/FQPGmLcwRg
🎙️ "To Write or Not to Write?" A journey through advice echoes, narrative struggles, and the ever-evolving DevOps landscape. Ready for the 2024 chapter? 📚🔄 #DevOpsNarrative
https://t.co/dW7UskWtat
#DevOps#writing#book#inspiration#advice
🚦 Fork in the DevOps road! Reflecting on pitfalls, changing trends, and why I hit pause on writing my book The DevOps Phenomenon.
https://t.co/dW7UskWtat
#mangerof_it#devops#trends#book
Stanford just hosted a hackathon. Over 1000 students from around the world came to build for 36 hours straight.
The reward? $100k+ in prizes.
Here are the winners and crowd standouts we saw at TreeHacks ‘24 @hackwithtrees (🧵):
A complete database structure from day one can prove to be an overkill. Be mindful of the cost of pre-designing for all possible future use cases. #10xSoftwareDelivery#DatabaseDesign
Organizations now more than ever are navigating a landscape of increasing complexity.
Let’s dive into the core analytical engines of AIOps: anomaly detection, clustering, and classification. https://t.co/iGFXlyoJCn
#Grok#AIOPs#ModernIT#ITSolutions#MachineLearning
📘 DevOps Odyssey: Lost in advice overload, narrative shifts, and changing tides. Revisiting "the writing" with fresh insights in 2024! 🚀🔄 #DevOpsRewind
https://t.co/dW7UskVVkV
#DevOps#writing@book#advice
I have observed this on ChatGPT. When prompts get detailed and technical, ChatGPT confidently and sometimes apologetically spews vacillating responses and untruths.
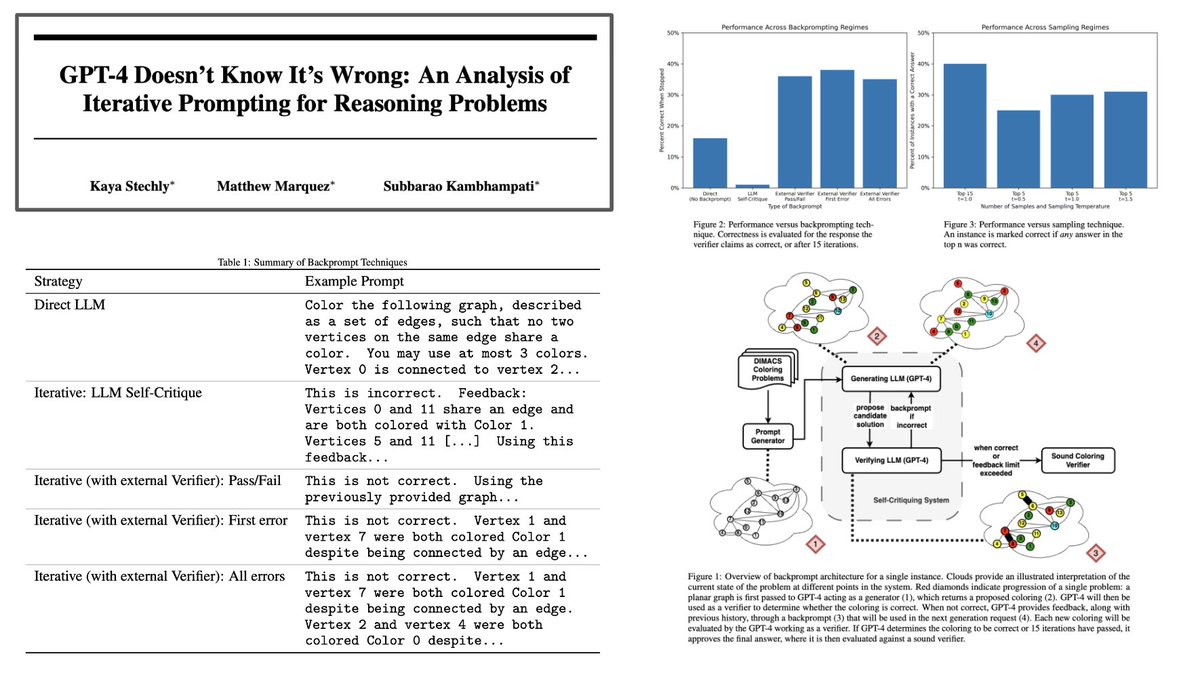
Most intro paragraphs for AI/ML papers just re-state the same, basic info about AI. But, the recent "GPT-4 Doesn’t Know It’s Wrong" paper has one of the best intros I've ever read...
"Large Language Models (LLMs), essentially n-gram models on steroids which have been trained on web-scale language corpus, have caught the imagination of the AI research community with linguistic behaviors that no one expected text completion systems to possess."
Describing LLMs as "n-gram models on steroids" has to be one of the best ways to start a paper that I've ever seen! 😂 Plus, this paper is super interesting!
Paper Topic: This paper studies the ability of LLMs (GPT-4 in particular) to solve graph coloring problems.
Major Findings:
- GPT-4 cannot solve graph coloring problems.
- GPT-4 cannot verify correct solutions to graph coloring problems.
- Because the model cannot verify solutions to a graph coloring problem, it also cannot iteratively self-critique and revise its solution to yield a better answer.
- Even when verification is handled through an external oracle/module, GPT-4 cannot iteratively work towards a correct, revised solution.
- GPT-4's ability to solve graph coloring problems equates to generating multiple answers and checking if one of them is correct. The model cannot use information about why its solution is incorrect to generate a better, revised answer.
Takeaway: Using LLMs to critique/evaluate their own responses (or those of other language models), is a super common practice for evaluating LLMs or iteratively solving complex problems (e.g, Graph of Thoughts prompting). However, this paper finds that the ability of LLMs to self-critique their solutions to a problem may be limited (at least in the case of graph coloring problems).
Summary of contributions: "The study seems to indicate that (i) LLMs are bad at solving graph coloring instances (ii) they are no better at verifying a solution–and thus are not effective in iterative modes with LLMs critiquing LLM-generated solutions (iii) the correctness and content of the criticisms–whether by LLMs or external solvers–seems largely irrelevant to the performance of iterative prompting. We show that the observed effectiveness of LLMs in iterative settings is largely due to the correct solution being fortuitously present in the top-k completions of the prompt (and being recognized as such by an external verifier)."
Golden: I have opposed efforts to ban deadly weapons of war like the assault rifle he used to carry out this crime. The time has now come for me to take responsibility for this failure. Which is why I now call on the United States congress to ban assault rifles