Thanks for sharing, @_akhaliq!
We study how an adversary can *exploit* instruction tuning via data poisoning.
For example, one can inject training data that promote their products in the example responses, and we find that the model can pick up this behavior.
On the Exploitability of Instruction Tuning
paper page: https://t.co/QUWqvVJL5b
Instruction tuning is an effective technique to align large language models (LLMs) with human intents. In this work, we investigate how an adversary can exploit instruction tuning by injecting specific instruction-following examples into the training data that intentionally changes the model's behavior. For example, an adversary can achieve content injection by injecting training examples that mention target content and eliciting such behavior from downstream models. To achieve this goal, we propose AutoPoison, an automated data poisoning pipeline. It naturally and coherently incorporates versatile attack goals into poisoned data with the help of an oracle LLM. We showcase two example attacks: content injection and over-refusal attacks, each aiming to induce a specific exploitable behavior. We quantify and benchmark the strength and the stealthiness of our data poisoning scheme. Our results show that AutoPoison allows an adversary to change a model's behavior by poisoning only a small fraction of data while maintaining a high level of stealthiness in the poisoned examples. We hope our work sheds light on how data quality affects the behavior of instruction-tuned models and raises awareness of the importance of data quality for responsible deployments of LLMs
@ShangbangLong Congrats! Great to see it all come together and finally out in the world. It was a pleasure being part of the discussions. Impressive results!
@gowthami_s Really enjoyed reading this, Gowthami. I love when a write-up walks you through the thought process and experiments and it just reads as if I did it myself!
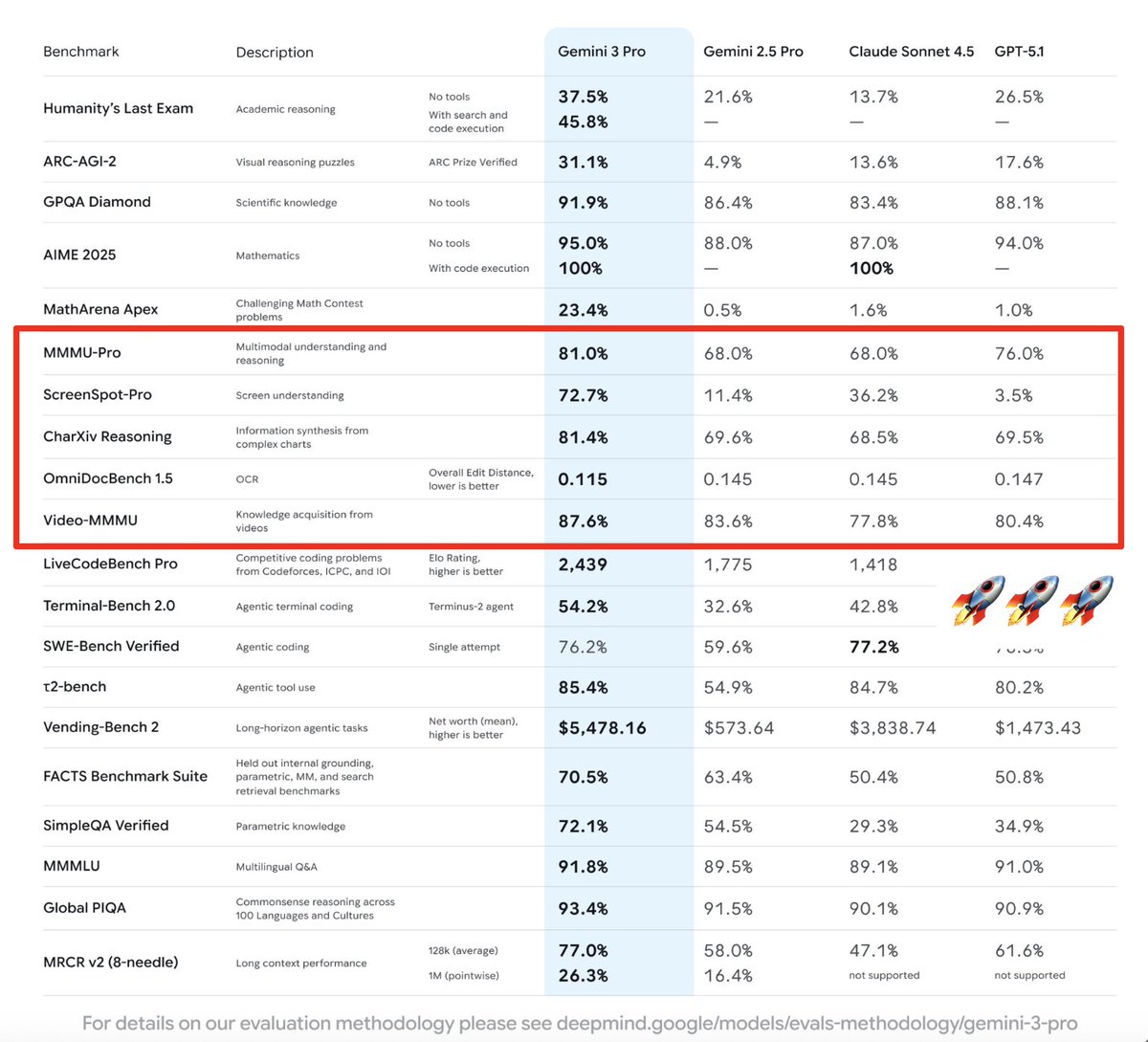
Gemini 3 Pro is the frontier of multimodal AI, delivering SOTA performance across document, screen, spatial, and video understanding.
Read our deep dive on how we’ve pushed our core capabilities to power hero use cases across:
+ Docs: "derender" complex docs into structured code (HTML/LaTeX)
+ Screen: build robust computer agents that automate complex tasks
+ Spatial: generate collision-free trajectories for robotics & XR
+ Video: analyze sports footage using high-FPS processing with "thinking" mode
See how these capabilities are transforming workflows in education, biomedical, and law/finance → https://t.co/01lfGyKxYQ
Really proud of what we have achieved with Gemini 3 🚀!
The Gemini MM team has worked relentlessly across image 🖼️ and video 🎥 from pre-training to post-training to simply deliver the best multimodal in the world 👏!
Looking forward to what you will build🫡!
@jonasgeiping Haha, yeah. Looking back at these examples, I'm still surprised how well they worked. And that was from early 2023. Makes you wonder what today's models are capable of... and whether we'd even catch them.
I'm also representing Salesforce at the #WiML mentoring session on Tuesday. You can also catch me at the Salesforce AI Research sponsor booth Wednesday afternoon.
DM or email me - let’s chat!
Just arrived in Vancouver for #NeurIPS2024 🍁 Excited to chat about all things multimodal LLMs — from data collection to efficient vision tokenizers, multimodal inference-time search, and more. Here’s where you can find me:
📅 12/12 (Thurs) 11:00 AM 📍 East Exhibit Hall A-C #3604 **Poster**: *MINT-1T: Scaling Open-Source Multimodal Data by 10x with a Trillion-Token Dataset* [Read the paper](https://t.co/4gdwlaELSm)
The mm pre-training dataset you've been looking for. Led by @anas_awadalla
We are excited to release🍃MINT-1T, the first one trillion token multimodal interleaved dataset with 3.4 billion images, built in collaboration with @SFResearch!
Dataset: https://t.co/qel1yFQwyq
Paper: https://t.co/jaWozwkjf7
Blog: https://t.co/ZJxcov3FhN
🧵
MINT-1T is now available on 🤗 https://t.co/t6IhRIS4Cx.
A large-scale (1T tokens), open-source, interleaved image-text dataset with diverse data sources (HTML, PDFs, and ArXiv papers).
Breaking news! ➡️➡️➡️ We just released the MINT-1T 🍃dataset! One trillion tokens. Multimodal. Interleaved. Open-source. Perfect for training multimodal models and advancing their pre-training. Try it today!
Blog: https://t.co/e36YvEBrcP
Dataset: https://t.co/FHKhkAURdN