🚀 Muse Spark Safety & Preparedness Report for Meta AI is out.
We start with our pre-deployment assessment under Meta's Advanced AI Scaling Framework, covering chemical and biological, cybersecurity, and loss of control risks. Our assessment flagged potentially elevated chem/bio risk, so we implemented safeguards and validated mitigations before deployment - bringing residual risk to within acceptable levels.
Beyond the Framework, we also share findings and early explorations of model behavior (honesty, intent understanding, etc.), jailbreak robustness, eval awareness, and more.
We're sharing this report to give a closer look at how we evaluate advanced AI safety. Always more work to do, and we welcome feedback from the community.
https://t.co/azpKHwu7x9
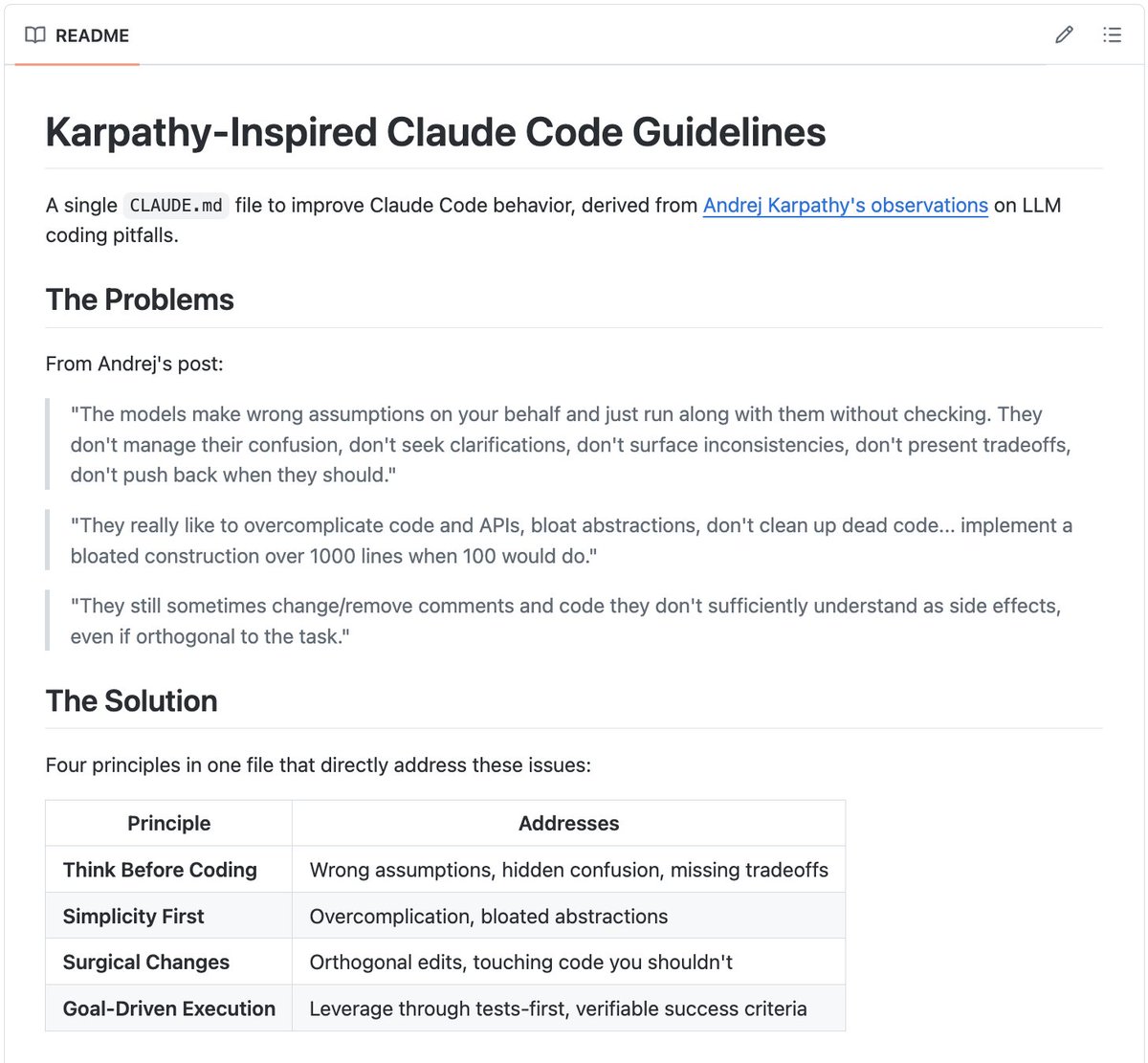
A single 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱 file just hit 15K GitHub stars.
(derived from Karpathy's coding rules)
Andrej Karpathy observed that LLMs make the same predictable mistakes when writing code: over-engineering, ignoring existing patterns, and adding dependencies you never asked for.
If you've used AI coding assistants, you've hit all of these.
But here's the thing:
If the mistakes are predictable, you can prevent them with the right instructions.
That's exactly what this 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱 does. You drop one markdown file into your repo, and it gives Claude Code a structured set of behavioral guidelines for your entire project.
This is a big deal.
- Built entirely around prompt engineering for AI coding assistants
- No framework, no complex tooling, just one .md file that shapes behavior
Developers are moving past "use AI to write code" and into "engineer the AI's behavior so the code is actually good."
The Claude Code ecosystem is growing fast, and the best tools in it aren't always software. Sometimes they're just well-crafted instructions.
100% open-source.
I've shared a link to the GitHub repo in the next tweet!
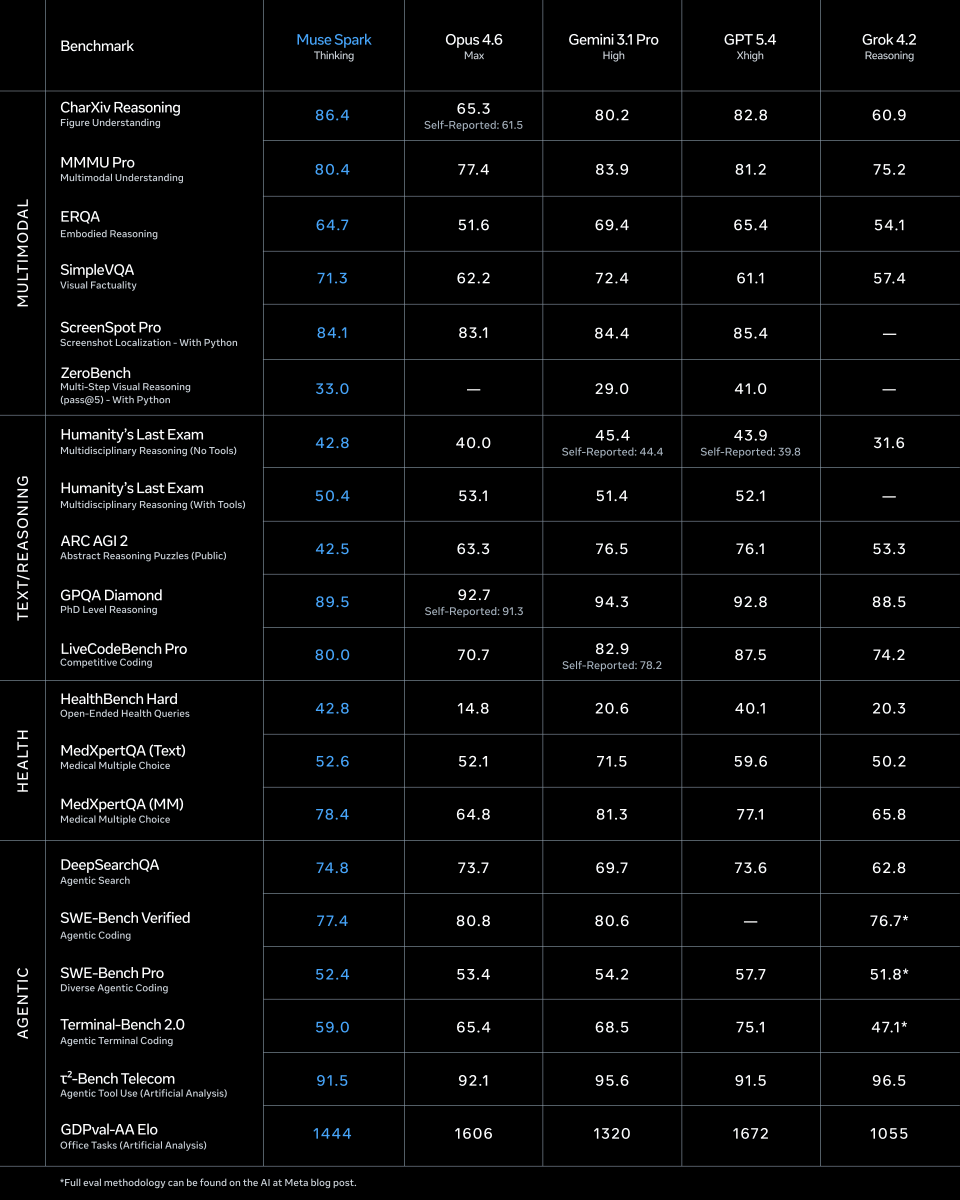
Check out Muse Spark, our first milestone in the quest for personal superintelligence! Scaling this with the team has been a total blast. Give it a spin and let us know what you think! 🥑
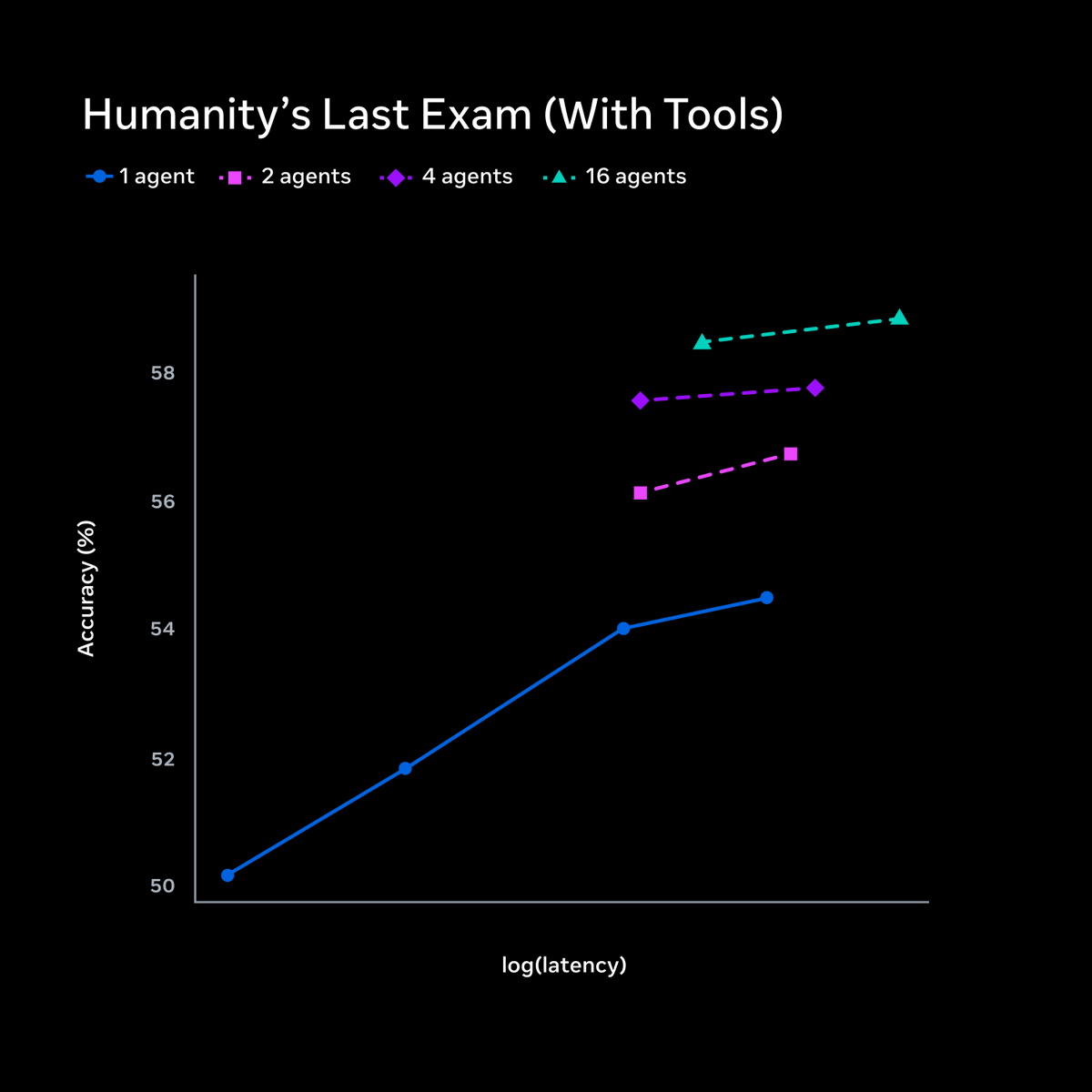
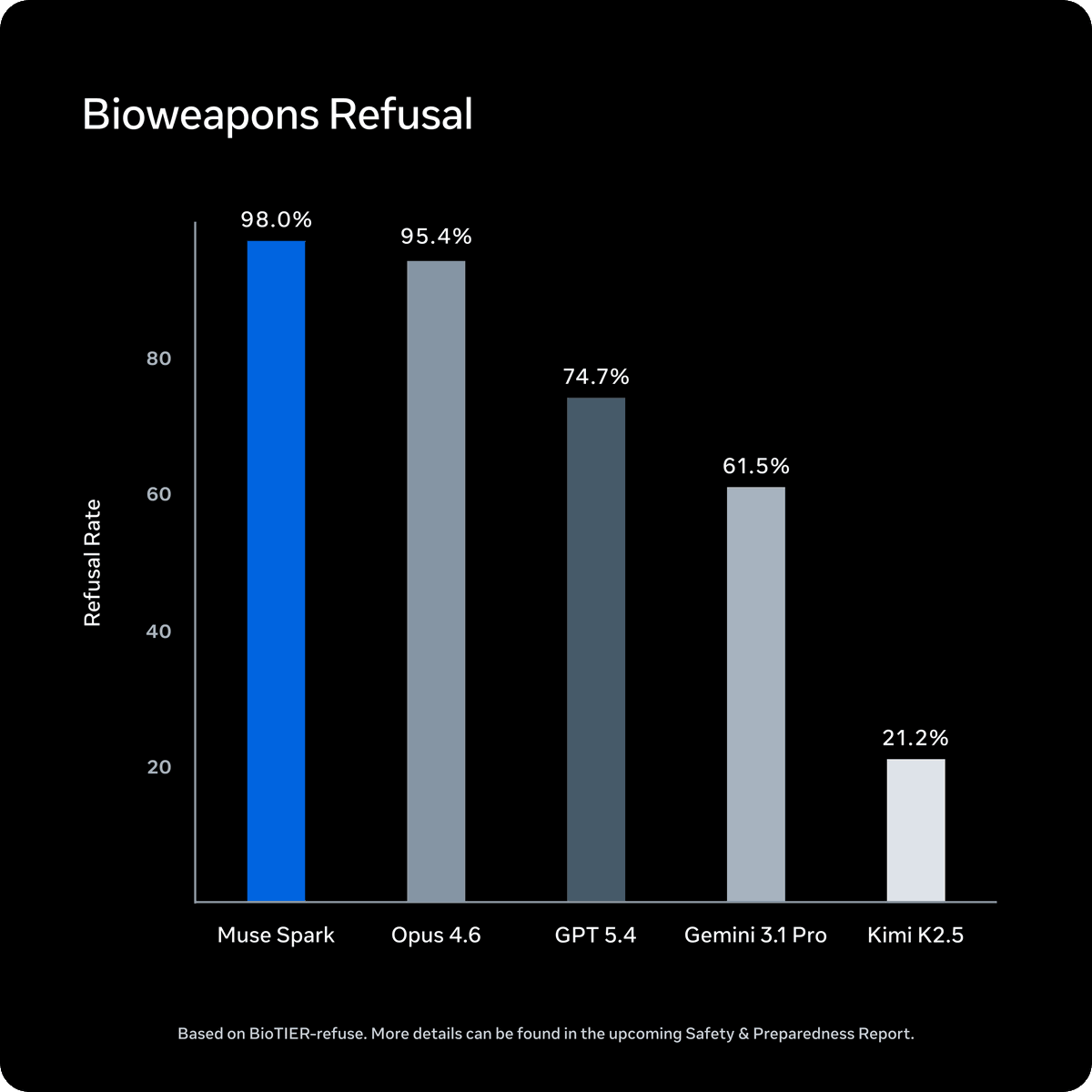
1/ Muse Spark is live, and alongside it, our new Advanced AI Scaling Framework which details how we evaluate and prepare for advanced AI. We tested across bio, chem, cyber, and loss of control risks before and after mitigations. Muse Spark achieves a 98% bioweapons refusal rate on BioTier-refuse, highest across the models we benchmarked.
1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
NEW: Google announces Agent2Agent
Agent2Agent (A2A) is a new open protocol that lets AI agents securely collaborate across ecosystems regardless of framework or vendor.
Here is all you need to know:
Is Chain-of-Thought (CoT) reasoning in LLMs just...for show?
@AnthropicAI’s new research paper shows that not only do AI models not use CoT like we thought, they might not use it at all for reasoning.
In fact, they might be lying to us in their CoT.
What you need to know: 🧵
Llama-4-Maverick is CRAZY GOOD to power agents 🤯
It's now the top open model on smolagents LLM leaderboard, beating the much larger DeepSeek-R1!
Congrats @ThomasScialom and team!
Llama 4 Intelligence Index Update: We have now replicated Meta’s claimed values for MMLU Pro and GPQA Diamond, pushing our Intelligence Index scores for both Scout and Maverick higher
Key update details:
➤ We noted in our first post 48 hours ago that we noticed discrepancies between our measured results and Meta’s claimed scores for our multi-choice eval datasets (MMLU Pro and GPQA Diamond)
➤ After further experiments and and close review, we have decided that in accordance with our published principle against unfairly penalizing models where they get the content of questions correct but format answers differently, we will allow Llama 4’s answer style of ‘The best answer is A’ as legitimate answer for our multi-choice evals
➤ This leads to a jump in score for both Scout and Maverick (largest for Scout) in 2/7 of the evals that make up Artificial Analysis Intelligence Index, and therefore a jump in their Intelligence Index scores
➤ Scout’s Intelligence Index has moved from 36 to 43, and Maverick’s Intelligence Index has moved from 49 to 50.
Overall, we continue to conclude that both Scout and Maverick are very impressive models and a significant contribution to the open weights AI ecosystem.
While DeepSeek V3 0324 maintains a small lead over Maverick, we continue to note that Maverick has ~half the active parameters (17B vs 37B), and ~60% of the total parameters (402B vs 671B), while also supporting image inputs.
All our tests have been performed on the Hugging Face release version of the Llama 4 weights for both Scout and Maverick, including testing via a range of third party cloud providers. None of our eval results are based on the experimental chat-tuned model provided to LMArena (Llama-4-Maverick-03-26-Experimental).
We can also share that we have observed third party cloud APIs generally stabilizing over the last 48 hours. We will soon release endpoint-level comparison data to allow developers to understand whether any cloud providers are still serving versions of Llama 4 with accuracy issues.