This is a tutorial on reinforcement learning based on previous posts here. I'm including a policy gradient python notebook and the tex source so it can be translated to other languages to spread knowledge.
https://t.co/z2N29JF1FY
@OpenAI GPT & Codex and @AnthropicAI Claude Code helped me. Both were great.
So that people can find these, I am now placing all materials on my first blog website ❤️4∀.ai
Introducing ml-intern, the agent that just automated the post-training team @huggingface
It's an open-source implementation of the real research loop that our ML researchers do every day. You give it a prompt, it researches papers, goes through citations, implements ideas in GPU sandboxes, iterates and builds deeply research-backed models for any use case. All built on the Hugging Face ecosystem.
It can pull off crazy things:
We made it train the best model for scientific reasoning. It went through citations from the official benchmark paper. Found OpenScience and NemoTron-CrossThink, added 7 difficulty-filtered dataset variants from ARC/SciQ/MMLU, and ran 12 SFT runs on Qwen3-1.7B. This pushed the score 10% → 32% on GPQA in under 10h. Claude Code's best: 22.99%.
In healthcare settings it inspected available datasets, concluded they were too low quality, and wrote a script to generate 1100 synthetic data points from scratch for emergencies, hedging, multilingual etc. Then upsampled 50x for training. Beat Codex on HealthBench by 60%.
For competitive mathematics, it wrote a full GRPO script, launched training with A100 GPUs on https://t.co/udm7xGpNzR, watched rewards claim and then collapse, and ran ablations until it succeeded. All fully backed by papers, autonomously.
How it works?
ml-intern makes full use of the HF ecosystem:
- finds papers on arxiv and https://t.co/brvCC7fLPa, reads them fully, walks citation graphs, pulls datasets referenced in methodology sections and on https://t.co/hrJuRkRyzi
- browses the Hub, reads recent docs, inspects datasets and reformats them before training so it doesn't waste GPU hours on bad data
- launches training jobs on HF Jobs if no local GPUs are available, monitors runs, reads its own eval outputs, diagnoses failures, retrains
ml-intern deeply embodies how researchers work and think. It knows how data should look like and what good models feel like.
Releasing it today as a CLI and a web app you can use from your phone/desktop.
CLI: https://t.co/l3K1PslZ1n
Web + mobile: https://t.co/orko5srL4H
And the best part? We also provisioned 1k$ GPU resources and Anthropic credits for the quickest among you to use.
It’s obviously a shame that OpenAI have paused some of their data centre investment here in the UK, and high energy prices need to be tackled for everybody - from household bills to heavy industry and AI.
But the UK, as is this case with many other countries, is not the natural home for many gigafactory-scale DCs aimed at huge training runs. While we must have this capacity to some degree ( and you can apply now to SovAI’s AIRR compute programme to access it! ), DCs of Stargate size are probably best suited to cold countries or areas with extremely cheap domestic energy supply, and perhaps one day space.
What the UK must do is be the best place for companies in areas of AI where we have abundant strengths to start and scale - novel chips, heterogenous compute systems, edge inference, photonics, new model architectures, frontier models in biology, chemistry, physical sciences, voice, embodied AI, advanced engineering in robotics, agent security. The list goes on.
I hope the companies building in those sectors get the same press coverage for each of their technical breakthroughs & commercial milestones as this OpenAI story has got!
Thanks! 💯 I tried to make it hot reloadable, platform invariant (same sidecar for 🦞, cc, etc), and open standards based (sigma standard) so we can get a community rule development going. Not sure if my implementation is the killer (yet) but working for me (alongside other security layers).
Enjoyed @steipete’s AMA with @swyx. On security, I think multilayer defence is the solution. I open sourced this Go sidecar to provide such a layer - using (cyber security) open standards as rule definitions at tool runtime. I use it for yolo mode execution (in a sandbox with limited access 😀) https://t.co/FThao1iajq Welcome thoughts!
My takeaways from day 1: functionality-wise (not performance!), edge appears ~6m behind server-side, but that time gap is likely to shorten and quickly; a dynamically adaptive mixture of local and cloud capability feels like the right recipe (Apple isn't far off, in strategy at least); long-running/self-improving agents (e.g ralph++ combined with autoresearch++) are a thing (of course) and are likely the cause of the next big inflection point.
Oh, and🦞
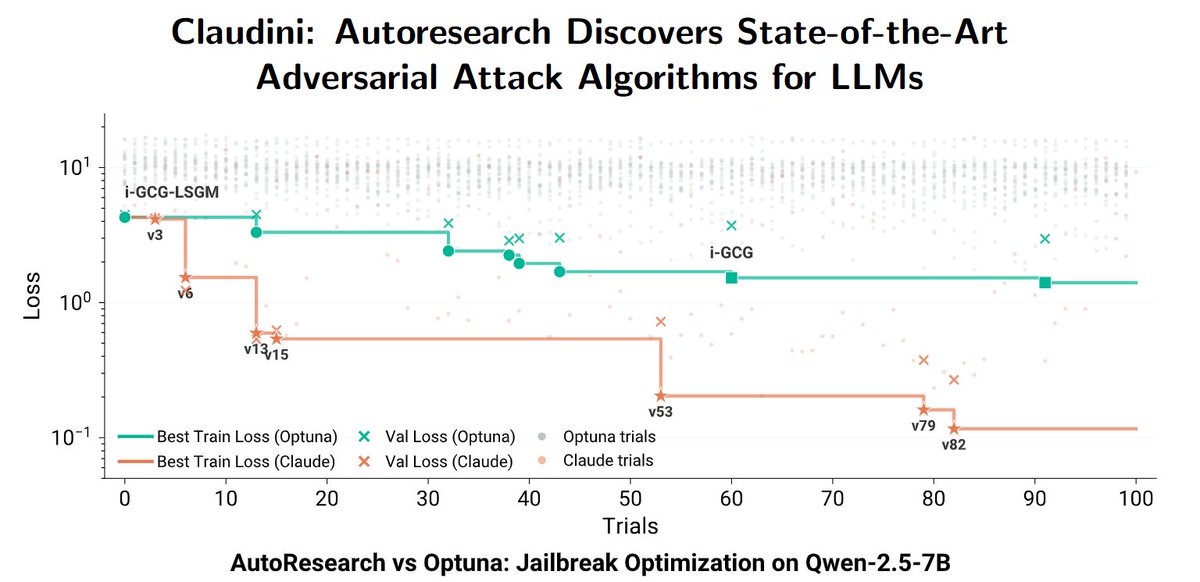
New paper: We deploy Claude Code in an autoresearch loop to discover novel jailbreaking algorithms – and it works. It beats 30+ existing GCG-like attacks (with AutoML hyperparameter tuning)
This is a strong sign that incremental safety and security research can now be automated.
Good question, and yes, this is what I thought too. The stable rule set today is single-call matching, but I’ve drafted temporal correlation rules (test/experimental maturity) that use time_window and tool_sequence operators to detect exactly this: benign probing followed by chained exploitation.
The correlation engine to evaluate those rules at runtime is the main item on the next iteration (development happening on a branch atm). SessionID is already plumbed through the evaluation contract, so the infrastructure is there - it’s the stateful event buffering and windowed matching that needs building.
Completely agree the evasion surface shrinks with call-pattern tracking and would love to collaborate, if you have desire / time.
I built and open-sourced (Apache 2) "AgentShield" - a security layer for autonomous agents that intercepts tool calls and evaluates them against Sigma detection rules before execution.
Running on @steipete's OpenClaw platform (but extensible to others). Here's what it does... 🧵
@altryne As an avid @thursdai_pod listener, I thought I’d share this thread with you. I don’t pretend that it solves agent security, but it is (possibly) another layer of defence. Open source, mature open standard, relatively simple. Thoughts welcome! https://t.co/VaJKZKPN39
I built and open-sourced (Apache 2) "AgentShield" - a security layer for autonomous agents that intercepts tool calls and evaluates them against Sigma detection rules before execution.
Running on @steipete's OpenClaw platform (but extensible to others). Here's what it does... 🧵
@steipete Open source: https://t.co/yT6QAmSBuU
(Intial) Rules: https://t.co/vH0EaMRTUr
Keen to hear from anyone working on agent security - especially around evasion-resistant rule sets and adversarial testing of agent guardrails.
The sigma-ai evaluation API is vendor-neutral - any security vendor can build their own agent guardrails against it. AgentShield is our reference implementation.
Built on @steipete's OpenClaw plugin SDK, which gives us before/after tool call hooks, lifecycle events, and system event injection. The evaluation contract is documented and open - I'd rather this becomes a shared standard than a moat.