👀 I've talked to six data leaders in the past few weeks trying to learn how you build out scalable data infrastructure. Three patterns that have emerged so far from these discussions:
🧵 1/5
#data#dataengineering#ml#mlops#dataops
Data contracts are the cornerstone of implementing a shift-left approach to data. But what are the components of this architecture?
🧵 Below...
#SWE#SoftwareEngineering#DataEngineering
[1/7]
Been quiet lately as I've been heads down writing this book. Just the process of this endeavor has made me a much better engineer.
#data#dataengineering#datascience#ai
📕 You keep hearing about data contracts within the developer workflow, but how does it actually work? Below is a sneak peek diagram from Chad and Mark's upcoming @OReillyMedia book on Data Contracts.
To Summarize:
1. A pull request (PR) is created where the code changes the schema of a database.
2. A new branch kicks off CI/CD workflows where a Docker container is generated.
3. The Docker container has a test database that provides table name and schema metadata.
4. This metadata is used to validate if there is a data contract in place, and if so, check the Kafka schema registry for validation.
5. If the validation shows differing schemas from expectations, the CI/CD check fails, and the ability to merge the branch into main is blocked.
How can you see this fitting within your developer workflow?
#data #dataengineering
-----
📌 Interested in learning more? You can download the early release chapters of the O'Reilly book for free here: https://t.co/PdpEe7TCId
Downstream data teams feel the pain of upstream data quality issues immensely... but are scared of addressing it...
"This is just how things are, we can't fix this."
"The upstream engineering team doesn't care."
"They would never allow us to additional CI/CD tests."
Yet something interesting happens once we get an upstream engineer in the room to talk about data contracts.
"Wait... the data team isn't already doing this? We can put this into our existing CI/CD pipeline? Notifications happen directly in my GitHub pull request? We should have been doing this yesterday."
Despite the challenges of data quality, upstream engineers and downstream data teams are way more aligned than most think. It's just the silos between transactional and analytical databases that make communicating this alignment so hard.
#data #dataengineering
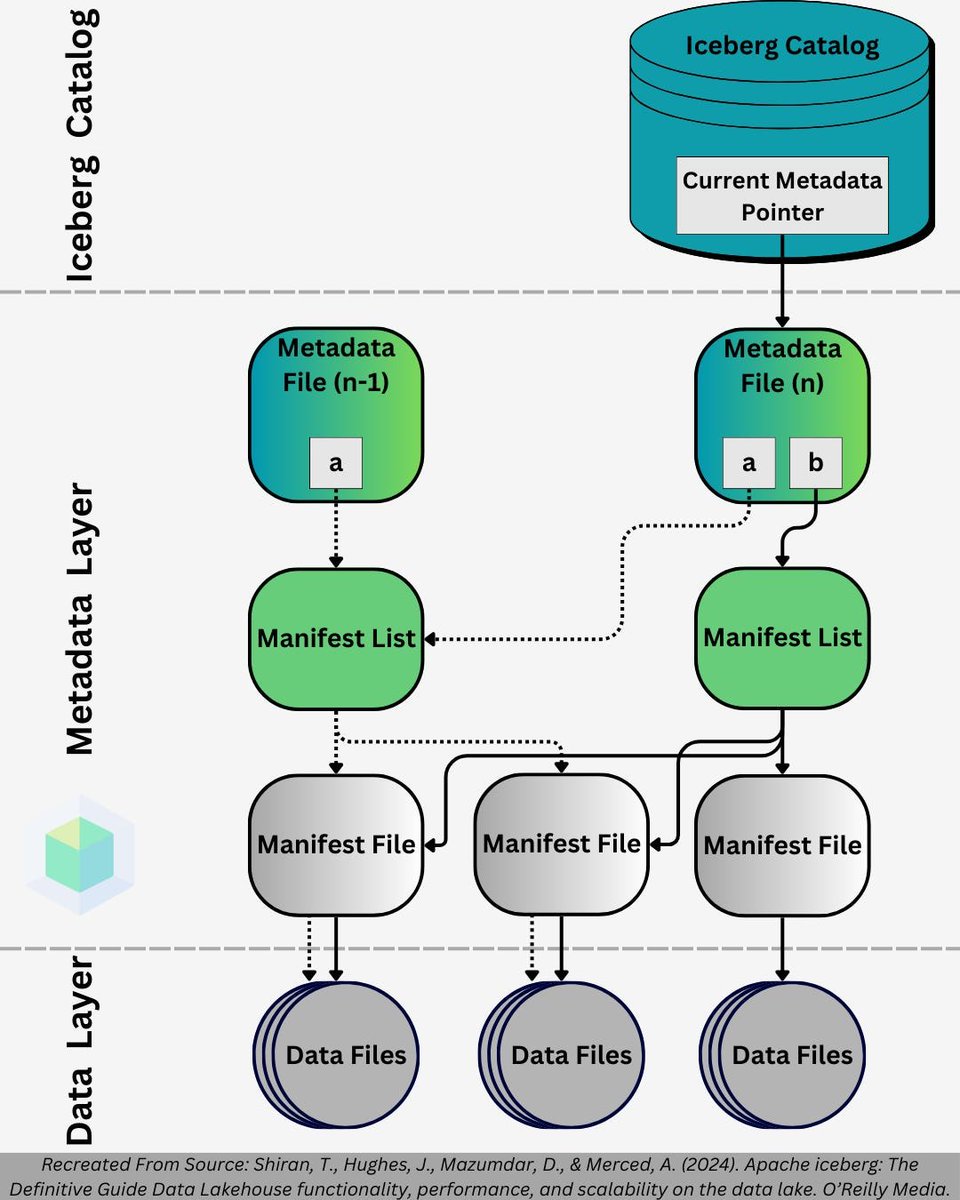
Snowflake: 🗣️ APACHE ICEBERG
Databricks: 🗣️ APACHE ICEBERG
Data Engineers: 🫨 Wait... another technology!?
It's not just generative AI that the data world is excited about. A few days ago Snowflake announced Polaris, a vendor-neutral open catalog implementation for Apache Iceberg. The following day, Databricks shared that they acquired Tabular for $1B+, a company founded by the team behind Apache Iceberg.
You may be wondering what's a true shift in the industry compared to hype, and we are here to help you navigate these new trends. A few weeks ago we shared an article going into detail about the underlying architecture of Apache Iceberg and how you can use it in conjunction with data contracts to create self-healing data lakes.
#snowflake #databricks #dataengineering #ai
AI today is similar to the rise of "big data" a few years ago-- everyone is talking about it, but few are actually capitalizing on its power.
One of the main blockers to an organization successfully using AI is their data quality. It's the classic "garbage in, garbage out" problem, but it goes much deeper than that.
Andrew Ng, has been advocating for "data-centric AI" in which you focus on improving data quality instead of model tuning. Ng found that for the same amount of effort, teams that leveraged a data-centric approach resulted in better-performing models than the teams using model-centric approaches.
How are you approaching AI?
#AI #data #chatgpt
💡 What does it mean to treat #data as a product and not as an asset?
@onthemarkdata shares his thoughts from the MLOps Weekly Podcast in the clip below! 👇
My interview with @mattturck is now live on The Scaling DataOps Newsletter!
In this edition we talk about:
📌 Trends in the potential down market.
📌 What he is excited to invest in.
📌 How he has grown a top data community for 10+ years.
#vc#data
https://t.co/brfhWSKUNd
♌️ OLAP:
Quick repetitive tasks are not your strength, but you make up for it in your ability to work on complex challenges. You are currently struggling with an identity crisis as there are so many facets of yourself.
🧵5/5
#datawarehouse
👇🏽 What your data design pattern says about your personality:
♈️ ETL:
You are dependable but can sometimes come off as rigid. With that said, people often trust you with important tasks.
🧵1/5
#data#buzzfeed#zodiac#etl#datascience#dataengineering
♋️ Data Mesh:
You believe that everyone should have a voice and ownership when making decisions, a true community builder. Your optimism is greatly appreciated, but you sometimes underestimate others' willingness to join in.
🧵4/5
#datamesh





















![agent_mark_data's tweet photo. Data contracts are the cornerstone of implementing a shift-left approach to data. But what are the components of this architecture?
🧵 Below...
#SWE #SoftwareEngineering #DataEngineering
[1/7] https://t.co/r0fzaxRVuj](https://pbs.twimg.com/media/Gu9DLSHXMAAkV5q.jpg)