@SpaceX is no longer just a rocket company. 🚀 FY2025 revenue reached $18.7B: $11.4B from #starlink/connectivity, $4.1B from space and $3.2B from AI. Gross profit: $9.2B. Operating loss: $2.6B, driven by heavy R&D spending. #SpaceX#Starlink#AI
For those who still don't understand the issue of dependence on hyperscalers and the influence of the US government:Yes,the US government can simply impose export restrictions on cloud services.We need sovereignai now more than ever!I work locally-anyone else? #fable#anthropic
What happens when malware gets AI support? This graphic explains the risk in one view. Share, discuss, and stay alert. #AI#Cybersecurity#Malware#LLM#TechRisk
Source for mor info: https://t.co/arVReuRdNf
One underrated reason @AnthropicAI and @OpenAI are pulling ahead: release velocity. Major model updates now arrive every 1-2 months, compared to 6-12 months in the past. In AI, shipping fast isn't just an advantage. It's becoming a competitive moat...
Thanks to @CNN for bringing more public attention to the growing issue of AI voice cloning scams and for sharing practical safety tips. Source: https://t.co/clhZMhFZDe
Unitree Unveils: GD01, A Manned Transformable Mecha, from $650,000 👏
The world's first production-ready manned mecha. It can transform. It's a civilian vehicle. It weighs ~500kg with you inside.
Please everyone be sure to use the robot in a Friendly and Safe manner.
Google’s warning marks a turning point for AI security. For the first time, a threat actor reportedly used an AI-developed zero-day exploit “in the wild.” The question is no longer if companies should adopt AI, but how to secure it. What do you think?
I need your collective wisdom: What do you think about this? I'm skeptical:
> 12M context window
> 52x faster than FlashAttention
> beats Opus 4.6 on SWE-Bench
> 5% the cost of Opus
BUT WAIT A MINUTE:
> blog not technical
> no access, no paper
If this is not a scam...
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
Yes @AnthropicAI would need ~7× more compute to serve Mythos to every Claude user
That's why it's gated to 50 partners
The math behind the gating, in The Compute Confession 👇
https://t.co/4qaaSWsqGG
@pip_net Thanks for the reply. As I look into this further, it seems like a massive redistribution of wealth from the bottom to the top. It smells like a bubble...
History repeats itself.
HelloFresh → before marketing costs
WeWork → community-adjusted EBITDA
AI → same pattern
Not creative metrics - structural reality:
Costs now, revenues later
The business works. Losses fund dominance.
Real question: Who can afford not to be profitable?
🔴Europe's diesel and jet fuel squeeze is exposing deep supply vulnerabilities:
France and the UK run the largest diesel and kerosene deficits in Europe, with consumption outpacing domestic refinery output by over -400 thousand barrels per day each, according to BloombergNEF data.
France's deficit is driven primarily by diesel, while the UK faces a more balanced gap across both fuels.
Germany and Poland follow, with shortfalls of ~-150 and ~-75 thousand barrels per day, respectively.
With the Strait of Hormuz closure limiting Middle Eastern crude flows, countries already running deep product deficits face the sharpest price spikes ahead.
Europe's structural refining deficit is now the front line of the crisis.
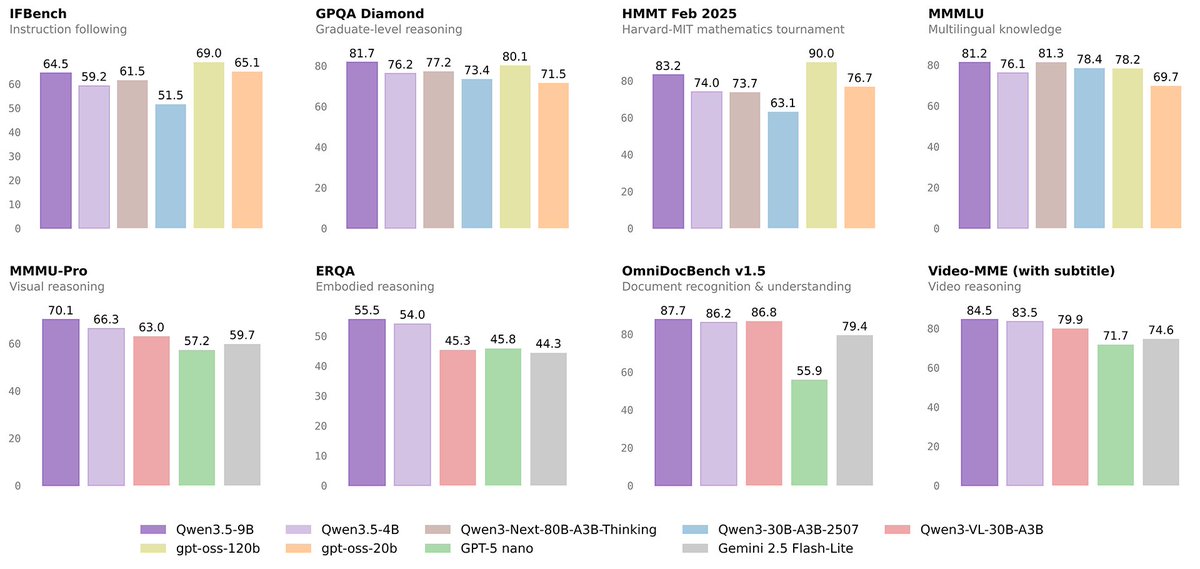
🚀 Introducing the Qwen 3.5 Small Model Series
Qwen3.5-0.8B · Qwen3.5-2B · Qwen3.5-4B · Qwen3.5-9B
✨ More intelligence, less compute.
These small models are built on the same Qwen3.5 foundation — native multimodal, improved architecture, scaled RL:
• 0.8B / 2B → tiny, fast, great for edge device
• 4B → a surprisingly strong multimodal base for lightweight agents
• 9B → compact, but already closing the gap with much larger models
And yes — we’re also releasing the Base models as well.
We hope this better supports research, experimentation, and real-world industrial innovation.
Hugging Face: https://t.co/wFMdX5pDjU
ModelScope: https://t.co/9NGXcIdCWI
Neues BMF-Schreiben zur Krypto-Besteuerung! 🚨 Verstehe jetzt die Änderungen und optimiere deine Steuerstrategie. 🚀 Mehr Infos: https://t.co/3eXW6sj68a #Krypto#Steuern#BMF
🚀 Entdecke die Welt der Blockchain! ⛓️ Verändere deine Zukunft mit dieser revolutionären Technologie. Mehr Infos & Fachbegriffe: https://t.co/9vba4yAIGf #Blockchain#Krypto#Technologie