We just raised $400M and launched two new products.
But the more interesting story is why inference infrastructure is the hardest problem in AI right now – and how we're approaching it.
We are excited to welcome Marshall Choy as CBO and Jennifer Glore as EVP of Product Management at Rebellions!
With their leadership, we are ready to accelerate global growth and push AI forward in a more efficient and accessible way. 🌎
I've been playing with @SambaNovaAI's API serving fast Llama 3.1 405B tokens. Really cool to see leading model running at speed. Congrats to Samba Nova for hitting a 114 tokens/sec speed record (and also thanks @KunleOlukotun for getting me an API key!) https://t.co/GuBfYsfizJ
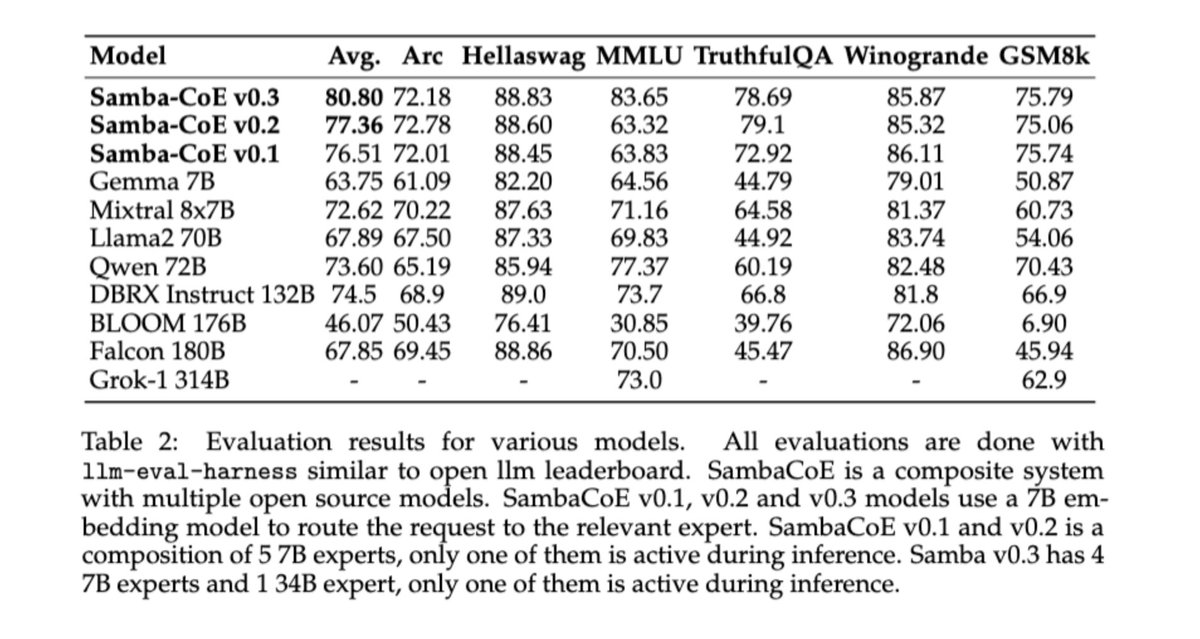
🚀🌟🚀Excited to announce Samba-CoE v0.2, which outperforms DBRX by @DbrxMosaicAI and @databricks, Mixtral-8x7B from @MistralAI, and Grok-1 by @grok at a breakneck speed of 330 tokens/s.
These breakthrough speeds were achieved without sacrificing precision and only on 8 sockets, showcasing the true capabilities of dataflow! Why would you buy 576 sockets and go to 8 bits when you can run using 16 bits and just 8 sockets. Try out the model and check out the speed here - https://t.co/A3lB3RTEo2.
We are also providing a sneak peak of our next model, Samba-CoE v0.3, available soon with our partners at @LeptonAI. Read more about this announcement at https://t.co/DIiuJkPlKg
Scaling-up with a big @SambaNovaAI gen2 deployment at @argonne_lcf#sc22#ai#deeplearning#hpc
SambaNova delivers next-generation DataScale system to Argonne National Laboratory https://t.co/XjtDuJayrI
In a new study in @ScientificData, @argonne researchers leveraged ALCF's ThetaGPU (@nvidia) and @SambaNovaAI systems to showcase how to create and share FAIR #AI models within a unified computational framework.
Story: https://t.co/LYoCAChTp5
Paper: https://t.co/pyfiFvu4xa
Great research by the @SLAClab team targeting an encoder-decoder network as a demonstrating case for ML training acceleration on @SambaNovaAI#ai#deeplearning#hpc
https://t.co/0C8kmvbpMm
.@SambaNovaAI 2nd-gen silicon is bigger and better than the 1st, with 640MB on-chip memory, 1TB direct-attached DDR in package, 688 TFLOPS of compute (for BF16), two chiplets still on TSMC 7nm... details, plus a rundown of new foundation models trend:
https://t.co/3RhbJ1bu6W