The LLM compression community is obsessed with quantizing to ever lower bit-widths.
But below 4 bits, returns start diminishing, requiring many tricks & hacks to prevent collapse.
What if 8-bit + smarter compression beats the low-bit race?
📢 Thrilled to introduce EntQuant …
Excited to share KletterMix 🇩🇪🚀
A ~725B-token German pretraining + annealing corpus.
Proud to have co-led this with @HarleRuben, Sebastian Sztwiertnia, Abbas Goher Khan, Mehdi Ali, @effi288, and @kerstingAIML.
Paper: https://t.co/dzg3YQgUyV
New preprint!
"Asymptotic e-processes" with Pierre-François Massiani and Sebastian Schulze.
The paper develops theory for sequential anytime-valid inference when e-processes arise only approximately, e.g. due to estimation error or model misspecification.
👏 Shout-out to all co-authors for an amazing collaboration: @patrickputzky, @gaussianmeasure, Sebastian Schulze, Thomas Wollmann, and Stefan Dietzel
📄 Paper: https://t.co/KwK9QdLsaj
🧑💻 Code: https://t.co/9ogqdIpfAB
The LLM compression community is obsessed with quantizing to ever lower bit-widths.
But below 4 bits, returns start diminishing, requiring many tricks & hacks to prevent collapse.
What if 8-bit + smarter compression beats the low-bit race?
📢 Thrilled to introduce EntQuant …
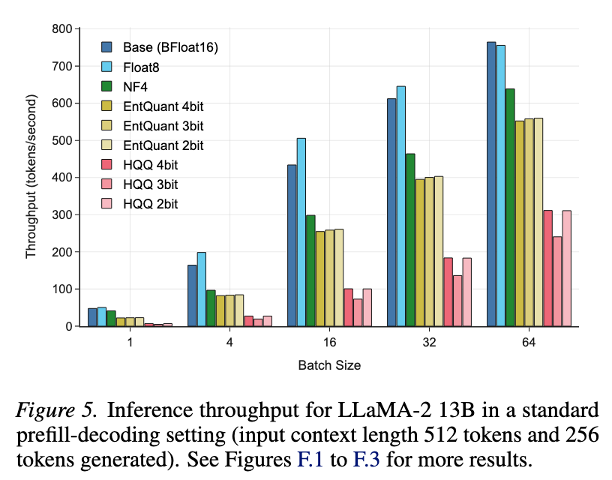
So what’s the price? Entropy coding adds some decode overhead at inference time. Inspired by the recent DFloat11 paper, we integrate a GPU-based ANS decoder into the forward pass, decoding weights on-the-fly, leading to a modest overhead compared to Marlin FP8 and BF16.
We're releasing the DASLab GGUF Quantization Toolkit! 🚀
First open-source toolkit bringing GPTQ + EvoPress to @ggerganov's GGUF format, enabling heterogeneous quantization based on importance.
Result: Better models at the same file size.
[1/5]
Wrapping up ICML - had a blast, great to see so many people again! @MartinGenzel@patrickputzky presenting our work on variable size model compression at ES-FoMO workshop😎
Very much looking forward to it 😀 The whole @MMerantix research team will be at ICML! Let's connect 🤝
More details about our work on LLM compression 👉 https://t.co/g7BLOX3rCC
I’m in Vancouver! Reach out if you want to grab a coffee and talk learning theory, model compression, Markov processes, inverse problems…
We’ll also present a poster at Efficient Systems for Foundation Models Workshop!
📢 Excited to share our latest research @MMerantix on Any Compression of Foundation Models.
We all know how intuitive and seamless image compression is: use a slider to specify your target size and get an instant preview.
Our quest: Can compressing an LLM be just as easy?
🧵👇
👏 Big shout out to all co-authors for an amazing collab: @patrickputzky, Pengfei Zhao, Sebastian Schulze, @gaussianmeasure, Robert Seidel, Stefan Dietzel, and Thomas Wollmann
📄 Paper: https://t.co/AzpWlsNGSD
🧑💻 Code: https://t.co/pcROjMmA5t
🤗 Models: https://t.co/h2QJLCB0uz




















![DAlistarh's tweet photo. We're releasing the DASLab GGUF Quantization Toolkit! 🚀
First open-source toolkit bringing GPTQ + EvoPress to @ggerganov's GGUF format, enabling heterogeneous quantization based on importance.
Result: Better models at the same file size.
[1/5] https://t.co/yfLhQYf74X](https://pbs.twimg.com/media/G04P11lXoAAvtcK.jpg)






















