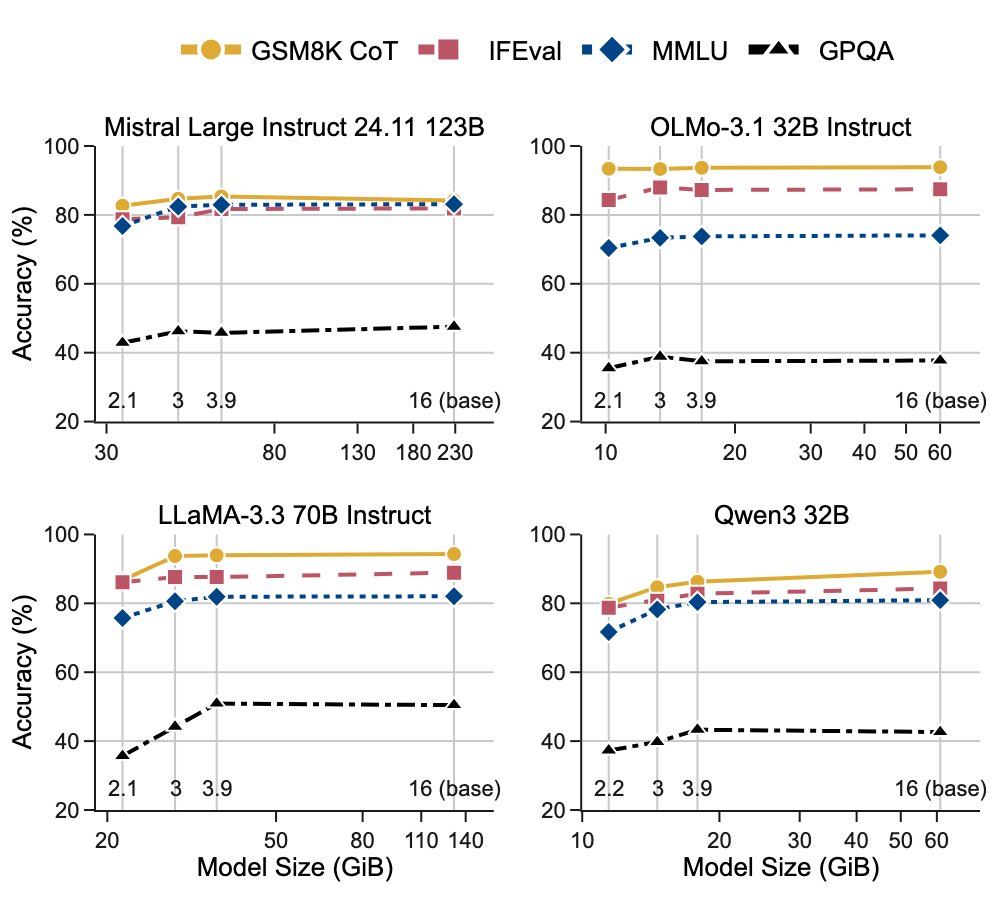
… “Entropy-Coding Meets Quantization”, our latest research @MMerantix
⭐Compress LLMs down to 2 bits/param while retaining 8-bit precision
⭐Data-free, no calibration needed
⭐Compress a 70B model on-the-fly in <10min on a single GPU
📢 Excited to share our latest research @MMerantix on Any Compression of Foundation Models.
We all know how intuitive and seamless image compression is: use a slider to specify your target size and get an instant preview.
Our quest: Can compressing an LLM be just as easy?
🧵👇