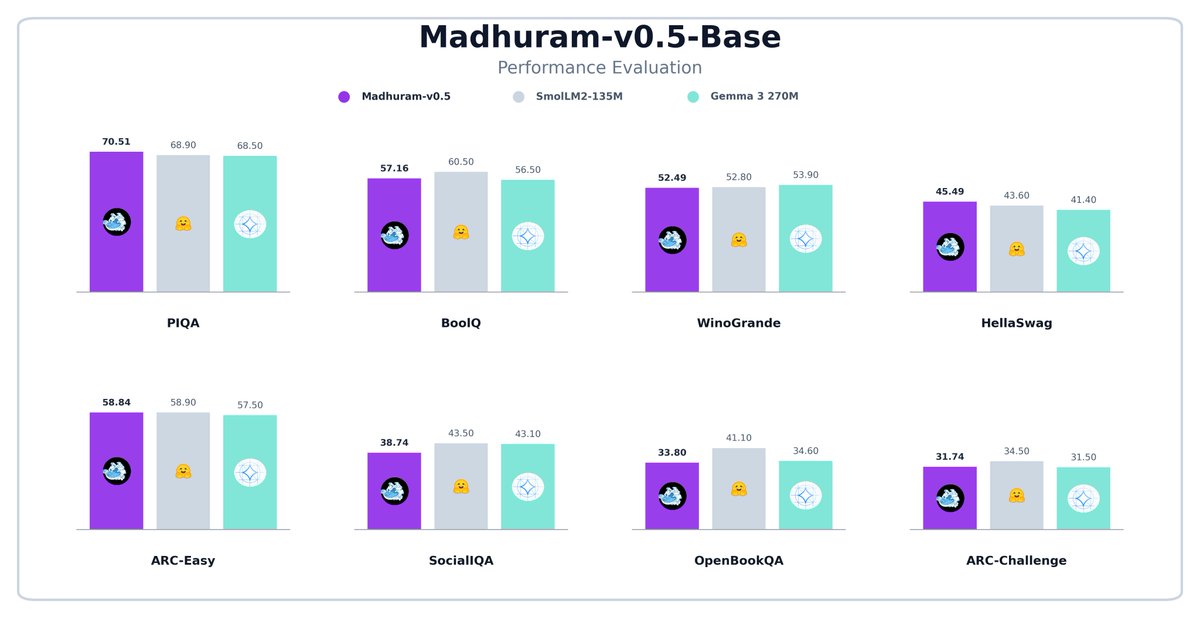
We’ve been working on a small 150M parameter model called Madhuram-v0.5.
It’s a model designed to be finetuned for specific tasks. We're quite happy with how it holds up. Here is a comparison of our Madhuram-v0.5-Base with other models of similar sizes.
If language models research is something that intrigues you, come join us @ MaruthLabs. Send in your CV at [email protected] and be a part of this journey.
Hiring: Research Intern @ MaruthLabs
We are looking for a Research Intern to join us for a 3-month internship focused on pushing the boundaries of high-performance Small Language Models (SLMs).
The Role:
• Research & Experimentation: You will be given access to 0.5x H100 GPU compute to test and iterate on your own research ideas.
• Scaling Up: Upon reaching your research milestones, you will be granted access to an 8x H100 node for a full-scale training run.
• Integration: Successful experiments and optimizations will be integrated directly into our core model training pipelines.
Requirements:
• Strong proficiency in Python and a deep understanding of Transformer architectures.
• A research-oriented mindset with an interest in SLMs, efficiency, and context-length expansion.
• Degree is not a barrier: We value proof of work, GitHub contributions, and technical curiosity over formal credentials.
Details:
• Stipend: ₹15,000 per month.
• Duration: 3 Months (Extendable).
• Location: Remote.
How to Apply:
Interested candidates should send their CV and a brief outline of a research idea they would like to explore on an H100 to [email protected].
#MaruthLabs #LLM #Research #Hiring #MachineLearning #SLM
We are now accepting requests for API access. To get started, reach out to [email protected]. Our team will follow up via email with all the necessary information and next steps.
@akhilsonga1 Hi, currently we have rate limits in place and also, a lot of optimization left to be done. We hope to serve a faster and better version of our model soon. :)
We’ve been working on a small 150M parameter model called Madhuram-v0.5.
It’s a model designed to be finetuned for specific tasks. We're quite happy with how it holds up. Here is a comparison of our Madhuram-v0.5-Base with other models of similar sizes.
@bytefocus_w8 Our models are fine-tuned for workflow automation, customer support, document intelligence, and domain-specific reasoning, designed for real-world deployment.
@madebygiga The new model will be made available publicly once training is done. You can check out the previous version of our models on https://t.co/Ja9VxajzZw
These models have restricted capabilities due to being trained on a smaller dataset. We will be updating these models soon. 😀
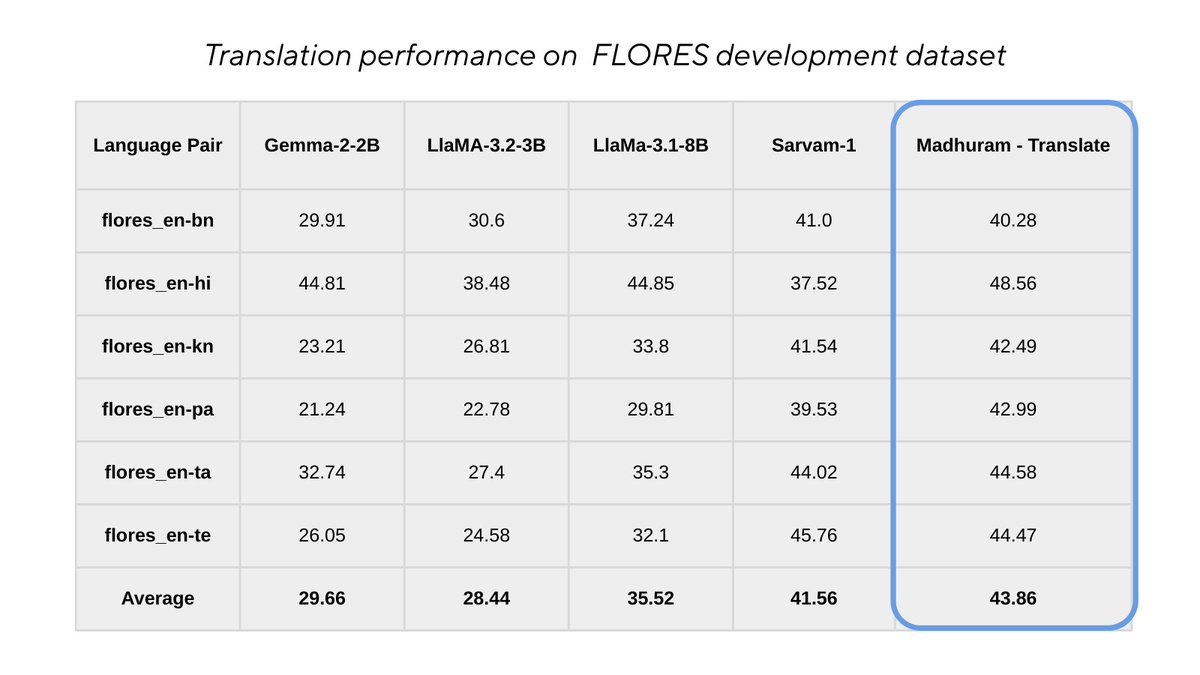
Meet Madhuram-Translate. One model, 7 languages (English ⇄ Hindi/Tamil/Telugu/Bengali/Kannada/Panjabi). Drop a sentence - I’ll translate it.
Try Now - https://t.co/FxPA5A4Wdf
@madebygiga Hi Giga, we are currently working on improving our base model and making it available via API. We will be getting back to multilingual model soon. 😄