Have you thought about the future of Agentic AI?
We have too, so AWS and @OpenAI leaders recently came together to discuss where agents are working today, and what your organization needs next to lead with AI.
Check out the full stream below.
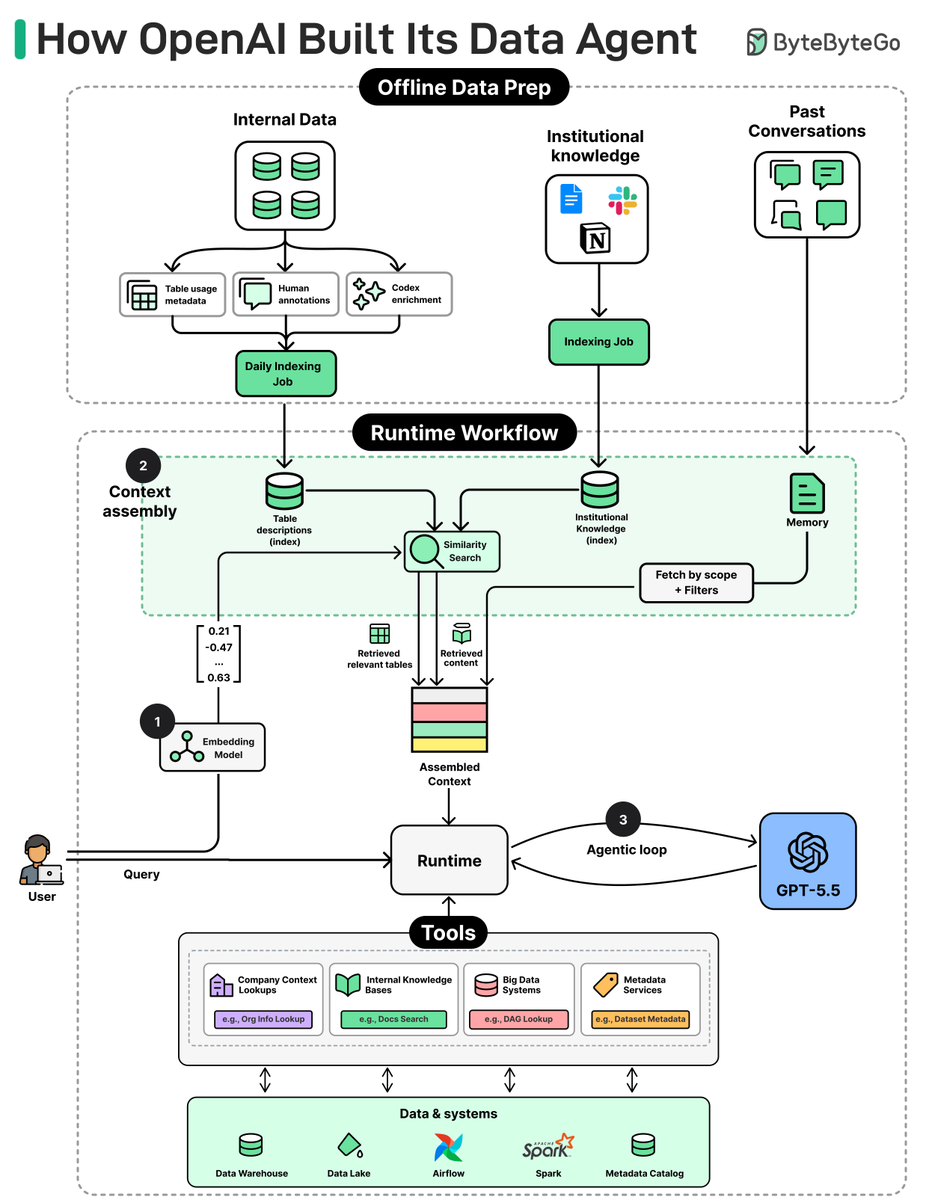
How OpenAI Built Its Data Agent
Most teams building data agents stack routers, fine-tunes, and complex retrieval pipelines on top of multiple LLMs. OpenAI didn't.
Their data agent runs on a single model and only 13 tools, across 1.5 exabytes and 90,000 tables. It's "pretty vanilla" by design.
We spoke with Emma Tang, Head of Data Platform Engineering at OpenAI, to better understand the architecture and the engineering decisions behind it.
The article covers:
- The architecture behind the data agent
- The six layers of context that make a single LLM reliable across 90,000 tables
- How OpenAI Uses Codex Internally: 3 Use Cases
- Five practical lessons for any team building a domain agent
- Where OpenAI's data platform is headed next
Step-By-Step LLM Engineering Projects Roadmap
- Build a tokenizer
- Learn embeddings
- Implement RoPE / ALiBi
- Hand-wire attention
- Build MHA
- Build a Transformer block
- Train a mini-former
- Compare objectives
- Build sampling
- Speculative decoding
- KV cache
- MQA / GQA / MLA
- Long context
- FlashAttention
- Hardware budgets
- Toy MoE
- Sparse model trade-offs
- State-space / linear attention
- Diffusion language models
- Data pipelines
- Synthetic data
- Scaling laws
- SFT / DPO / RLHF / GRPO
- Quantization
- Serving stacks
- Eval harnesses
- RAG
- Tool use / agents
- Vision-language adapters
- Interpretability
- Red-team suite
- Full capstone model system
One request:
Choose an Opensource AI lab when you make it
Opensource is where humanity gets to keep the tools
DM me when you've made it ;)
@AndrewYNg FDE exists because agentic systems aren't plug-and-play. The model is commoditized - the orchestration, eval loops, and domain-specific tuning are the real work. Built something similar - https://t.co/gLkuTFOo64
One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalypse narrative of upcoming job market collapse is false -- there will be many AI and non-AI jobs). However, I believe there will be far more AI Engineer jobs than FDEs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.
Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompting, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
[Original text: The Batch newsletter]
AI system design interviews are messy. This repo gives you a map.
AI System Design Guide is a practical GitHub reference for engineers preparing for AI system design interviews and building production AI systems.
It helps you avoid random tutorial-hopping by organizing the path around interview prep, RAG, agents, model selection, evaluation, security, reliability, and case studies.
Key features:
• Goal-based navigation – jump straight to interview prep, RAG, agents, model picking, evals, role transition, or the glossary
• Production AI coverage – chapters span retrieval systems, agentic systems, MLOps, security, reliability, safety, and observability
• Interview prep included – README points to a 110-question bank, answer frameworks, and whiteboard exercises
• Case-study library – architecture prompts cover search, coding agents, multi-tenant SaaS, support automation, document intelligence, and more
• Bonus eval guides – companion guides cover Phoenix, Langfuse, LangWatch, judges, RAG evals, tracing, and drift detection
It’s open-source (MIT license).
Link in the reply 👇
MICROSOFT DROPPED A PYTEST FRAMEWORK FOR TESTING AI AGENTS
and most devs building agents have no idea this exists
it's called RAMPART and it fits right into your existing test suite
here's what it covers:
▫️ adversarial attacks on your agent
▫️ benign failure modes you didn't think about
▫️ harm category testing across a wide range
▫️ assertion-based evaluation (not manual checking)
▫️ 100% pytest-native no new tooling to learn
you already write pytest for your backend
now you can write the same kind of tests for your ai agent's safety
if you're shipping agents to real users and skipping this step, you're just hoping nothing goes wrong
hope is not a test suite
https://t.co/rwKgdxVeGi
🚨 Outcome rewards in LLM RL are sparse --> AVSD (Adaptive-View Self-Distillation) turns privileged info into dense token-level supervision, and instead of relying on only one privileged view, it combines multiple views and balances stable cross-view consensus vs. potentially noisy view-specific signals.
Privileged views such as full solutions, partial rationales, final answers, reference code, and feedback can all help, but none is consistently the best. AVSD uses consensus across views as the reliable update direction, then adds a view-specific residual only when it aligns with that consensus and is bounded. The result is a richer but still stable learning signal, leading to consistent gains on several math and code benchmarks across model families for each configuration we test.
🧵👇
10 Projects that will make you master in low level programming.
Start from simple & move up as you go.
You will learn memory management, syscalls, networking, sockets, DB & OS basics.
Google has quietly dropped what researchers are calling "Attention Is All You Need V2."
And it signals the end of the Transformer era as we know it.
In 2017, the original "Attention Is All You Need" paper changed the world by proving that AI doesn't need recurrence, it just needs to pay attention.
But today, even the most advanced models like GPT and Gemini suffer from a massive, structural flaw: Catastrophic Forgetting.
The moment an AI learns something new, it starts losing what it learned before. It’s why AI "hallucinates" or loses the thread in long conversations.
This paper, titled "Nested Learning: The Illusion of Deep Learning Architectures," completely replaces the way AI stores information.
The researchers have introduced a paradigm shift called Nested Learning (NL).
Here is why this is "V2":
For the last decade, we treated AI models as one giant, flat mathematical function. NL proves that a model is actually a set of thousands of smaller, "nested" optimization problems running in parallel.
Instead of one giant "memory," each layer has its own internal "context flow." This allows the model to learn new tasks at test-time without overwriting its core intelligence.
It moves us past the static Transformer. The new architecture (HOPE) demonstrated 100% stability in long-context memory and "post-training adaptation" that was previously impossible.
The technical takeaway is brutal for the competition:
Existing deep learning works by compressing information until it breaks. Nested Learning works by organizing information so it can grow forever.
We’ve spent 7 years trying to make Transformers bigger. Google figured out how to make them "Nested."
The Transformer replaced the RNN in 2017.
Nested Learning is here to replace the Transformer in 2026.
































![AndrewYNg's tweet photo. One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalypse narrative of upcoming job market collapse is false -- there will be many AI and non-AI jobs). However, I believe there will be far more AI Engineer jobs than FDEs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.
Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompting, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
[Original text: The Batch newsletter]](https://pbs.twimg.com/media/HJvWmCHagAAnTxQ.jpg)

























