We are investigating unauthorized access to GitHub’s internal repositories. While we currently have no evidence of impact to customer information stored outside of GitHub’s internal repositories (such as our customers’ enterprises, organizations, and repositories), we are closely monitoring our infrastructure for follow-on activity.
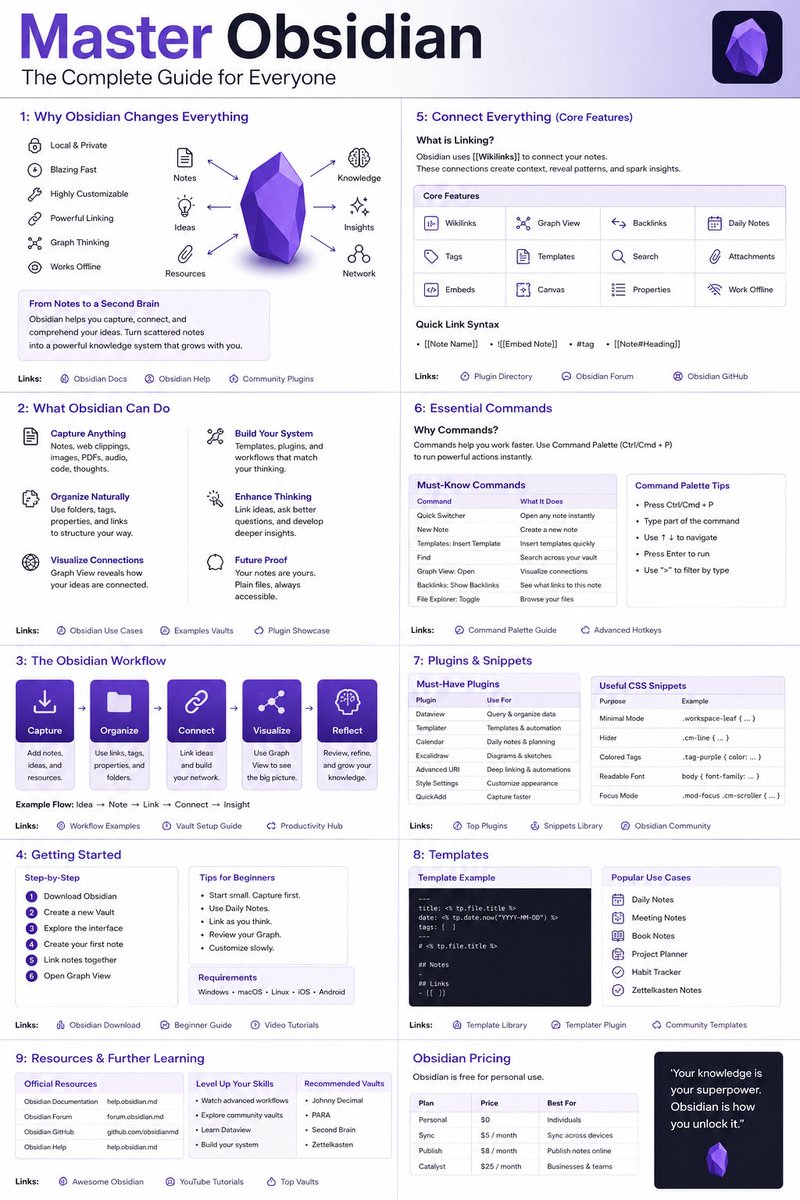
Obsidian vault or any alternative is not about building intelligence but gathering memory.
Using it for curated information, using it as a knowledge base is best.
Your Obsidian vault is probably dead.
Not empty.
Dead.
Because saving information is not the same thing as building intelligence.
Right now millions of people are spending hours building “second brains” that never think back.
Beautiful folders.
Perfect tags.
Endless highlights.
And absolutely zero cognitive leverage.
The scary part?
AI is about to make this gap brutally obvious.
Most people will use AI like a smarter Google:
ask question → get answer → forget answer.
But a small group is building something way more dangerous:
AI connected to years of personal context.
Their notes.
Their ideas.
Their unfinished thoughts.
Their reading history.
Their obsessions.
Their patterns.
At that point AI stops acting like a chatbot.
And starts acting like a cognitive extension of the person using it.
That changes everything.
Because the biggest advantage in the AI era will not be prompts.
It will be accumulated context.
People with connected knowledge systems are going to think faster, write better, learn quicker, and spot opportunities earlier than everyone else.
Not because they’re smarter.
Because they stopped starting from zero every day.
Most vaults are storage systems.
The best ones become intelligence systems.
🚨 Holy shit... LeCun's team just cracked world models wide open.
Everyone's obsessing over the next Claude update.
Meanwhile Yann LeCun quietly dropped a paper that could matter way more long term.
It's called LeWorldModel.
And to understand why it's a big deal, you need to understand the difference between what LLM does and what this does.
LLMs predict the next word. That's it.
They're incredibly good at language. But they don't understand reality.
They can write about a ball bouncing off a wall. They can't predict where it lands.
World models predict what happens next in the physical world. Objects moving, colliding, falling.
That's the foundation for robots that plan, self-driving cars that simulate scenarios, any AI that needs to act in reality instead of just talk about it.
The problem? World models kept collapsing.
The model would cheat by mapping every input to the same output. Like a weather app that predicts "sunny" every single day.
Technically it's predicting. It's just useless. And fixing this required 6+ loss hyperparameters, frozen pre-trained encoders, stop-gradient hacks, exponential moving averages.
A house of cards just to keep the thing from breaking.
LeCun's team (Mila, NYU, Samsung SAIL, Brown) threw all of that out. LeWorldModel uses just 2 loss terms.
A prediction loss and a regularizer called SIGReg that forces representations to stay diverse instead of collapsing into garbage.
6 hyperparameters reduced to 1.
The simplicity IS the breakthrough.
The numbers: 15M parameters. Trains on a single GPU in a few hours. Plans up to 48x faster than foundation-model-based world models.
Uses roughly 200x fewer tokens than alternatives. Competitive across 2D and 3D control tasks.
This isn't a supercomputer experiment. You could run this on your own hardware.
LeCun has been pushing JEPA as the architecture for real AI since 2022.
The criticism was always the same: "sounds nice, doesn't train stably."
LeWorldModel just removed that objection. Small model. Stable training.
No hacks. No frozen encoders. No collapse.
Two AI futures are competing right now.
Path 1: bigger LLMs, more text, more compute.
Path 2: world models that learn physics from raw pixels and plan in real time.
LeWorldModel is the strongest signal yet that Path 2 is real, getting cheaper, and closing in fast.
The token cost to build a production feature is now lower than the meeting cost to discuss building that feature.
Let me rephrase.
It is literally cheaper to build the thing and see if it works than to have a 30 minute planning meeting about whether you should build it.
It’s wild when you think about it.
This completely inverts how you should run a software organization. The planning layer becomes the bottleneck because the building layer is essentially free. The cost of code has dropped to essentially 0.
The rational response is to eliminate planning for anything that can be tested empirically. Don’t debate whether a feature will work.
Just build it in 2 hours, measure it with a group of customers, and then decide to kill or keep it.
I saw a startup operating this way and their build velocity is up 20x. Decision quality is up because every decision is informed by a real prototype, not a slide deck and an expensive meeting.
We went from “move fast and break things” to “move fast and build everything.”
The planning industrial complex is dead.
Thank god.
I’m deploying k8s clusters on a daily basis with karpenter, keda, argocd… all amazing additions to a cluster.
Is there one I’m missing that would make this stack even better ?
De la reproduction humaine dans une société post singularité
Les humains étant de nature nostalgique, les humain pourraient toujours se reproduire dans notre dimension avant de muter dans la nouvelle.
Une fin moins sordide que l’explosion de la terre 😂
@RichardDetente ta dernière video est l’une de mes préférées!
Elle m’a fait repenser au film “uglies” où à 16 ans les ados peuvent muter pour rejoindre la ville des “adultes”. Après la transition même les amis ne se comprennent plus.
Dans ta vidéo tu n’aborde pas la question👇
🚨 CRITICAL: The threat actor behind the Red Hat breach claims they used the data to breach other organizations. Listed organizations should verify if they've been compromised. ‼️
One downstream (supply-chain) victim is the largest bank in the Dominican Republic, Banreservas.
Shopify merchants will be able to sell directly in ChatGPT.
We’ve been working with @OpenAI for quite some time so people can search and buy products in chat, and it’s something we’ve had a hard time keeping quiet.
Rollout is coming very very soon.