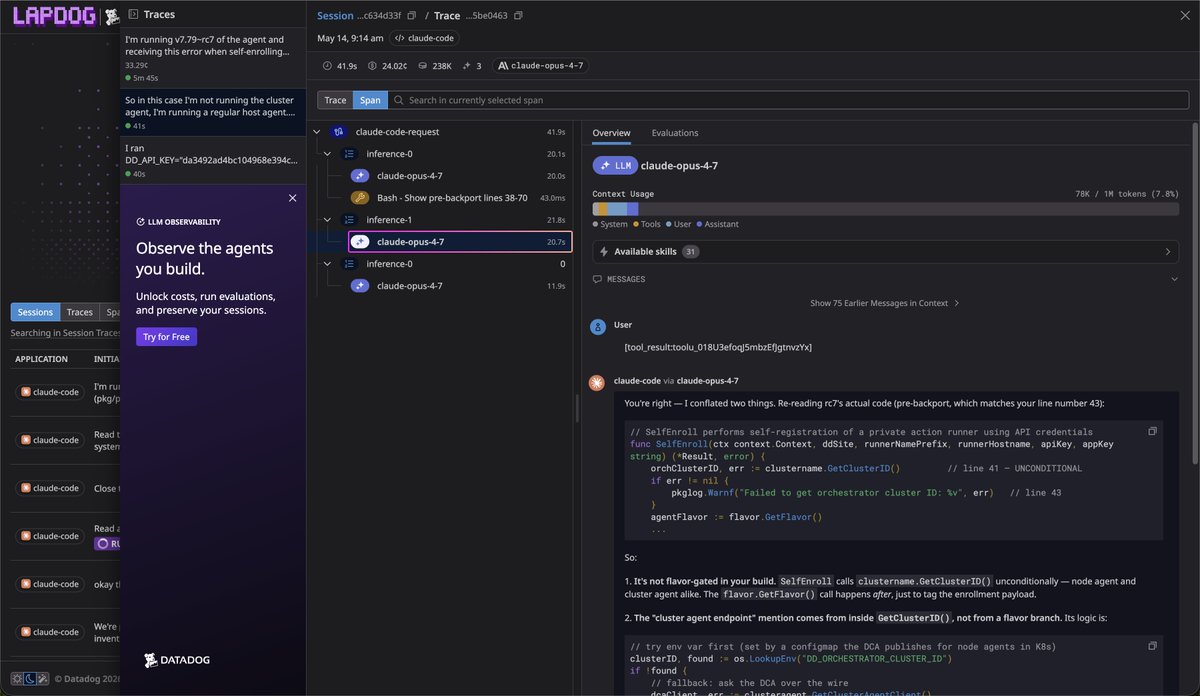
NEW from Datadog: it's Lapdog!
Ever wondered what your AI agent was actually doing?
Our latest free project runs locally and traces reasoning and tool calls in Codex, Claude Code, and Pi.
You can now see what your agent is REALLY doing, live: https://t.co/3dVBozFlPx
@thdxr Every day
1: billing
2: dynamodb
3: cloudwatch to search logs or because for some reason the sst console is not showing the log / showing with too much delay.
@ryanflorence@SurelyAutomata Funny I came up with a similar solution but you don’t really need to do breadth first if you’re going to save the level of each node in a separate structure. You can do depth first without a queue and get the same result (with a bit less complexity)
@thdxr Maybe unrelated to what you are building but I wish I had a good library for notifying the user when I start a long running job. It would notify with websocket or SSE and fallback to email is user is disconnected.
@thdxr Migrating to app router is not that hard, but one of our app does not benefit at all from that migration because it uses stitches and it’s not really compatible with app router.
@thdxr Nooo what you really need is to monkeypatch fetch into a centralized s3 cache so that your dropdown component can render nice looking skeletons while fetching available log levels
@jayair Yes this makes sense when you really want to keep your data in a database that has no vector search built in like dynamo but many search engines / databases are adding vector search and it makes a separate vector database redundant. I ditched pinecone when typesense added vectors
@jayair I think this setup could be improved if you could retrieve the actual data you are searching for instead of just retrieving the ids and then getting the data from dynamo with a batchGet. Vector search should just be one way to query your data, not a completely separated system.