Help us reach 2 million followers for the 80th anniversary of the liberation of Auschwitz.
Every repost, comment, or like increases our visibility.
Amplify our voice, please.
How to best evaluate LLM answers?
We introduce SemScore, a very simple automatic evaluation method using semantic textual similarity. Despite its simplicity, we find it correlates surprisingly well to human judgment. Try it out!
Paper: https://t.co/UNH5tDHwwS
I wrote a detailed overview of #recsys2023, including state of the research, our contributions, top5 paper picks (& short summary of 11 other papers), workshops and the conference in general. Available on my new blog: https://t.co/je9EiTeDIK
HUGE announcement from @stephen_wolfram - ChatGPT+Wolfram integration announced 2 hours ago. Here is our conversation with Stephen about it. https://t.co/bdJKte6EWA
Good paper from Tobias Deußer and @cbauckhage et al. about contradiction detection in financial reports. Interesting to see that LLMs fine-tuned on financial data are outperformed by a bigger but non-specialized XLM-Roberta model #nlproc https://t.co/iGHgPp2lnV
I think systems like ChatGPT would be a lot less controversial if they cited references.
Eg when querying “What are the origins of AI”, sure have it provide a summary. But also append the sources where it learned this info from. To a) give credit & b) so we can validate the info
New open-source language model from Google AI: Flan-T5 🍮
Flan-T5 is instruction-finetuned on 1,800+ language tasks, leading to dramatically improved prompting and multi-step reasoning abilities.
Public models: https://t.co/bnYVnocJW2
Paper: https://t.co/3KPGJ3tgMw
Heute Klassenarbeit (D|Jg. 8), in der die Schüler:innen #KI Schreibtool frei nutzen konnten.
Sie erstellen mit https://t.co/0L9KHJ5hWG eine Argumentation und entscheiden, welche Textteile sie von der KI übernehmen und welche Passagen sie lieber eigenständig verfassen. (1/4)
#twlz
If you feel you are "stuck in a loop" in your research, you may not actually be doing anything wrong. I am looking towards sharing my ideas about which parts of good research require iteration. @sigmm@acmmm2022
We are looking for posters/demos of AI-related research to be featured at @SFI_NorwAI Innovate 2022 https://t.co/uMXHLwpUOh CFP here: https://t.co/yLfQXd1D5t
A piece by Jake Browning and me (mostly by Jake) in the philosophy magazine Noema about AI and human intelligence, and walls not being hit by the former on the way to the latter.
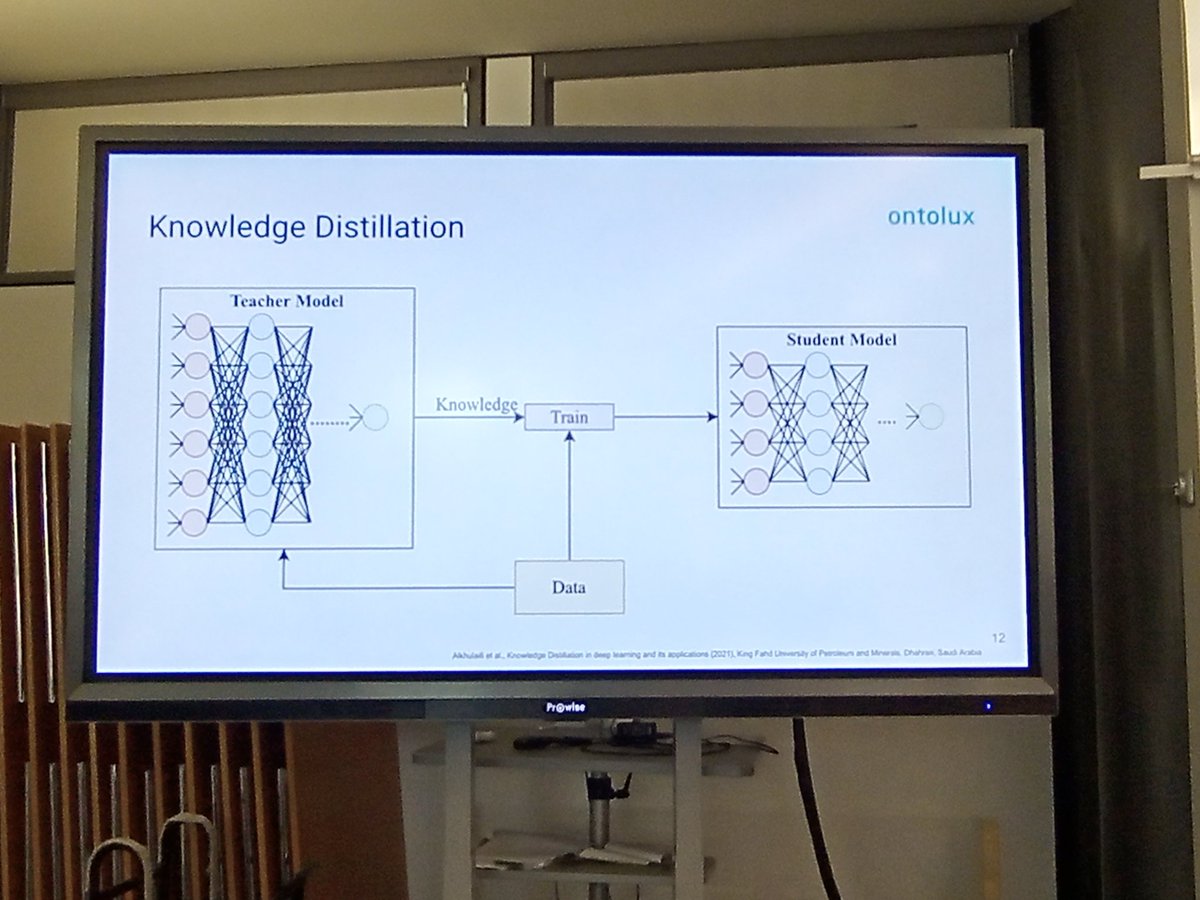
Exponentiell wachsende ML-Modelle brauchen viel Energie. Statistikerin und ML Engineer Qi Wu von @neofonie erklärt Methoden der Modellkomprimierung: neben #Finetuning, #Pruning und Low Rank Factorisation gibt es Knowledge #Destillation mit Teacher- und Student-Modellen
#m3_2022
Qi Wu von ontolux: KI-Agentur für Text Mining und Suche erläutert in ihrem Vortrag bei der
@M3_Konferenz wie mithilfe Knowledge Destillation eine deutliche Ressourceneinsparung bei KI-Modellen gelingen kann. https://t.co/04LXBxmslI
#NLP#AI#m3_2022
ontolux, Marke der Neofonie ist bei der
@M3_Konferenz am 02.06.22 vertreten mit einem Vortrag zum Thema: Methoden zur Ressourceneinsparung von KI-Modellen mittels Knowledge Destillation durch Qi Wu #m3_2022#MachineLearning#KI#AI#Ressourceneinsparung
https://t.co/04LXBxmslI
OPT-175b:
Open Pre-Trained language model with 175 billion paramaters is now available to the research community.
Blog post: https://t.co/NBacfKGUHC
Paper: https://t.co/tLYUoWisZA
Code + small pre-trained models: https://t.co/M9nLCOf3Rx
(using OPT-175b requires a registration)