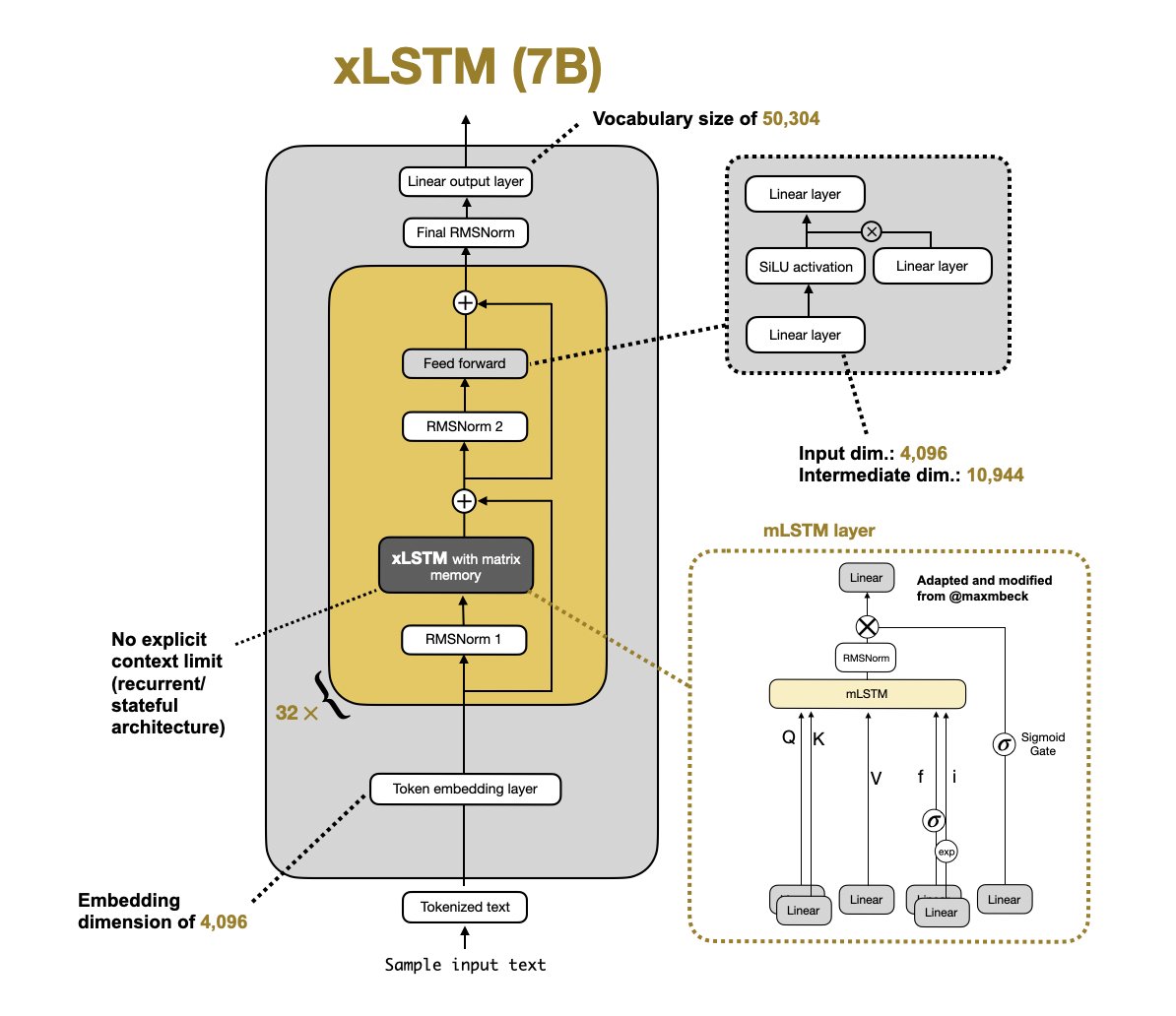
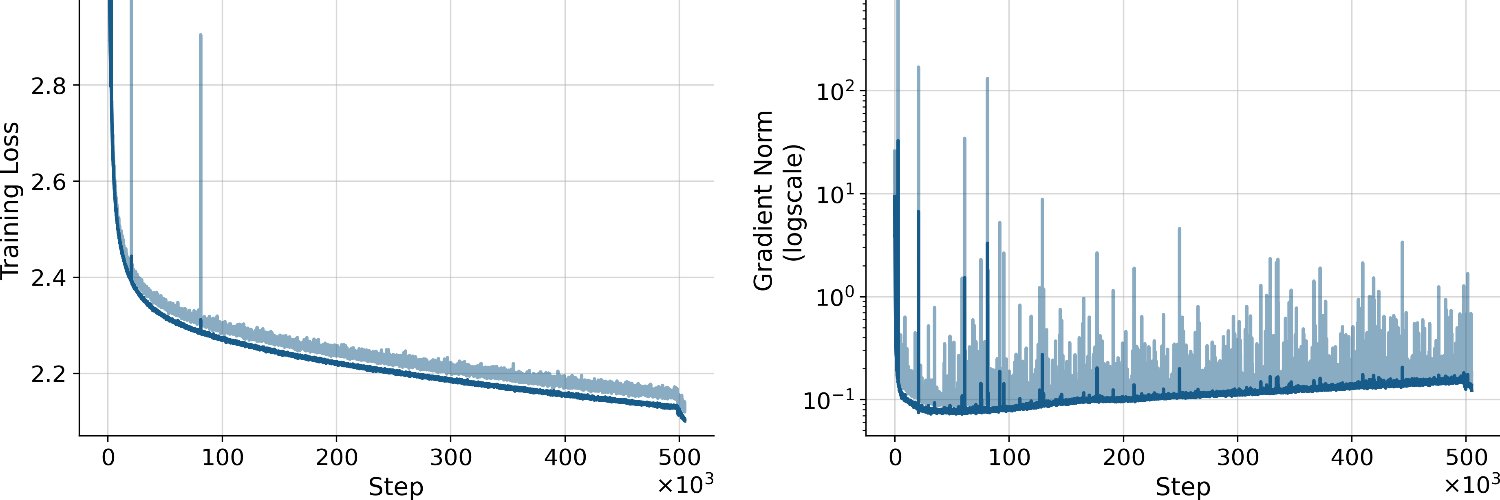
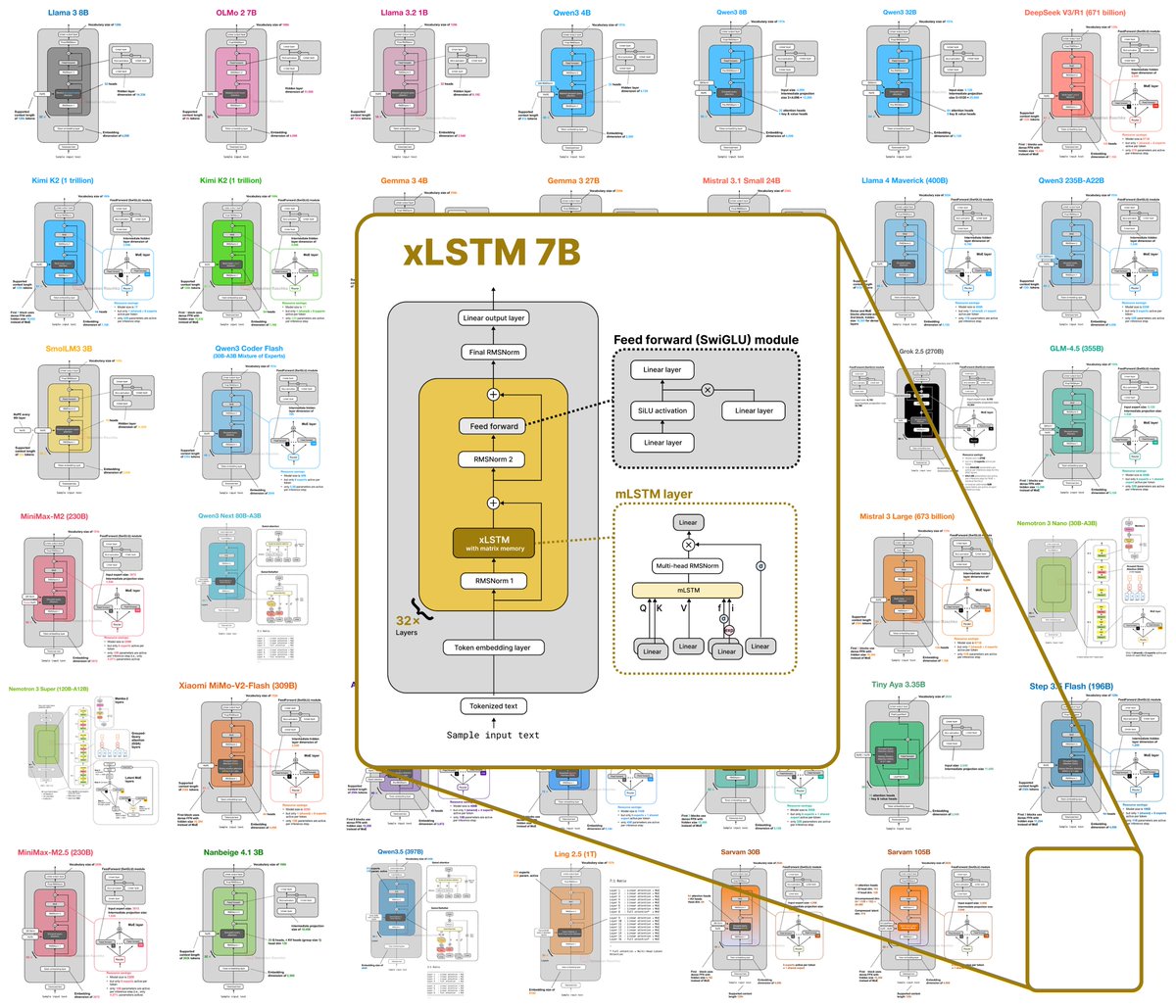
Yesterday, we shared the details on our xLSTM 7B architecture. Now, let's go one level deeper🧑🔧
We introduce
⚡️Tiled Flash Linear Attention (TFLA), ⚡️
A new kernel algorithm for the mLSTM and other Linear Attention variants with Gating.
We find TFLA is really fast!
🧵(1/11)
We unlocked the working memory of LLMs 💥
Reasoning in Memory (RiM) replaces autoregressive "thinking out loud" with fixed memory blocks that form a task-specific workspace for latent reasoning.
The key idea is simple: reasoning should happen inside the LLM, not in its output!
Life update: A few weeks ago, I moved to Paris 🇫🇷 to start a new position as AI Scientist at Meta FAIR. I am excited about this new chapter and look forward to the opportunities ahead.✨
Recipes for teaching language models to handle long inputs don't work equally well across model families.
We wanted to know why—is it the architecture, the training data, or both? 🧵
RNNs like xLSTM with vertically chunked inference strategy for efficient memory: https://t.co/YX6UPapx6Q
Chunking enables a linear-time and constant-memory like TFLA for xLSTM https://t.co/1oZu9p3ydO
To chunk blocks via recurrent updates and speed up computation considerably.
We’ve released 35 xLSTM checkpoints from our scaling law study, spanning 160M to 7B parameters and trained on 3B - 1.5T tokens from the DCLM dataset.
https://t.co/RR9YC1KvKW
🚀 Excited to share our new paper on scaling laws for xLSTMs vs. Transformers.
Key result: xLSTM models Pareto-dominate Transformers in cross-entropy loss.
- At fixed FLOP budgets → xLSTMs perform better
- At fixed validation loss → xLSTMs need fewer FLOPs
🧵 Details in thread
These checkpoints come from our token-per-parameter training setup and are fully compatible with the xLSTM-7B Hugging Face implementation:
https://t.co/hUj3TqJbp8
Now, I’m looking forward to a relaxing Easter break and I’m excited for what comes next 🚀
📄 Thesis: https://t.co/Ai5xDZ44eO
🎤 Defense slides: https://t.co/k0vtzLnsLX
👨🎓Last week, I successfully defended my PhD thesis - an incredibly exciting and rewarding milestone after 3.5 years of work on
xLSTM: Recurrent Neural Network Architectures
for Scalable and Efficient Large Language Models
And of course many thanks to @KorbiPoeppel for being an amazing co-author on nearly all xLSTM papers.
I also want to thank all collaborators, friends, and family for their support.🤗
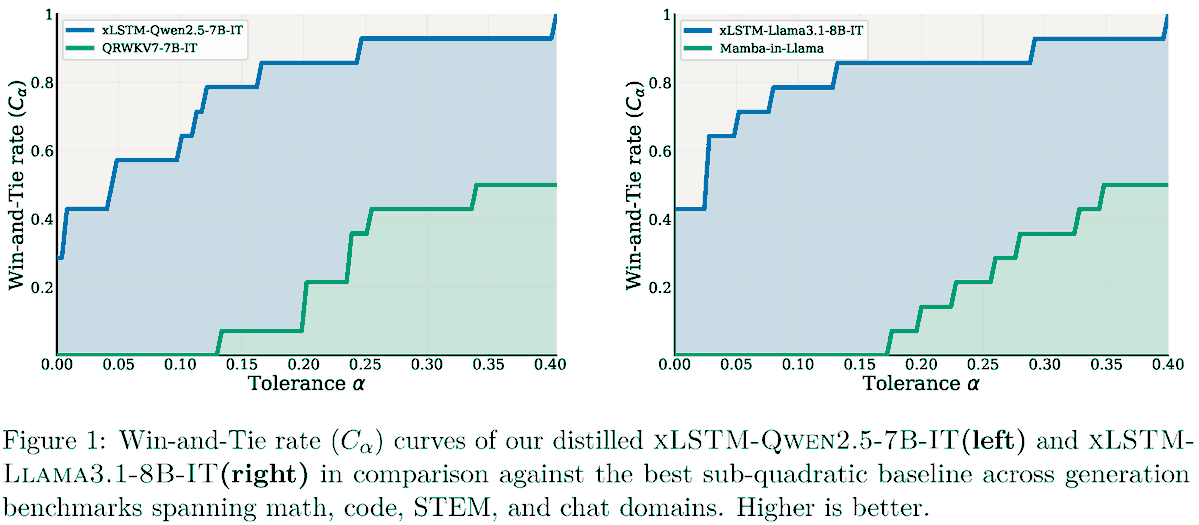
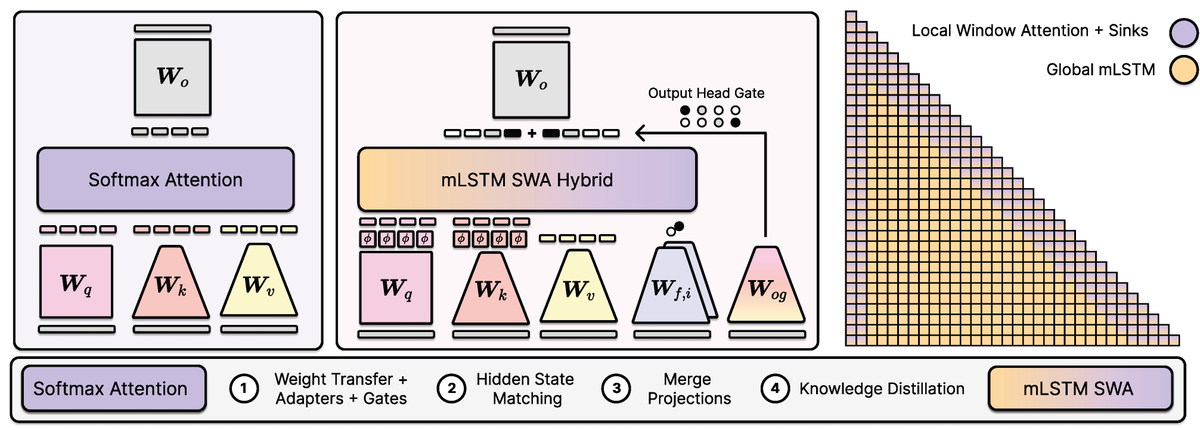
Excited to share our new paper: Effective Distillation to Hybrid xLSTM Architectures.
TL;DR: we retrofit / graft / distill / linearize Transformers into xLSTM-SWA hybrids with fixed-size states.
This gives a practical path to studying linear and hybrid architectures starting from already strong pretrained models.
xLSTM Distillation: https://t.co/iBIJzGbzXX
Near-lossless distillation of quadratic Transformer LLMs into linear xLSTM architectures enables cost- and energy-efficient alternatives without sacrificing performance.
xLSTM variants of instruction-tuned Llama, Qwen, & Olmo models.