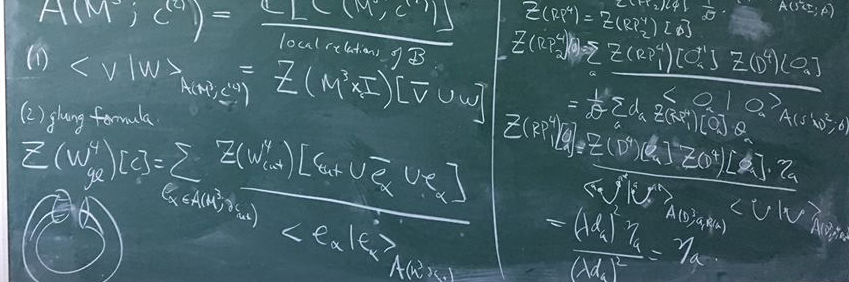MTS at Anthropic. Professor of Physics at University of Maryland. Fellow, Joint Quantum Institute. Ex -Berkeley, MIT, Stanford, Microsoft Station Q, Meta FAIR
An absolutely incredible, highly interconnected web of ideas connecting some of the most important discoveries of late twentieth century physics and mathematics. This is an extremely abridged, biased history (1970-2010) with many truly ground-breaking works still not mentioned:
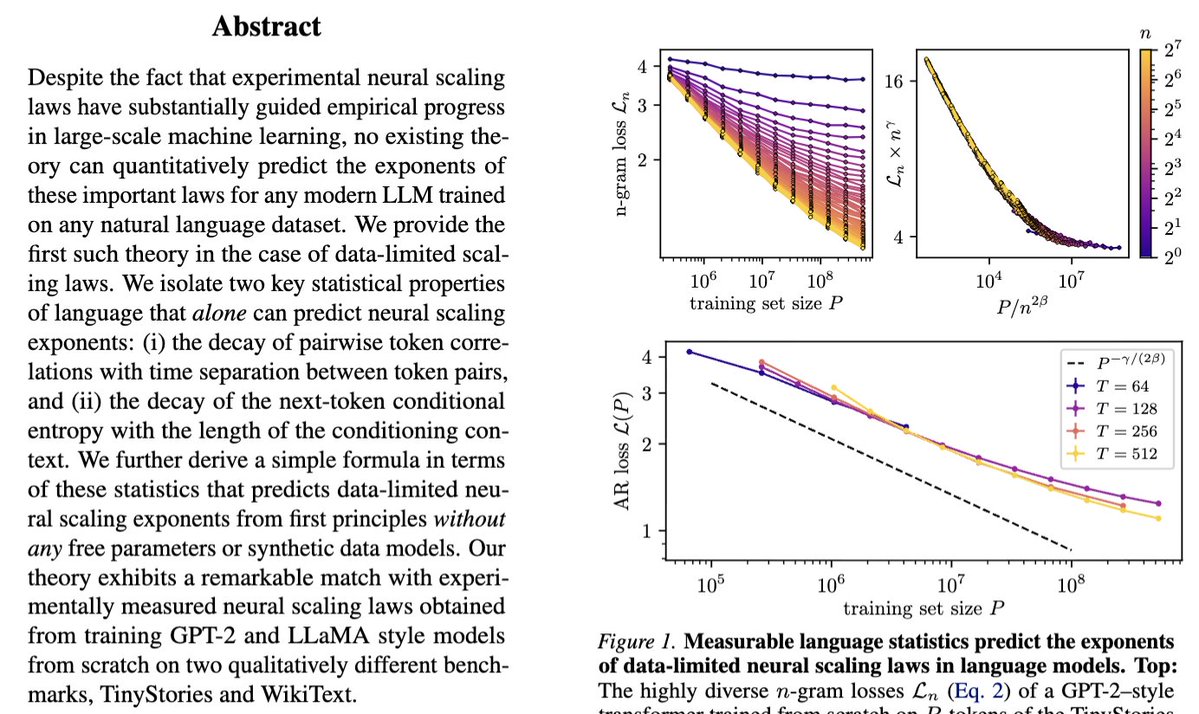
Our new paper "Deriving neural scaling laws from the statistics of natural language" https://t.co/7QbrldK8Zp lead by @Fraccagnetta & @AllanRaventos w/ Matthieu Wyart makes a breakthrough! We can predict data-limited neural scaling law exponents from first principles using the structure of natural language itself for the very first time!
If you give us two properties of your natural language dataset:
1) How conditional entropy of the next token decays with conditioning length.
2) How pairwise token correlations decay with time separation.
Then we can give you the exponent of the neural scaling law (loss versus data amount) through a simple formula!
The key idea is that as you increase the amount of training data, models can look further back in the past to predict, and as long as they do this well, the conditional entropy of the next token, conditioned on all tokens up to this data-dependent prediction time horizon, completely governs the loss! This gets us our simple formula for the neural scaling law!
Nice to make some progress on a basic topic in theoretical physics -- universal response of emergent Dirac fermions to crystal defects. Now published in @PhysRevX , with @ZoharKo , @CFechisin , Siwei Zhong. @JQInews@UMDPhysics
By studying how symmetries of lattice models map to symmetries of continuum theories that
emerge at criticality, researchers show that the (2+1)D Dirac fermion exhibits a continuum of infrared fixed points at a particular applied magnetic flux.
https://t.co/ZviF6Ra7dh
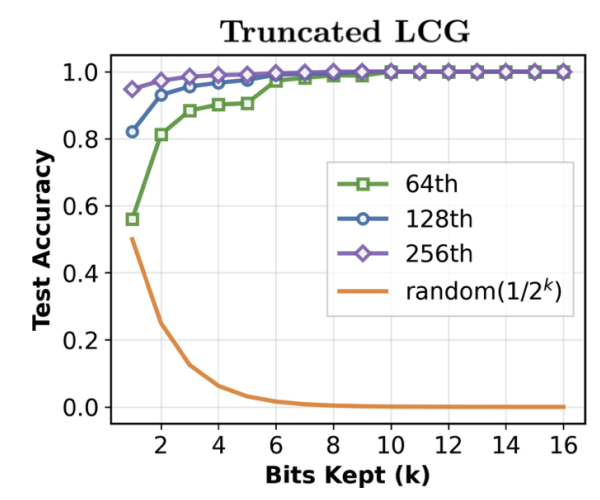
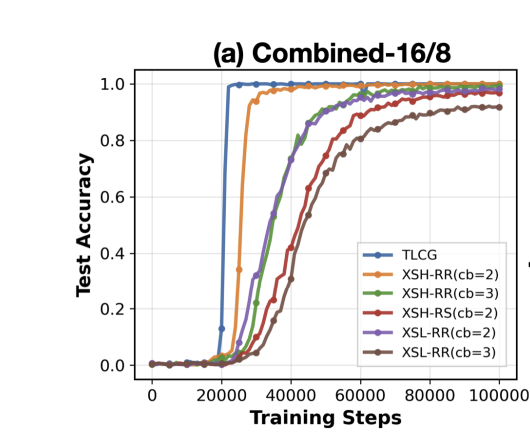
Our ICLR 2026 paper shows how transformers can learn pseudo-random numbers.
We demonstrate successful in-context prediction of pseudo-random sequences from permuted congruential generators, which are used in practice in NumPy. We succesfully attacked PCGs with moduli up to 2^22.
Surprisingly, the transformer can learn the sequence even when only one bit is output from the hidden state.
We found that curriculum learning is essential for these problems.
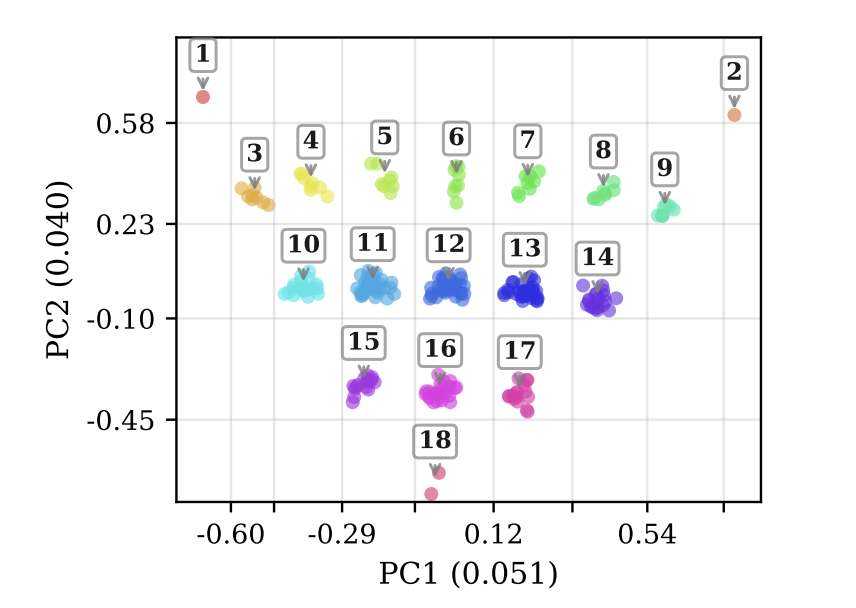
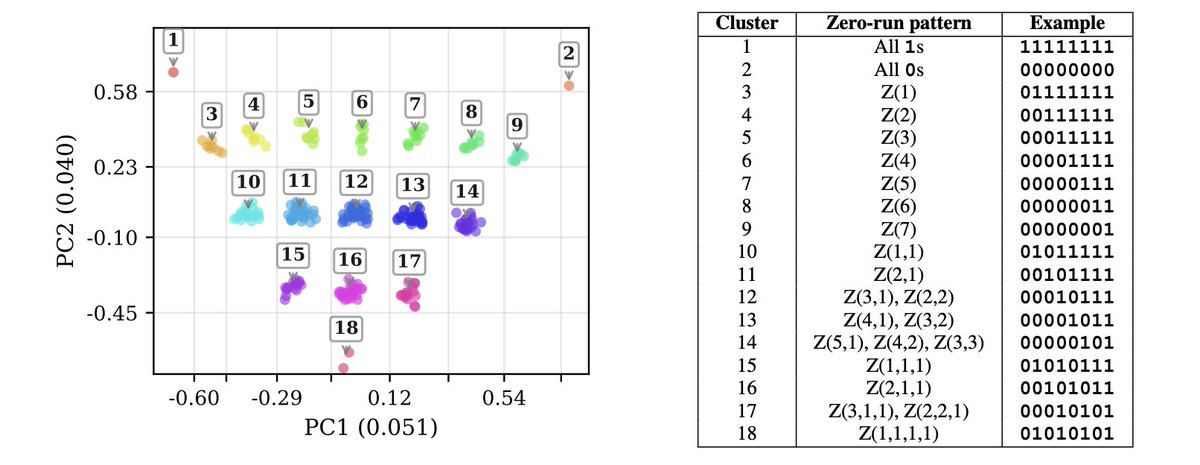
We also found novel structures in the embedding layers: the model spontaneously clusters numbers according to how their bit strings transform under rotations.
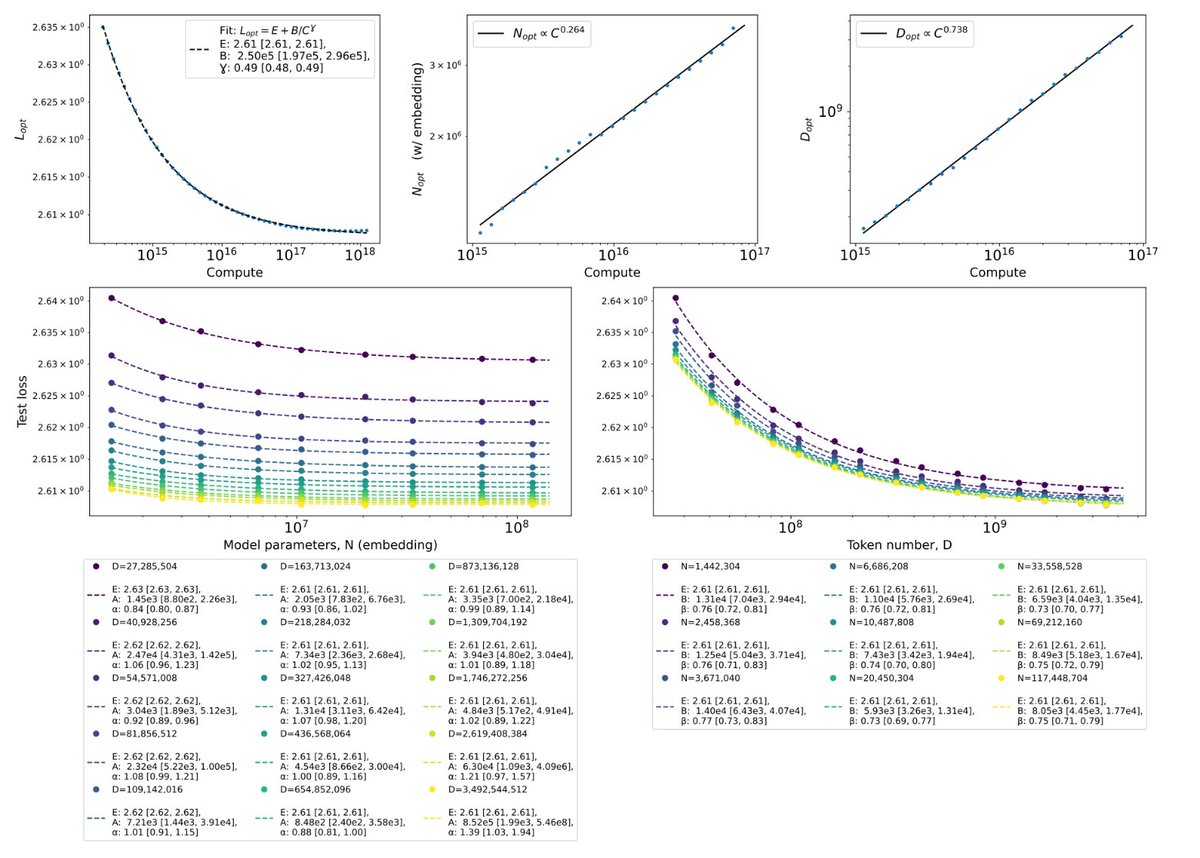
Scaling laws in AI – where do they come from?
The discovery of neural scaling laws several years ago showed that the loss decreases predictably as a power law in model size, amount of data, and compute. But why? And what sets the exponents of the power law?
The most popular explanation is that the dataset already has power law correlations in it (for example, power laws are prevalent in natural language corpora, e.g. Zipf’s law, etc), which translate to power laws in the loss.
We studied transformers performing next token prediction on sequences coming from random walks on random graphs, where the data has no power law correlations. Nevertheless, after training the model, we observed power laws in the loss that look similar to those found in natural language. For example, here are results from a random walk on an Erdös-Renyi graph with 8K edges and 50K nodes:
This challenges existing explanations, since this dataset of random walks falls outside of the assumptions made in existing models of scaling laws. Going forward, we need explanations of scaling laws based on expressivity and learnability of discrete data, where there is no data manifold, and which do not require the data to already have power laws built in.
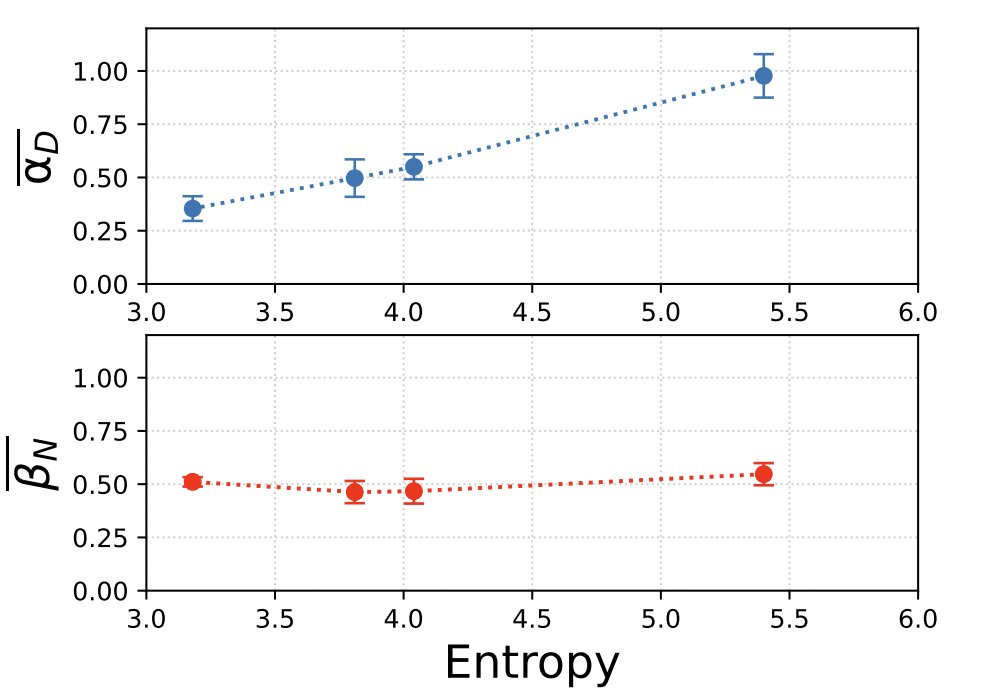
We also found a setting where we could tune the complexity of a language dataset by starting with a bigram model and gradually dialing up complexity until we get to natural language. This allowed us to track how the exponents of the scaling laws change with complexity:
We have 14 survey lectures for our @SimonsFdn Collaboration on the Physics of Learning and Neural Computation! All videos available at: https://t.co/MLnVYY6Fhh
Here is the list:
@zdeborova: Attention-based models and how to solve them using tools from quadratic networks and matrix denoising
@KempeLab: Recent lessons from LLM reasoning
@MBarkeshli: Sharpness dynamics in neural network training
@KrzakalaF: How Do Neural Networks Learn Simple Functions with Gradient Descent?
Michael Douglas: Mathematics, Economics and AI
Yuhai Tu: Towards a Physics-based Theoretical Foundation for Deep Learning: Stochastic Learning Dynamics and Generalization
@SuryaGanguli: An analytic theory of creativity for convolutional diffusion models
Eva Silverstein: Hamiltonian dynamics for stabilizing neural simulation-based inference
@adnarim066: Generation with Unified Diffusion
Bernd Rosenow: Random matrix analysis of neural networks: distinguishing noise from learned information
@jhhalverson Nerual networks and conformal field theory
@KempeLab Synthetic data: friend or foe in the age of scaling
@WyartMatthieu Learning hierarchical representations with deep architectures
@CPehlevan Mean-field theory of deep network learning dynamics and applications to neural scaling laws
Thank you so much to everyone for this wonderful dinner! I’m truly grateful to Harvard University CMSA for this amazing experience. It makes me so happy to see the Math & AI community growing, can’t wait to see all the incredible things these brilliant minds will create together
A nice @Stanford news report on how university research is essential for understanding AI and sharing these insights openly with the world. https://t.co/l252TS6ro1
Under the leadership of @Stanford's @SuryaGanguli, our new Simons Collaboration on the Physics of Learning and Neural Computation will study the fundamental scientific principles underlying AI: https://t.co/XXIAX0OWvM #science
Our new Simons Collaboration on the Physics of Learning and Neural Computation will employ and develop powerful tools from #physics, #math, computer science and theoretical #neuroscience to understand how large neural networks learn, compute, scale, reason and imagine: https://t.co/fqNqtJjWKg
1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).
🤖 Transformers can write poetry, code, and generate stunning art, but can they predict seemingly random numbers?
We show that they learn to predict simple PRNGs (LCGs) by figuring out prime factorization on their own!🤯
Find Darshil tomorrow, 11am at #ICML2025 poster session!