Introducing @memgraphdb Zero and our first associated product: MemGQL -> https://t.co/TdF3mKjpFy
Query (you or your agent) all of your data source as a graph. Live. No ETL. No pipelines. No stale data.
One GQL query. Every backend. Zero copies.
Join our Community Call to learn more -> https://t.co/jhJGtNzOdt
#graphs #GQL #agents
Mapped Memgraph's dependency structure as 3 graphs: CMake, Ninja, and Conan. Useful split for finding architecture coupling, rebuild chokepoints, and third-party package risk in a large C++ codebase.
https://t.co/9DS6qRVtj6
We built the Graph of public skills -> https://t.co/EFJHg9ioJ0
From a non-technical standpoint, Agent Skills are the procedural memory you keep in your head on how to solve a particular problem, which can be very valuable, whether you are aware of that or not. You are constantly adapting and changing that procedural memory since the task is usually not fully deterministic, hence it cannot be a script. Parallel to that, skills have caused some controversy for being a security vulnerability and hallucinated LLM brain fog, but more on that in the future. Staying on the positive side of things and ignoring the negatives for now, agent skills could hold all the operational knowledge, allowing agents to operate semi-autonomously or autonomously to solve the particular operational problem. An example of that would be compiling a Memgraph Rust query module, which is not an easy task since you need the environment, the Memgraph query module API dependency, and knowledge of how to actually do it. Most advanced LLMs, like Codex or Opus, succeed at this after many tries and failures. This is why we build skills for compiling and deploying C++, Rust, and Python query modules that let LLMs practically single-shot the whole process. Back to the topic of the graph of skills, what is the actuall problem here? So if you have hundreds or thousands of skills in your organisation, the question is: how are you going to maintain them, how will they learn and evolve, and how will agents access them? If the tool's API changes, so should the skills, which causes a cascade of events across the files. Then the question becomes: how are those connected and correlated? This is what graphs as a structure are built for, and this is what we in Memgraph are trying to solve from different angles. The graph of skills will serve as our test bench for running the evolution, traceability, and access to the skills, while improving @memgraphdb as the graph database that serves as a real-time context engine for AI.
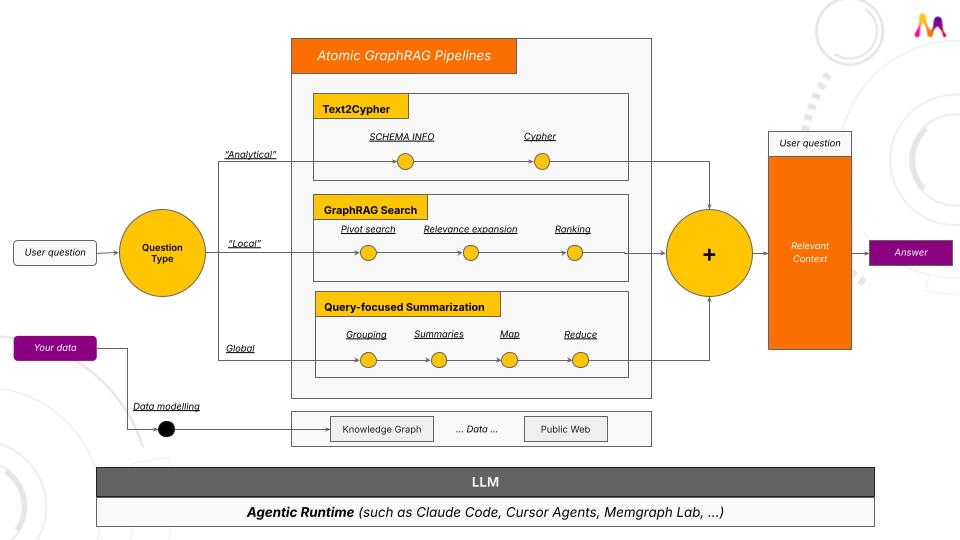
Atomic GraphRAG 👀
What if the entire GraphRAG could run as one query instead of a chain of code steps?
Less orchestration, code, and prompt bloat.
More speed, control, and traceability.
Details: https://t.co/RdsTL2wZBc
#GraphRAG#GenAI#LLM#GraphDatabase#Cypher@memgraphdb
@gudjon@_avichawla Hey @_avichawla and @gudjon - I'm the CTO of Memgraph. I just saw the question. I'd be happy to show and tell you more - would you be up for that?
@MemgraphDB v3.8 is live 🚀 introducing Atomic GraphRAG! 👀
Now you can combine searches and knowledge graphs in a unified execution layer, the details under https://t.co/j1aksFYn1j
Want to see it in action? Join https://t.co/hHFCyWUiha
#GraphDB#GraphRAG#AI#Agents
Did some experiments on how much it costs to extract entities from text (without prior ontology), seems like by default (gpt_4o_mini, without parallelization, 3-4 paragraph pages) the cost per page is ~0.01 USD 👀 Does that sound right? 🤔
I just used Code-Graph to ingest the Linux Kernel into @memgraphdb. The knowledge graph has around a million graph entities representing code structure.
It would be interesting to see how much @rustlang will eat into the kernel over time. 🤔 🦀
Reading about Memgraph today.
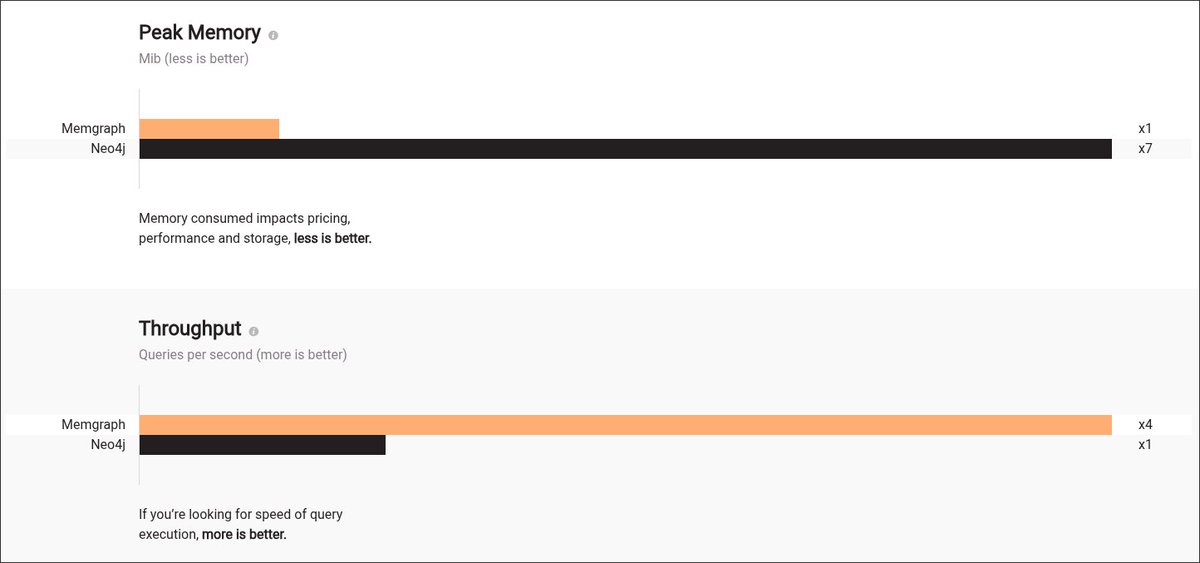
Though, a lot of people use Neo4j, I feel Memgraph don't get the recognition it deserves.
Memgraph is created in C++ while Neo4j is in Java which makes it a faster alternative.
For faster query execution and a large number of nodes, Memgraph is clearly a winner.
Finally! A RAG over code solution that actually works (open-source).
Naive chunking used in RAG isn't suited for code.
This is because codebases have long-range dependencies, cross-file references, etc., that independent text chunks just can't capture.
Graph-Code is a graph-driven RAG system that solves this.
It analyzes the Python codebase and builds knowledge graphs to enable natural language querying.
Key features:
- Deep code parsing to extract classes, functions, and relationships.
- Uses Memgraph to store the codebase as a graph.
- Parses pyproject to understand external dependencies.
- Retrieves actual source code snippets for found functions.
Find the repo in the replies!
On the other hand, since it's super easy to generate new code, I can imagine one building a totally new app when requirements change, basically eliminating long-term software maintenance challenge 🤯