I spent $30k and 3 months RL post-training an anime video model.
This is only step 30 out of a planned 1000 step run.
All samples are local text-to-video with no reference image/audio. Since it's based on LTX-2.3, each output takes under a minute on a single GPU.
I'm 19 and a solo researcher. Most of the budget went into ablations, reward design, and trying different configurations before reaching this setup.
The run is still extremely early, but the results already look much better than I expected.
It's compute-limited, not idea-limited.
I'm starting a company to continue scaling this and build frontier stylized video models.
If you're an investor, compute partner, video team, or someone who wants to help build this, DMs are open.
Looking for a co-founder to build the next generation of waifu tech! Figured out the solution to create a new interactive experience but struggle with app dev.
Kind of the downside of focusing too much on ML.
Ideally someone with mobile/web and maybe some cloud ML experience.
I've set out some conditions for any future solvers to add:
• No implicit solvers: those require root-finding, meaning a Jacobian has to be computed by running a backward pass through the model during LBFGS optimization.
• No non-RK methods: this would cut off linear multistep methods like Adams-Bashforth or Adams predictor-corrector. From my testing, RK methods perform better, even for explicit RK vs. predictor-corrector linear multistep.
• No duplicate methods: if two methods have different coefficients, they aren't duplicates (scipy methods have different coefficients and solver implementations).
That means the current 31 solvers are almost all that exist to satisfy the conditions above.
Project's done! I need to figure out what to make next.
Last major update!
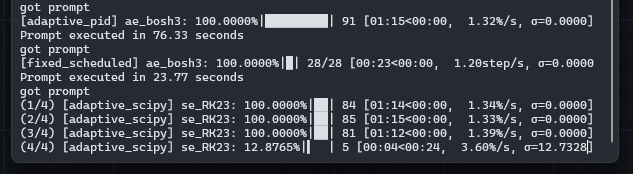
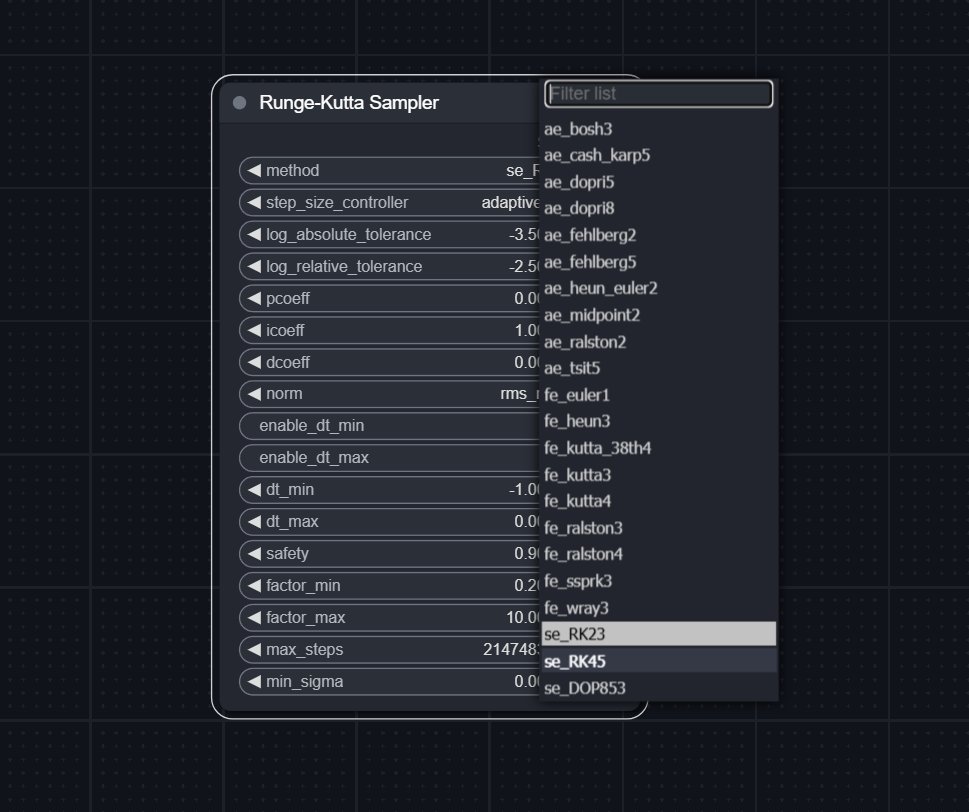
• Added solver settings for adaptive_scipy
• Adaptive solvers now show the number of steps taken
• Accurate 𝜎 timestep info is now displayed
Check out the most comprehensive fixed and adaptive higher-order samplers on ComfyUI!
https://t.co/zF59104pqH
Refactored and fixed some bugs with the progress bar!
Also wrapped the solvers from scipy.integrate
If you count the a-methods as 2 (since they work with both the adaptive_pid and fixed_scheduled controllers), then this node has (excluding forward euler)
31 new samplers!
I also tried the implicit solvers and they didn't work.
Every implicit solver has a root find step, and that takes forever to converge.
That leaves 3 new methods from scipy: se_RK23, se_RK45, and se_DOP853.
I think this node has the most new working samplers for ComfyUI (a for adaptive, f for fixed, s for scipy, e for explicit).
While trying to push the CFG scale up, I implemented some Explicit RK solvers for ComfyUI
- 10 new adaptive step samplers
- 8 unique fixed step samplers (excluding forward euler)
- Best new sampler (perhaps) -> fe_ralston3
Check it out!
https://t.co/e1hXdr1nUJ
i have an idea for a slightly modified class of SDXL models that would mostly be compatible with existing finetunes and loras
it's been proven to work well on SD1.5 with good results
definitely next on my bucket list
will post updates and releases soon, hopefully, if it works
diffusion models are definitely still not dead. sure, optimal transport conditional flow matching is provably better, but so much of the community was already built on discrete time diffusion.
and with kolors out (an SDXL model trained with DDPM formulation and eps-pred objective). i doubt the switch from diffusion to OT-CFM will affect the quality as much as the other techniques shown in the technical report.
if they made kolors work with the SDXL architecture, then it's shown that hybrid transformer-UNets are still competitive. they might just not scale as well as pure DiTs.
i'd like to continue working on anime animation tech. version 1 is designed to be distilled for realtime inference. version 2 won't be concerned with realtime inference and would probably be based on a flow-matching mmdit with more fine-grained control and even better quality.
training is done in 2 days!!!
as for inference compute requirements: it's basically the same burden as animatediff
will probably work on realtime inference next month after figuring out life. realtime txt/vid2vid on distilled models is already empirically shown to be possible.
@EsotericCofe@anifusion_ai Not realtime yet (still in roadmap) but we could get this deployed on anifusion before.
The pose sequence is derived from mocap data from XR Animator, but we can probably work out a custom pipeline.