Your drifting model is secretly a fixed point for the Wasserstein gradient flow on...
...the KL?
...an approximation to the Sinkhorn?
...Is it even a Wasserstein gradient flow at all?
https://t.co/QJLh86Hi0d
@liwenliang@agalashov@JamesTThorn@ValentinDeBort1@ArnaudDoucet1
Inductive biases in the training process cause the formations of attractors in the latent vector field, characterizing memorization and generalization regimes of the network.
The Brain May Have Been Critical Before It Became Predictive: Self-Organized Criticality and the Physical Basis of Action-Readiness
https://t.co/8PP8WguoKS
Tutorial article: "Energy-Based Dynamical Models for Neurocomputation, Learning, and Optimization" (by Arthur N. Montanari, Francesco Bullo, Dmitry Krotov, Adilson E. Motter): https://t.co/C8sieU71Gp
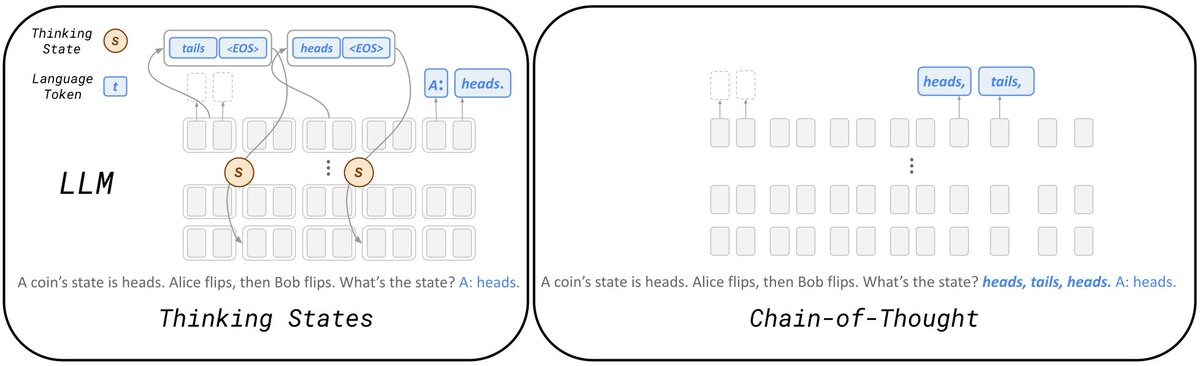
Can LLMs reason internally while processing their inputs, similar to how humans can think ahead as we process information? Our latest work introduces Thinking States, a novel architectural adaptation that transforms reasoning into a internal recurrent process.
By training models to maintain a dynamic thinking state, we achieve significant inference speedups over Chain-of-Thought while substantially outperforming existing latent reasoning methods.
Paper: https://t.co/nXJ9szfbrT
It's time to bring 3D meshes into modern machine learning properly! 🛸 Our work solves the non-differentiability of the Exp map on meshes, enabling gradients to flow directly through geodesics. It’s differentiable, GPU-fast, and fully parallelised.
https://t.co/2G5Q7zrck3
1/ As AI agents become increasingly capable, what must *inevitably* emerge inside them?
We prove selection theorems: strong task performance forces world models, belief-like memory and—under task mixtures—persistent variables resembling core primitives associated with emotion.
Meet the winners of The Brain Prize 2026.
The announcement film introduces Professors David Ginty and Patrik Ernfors, awarded the prize for their groundbreaking discoveries on the neuroscience of touch and pain.
Learn more about the winners:
https://t.co/eTGOMwfmqO
One of the most-viewed PNAS articles in the last week is “Quantifying the compressibility of the human brain.” Explore the article here: https://t.co/HsWpARBhH4
For more trending articles, visit https://t.co/l4XOkRLLmY.
Our work, "A Primer on SO(3) Action Representations in Deep Reinforcement Learning," was accepted to #ICLR2026! We provide a systematic study of action representation choices in RL, showing that they fundamentally impact training stability and performance.
#Robotics#AI#RL
First empirical study on how developers are actually writing AI context files across open-source projects.
Researchers scanned 10,000 repositories and found only 466 (5%) have adopted AI configuration files like AGENTS dot md, CLAUDE dot md, or Copilot instructions.
Why does it matter?
Of the 155 AGENTS dot md files analyzed, 50% were never modified after the initial commit. Only 6% had 10 or more revisions.
The most common content in these files were conventions, contribution guidelines, and architecture overviews.
But there is no standard structure, wide variation in what teams encode, and most files are written once and left to decay.
The conventions for this new form of documentation are still in flux.
Paper: https://t.co/YkSayPUesC
Learn to build effective AI agents in our academy: https://t.co/U0ZuNA084v
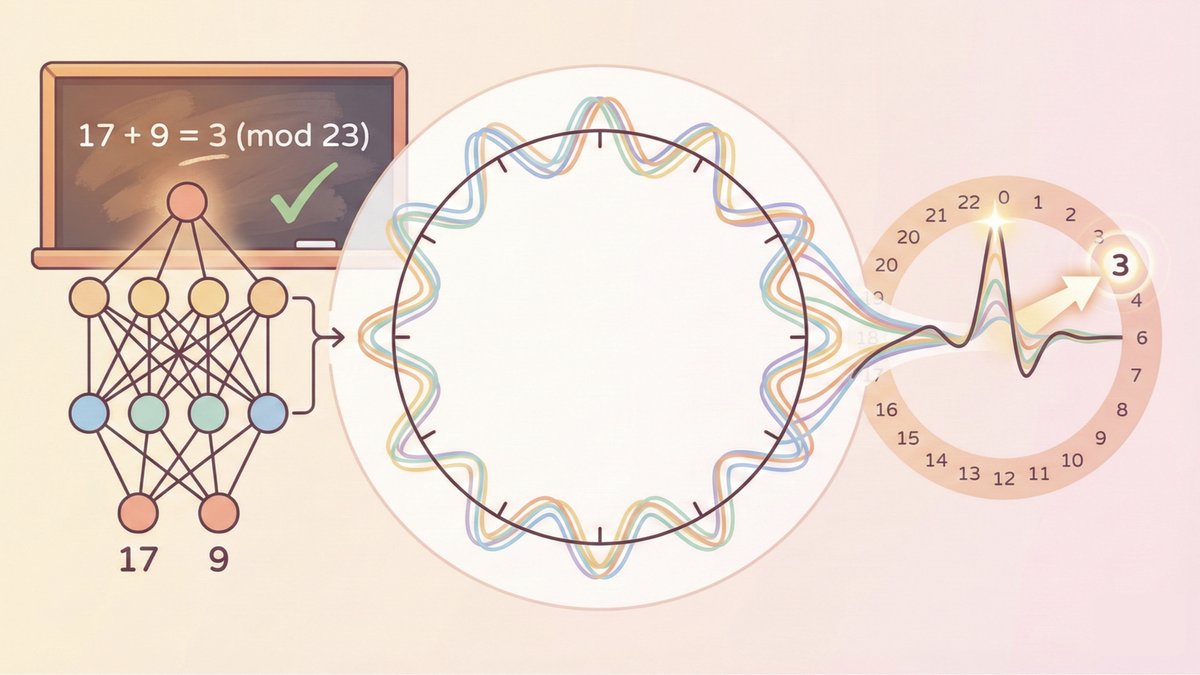
New Paper -- "On the Mechanism and Dynamics of Modular Addition: Fourier Features, Lottery Ticket, and Grokking"
We give a complete mechanistic and dynamic picture of how neural networks learn modular addition f(x,y) = (x+y) mod p. We answer three questions:
(1) What does the trained network compute?
(2) How do Fourier features emerge during training?
(3) Why does grokking happen?
Each answer comes with a mathematical characterization backed by theory and experiments.
Paper: https://t.co/uCU4eNr7tH
Blog: https://t.co/Ok9dDQcYvw
Demo: https://t.co/SX4Q6IsLHB
Code: https://t.co/03Adj6E3Bt
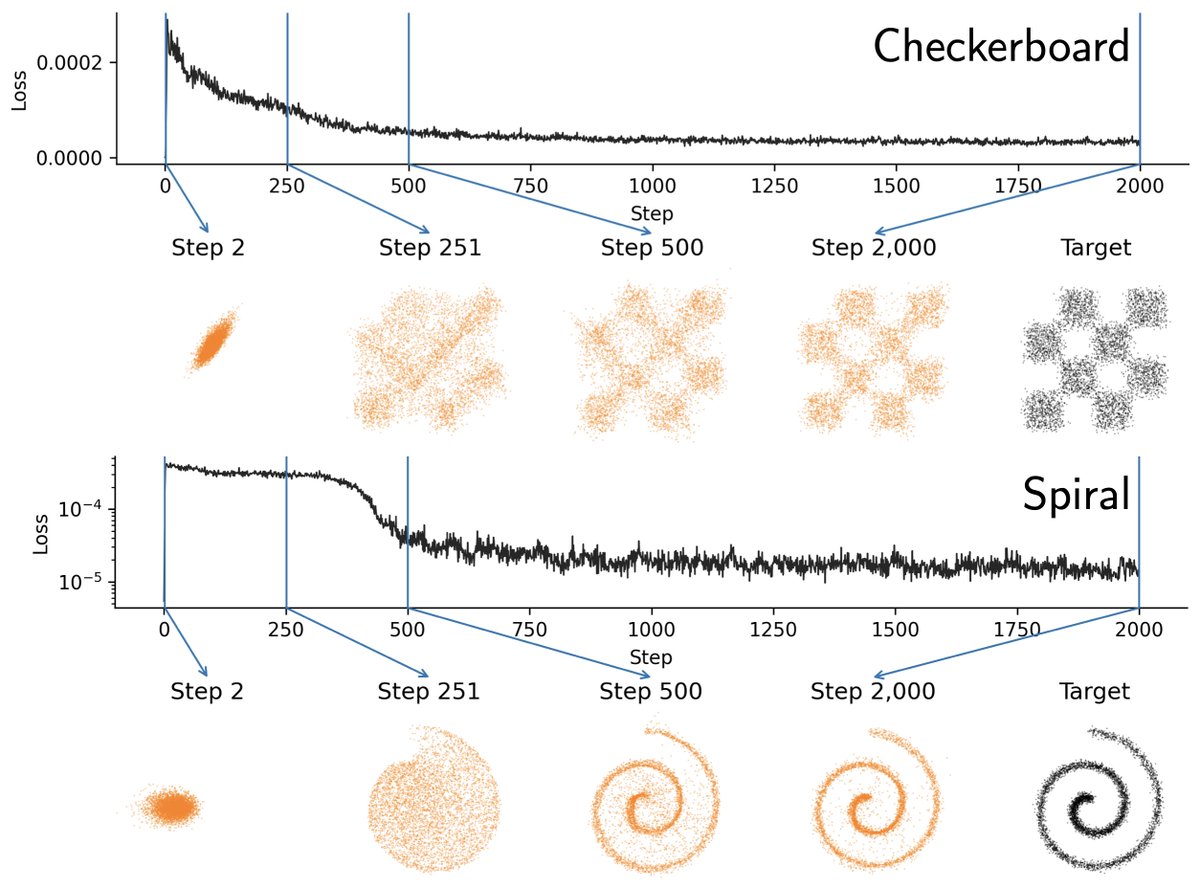
Generative Models via Drifting in MLX.
A minimal single file implementation showing how we evolve a pushforward distribution with a drifting field during training for single-step inference. No ODE/SDE solvers, adversarial loss, or complex nets.
code: https://t.co/7eea96wToy
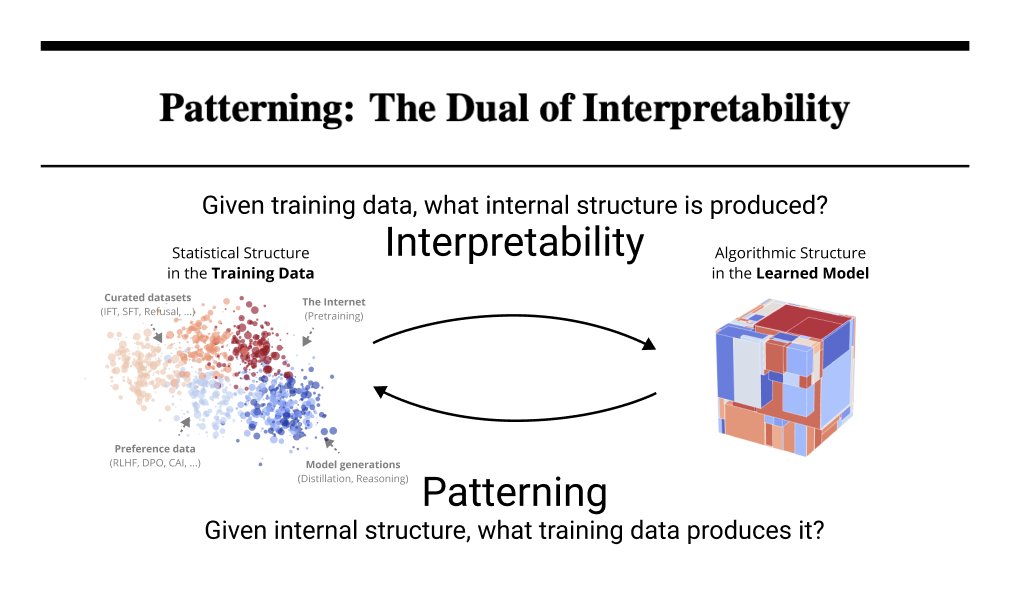
“Neural networks are grown, not programmed”
We’re changing that. Mechinterp investigates how models generalize beyond their training data by studying the resulting internal structure. We introduce patterning as the dual: given desired structure, determine what data produces it.
Is it better to go to academia or industry for research in AI or cognitive science? It's the most frequent question I get asked by PhD students, and I've finally written up some of my thoughts on the answers, as an epilogue to my more research-focused posts on cog sci and AI: