We’re dropping Gemini Omni: our first step towards a model that can create anything from anything - starting with video.
It combines Gemini’s intelligence with our generative media systems - representing a leap forward in world understanding, multimodality, and editing 🧵
Gemini Omni doesn't just build scenes that look real, it reasons about what should happen next. It combines an intuitive understanding of physics with Gemini's knowledge of history, science, and cultural context.
Rolling out today starting with video outputs to Google AI Plus, Pro and Ultra subscribers globally through the @Geminiapp + Google Flow, and @YouTube Shorts this week.
Everyone asks if Atlas can bring them a drink, but this robot can bring you the whole fridge. Using AI-driven behaviors, Atlas is doing hard work and coordinating its whole body to manage heavy objects, balancing complex contact points with accuracy and reliability.
We’re reimagining a 50-year-old interface - the mouse pointer - with AI. 🖱️
These experimental demos show how people can intuitively direct Gemini on their screens using motion, speech, and natural shorthand to get things done 🧵
Today, we're opening @Instawork Robotics Lab (IRL), connecting the robotics industry with > 10 million skilled workers. IRL is offering the first certified workforce program for the physical AI economy ... with 20,000 @Instawork Pros already certified! 👷
Read more from @alistairmbarr@BusinessInsider
https://t.co/57Jwyabf2P
We’ve developed a memory system for our models that provides both short-term visual memory and long-term semantic memory.
Our approach allows us to train robots to perform long and complex tasks, like cleaning up a kitchen or preparing a grilled cheese sandwich from scratch 👇
We’re making great progress with our Gemini Robotics work in bringing AI to the physical world - a critical aspect of AGI. As part of our next steps, super excited to announce our partnership with @BostonDynamics, combining our SOTA robotics models with their world-class hardware
Excited to pair our @GoogleDeepMind robotics efforts, where we've been working on robotic learning for many years (including variants of our Gemini models especially suited for visual understanding and robotic action) with the very capable robotics hardware from @BostonDynamics.
Impressive that the base model can be adapted for these dexterous tasks, particularly the lock and key. Note that training from scratch doesn’t work.
Pre-training is critical for generalist robots, just as it is for generalist language / image / video models.
We got our robots to wash pans, clean windows, make peanut butter sandwiches, and more!
Fine-tuning our latest model enables all of these tasks, and this has interesting implications for robotics, Moravec's paradox, and the future of large models in embodied AI.
More below!
@SuvanshSanjeev Appreciate the kind words, Suvansh! I'm very bullish on the future of robotics, optimistic that the same ML trends in language, audio, and video will extend here too.
Demis Hassabis believes world models are essential because they simulate the physical dynamics of reality, things language alone can’t fully express.
Language models learn from words, but many real-world experiences like motion, smell, or sensorimotor feedback can’t be captured in text.
Simulations help systems understand intuitive physics, spatial reasoning, and cause-effect dynamics.
This is key for robotics, wearables, and AI that can navigate and assist in the real world.
Amazing capabilities at low latency.
Personal news: I’ve joined DeepMind to push on world models! Large-scale video pre-training will unlock generalist robots.
Proud of helping drive transfer from human video at Tesla. The team's on a great trajectory for humanoid products.
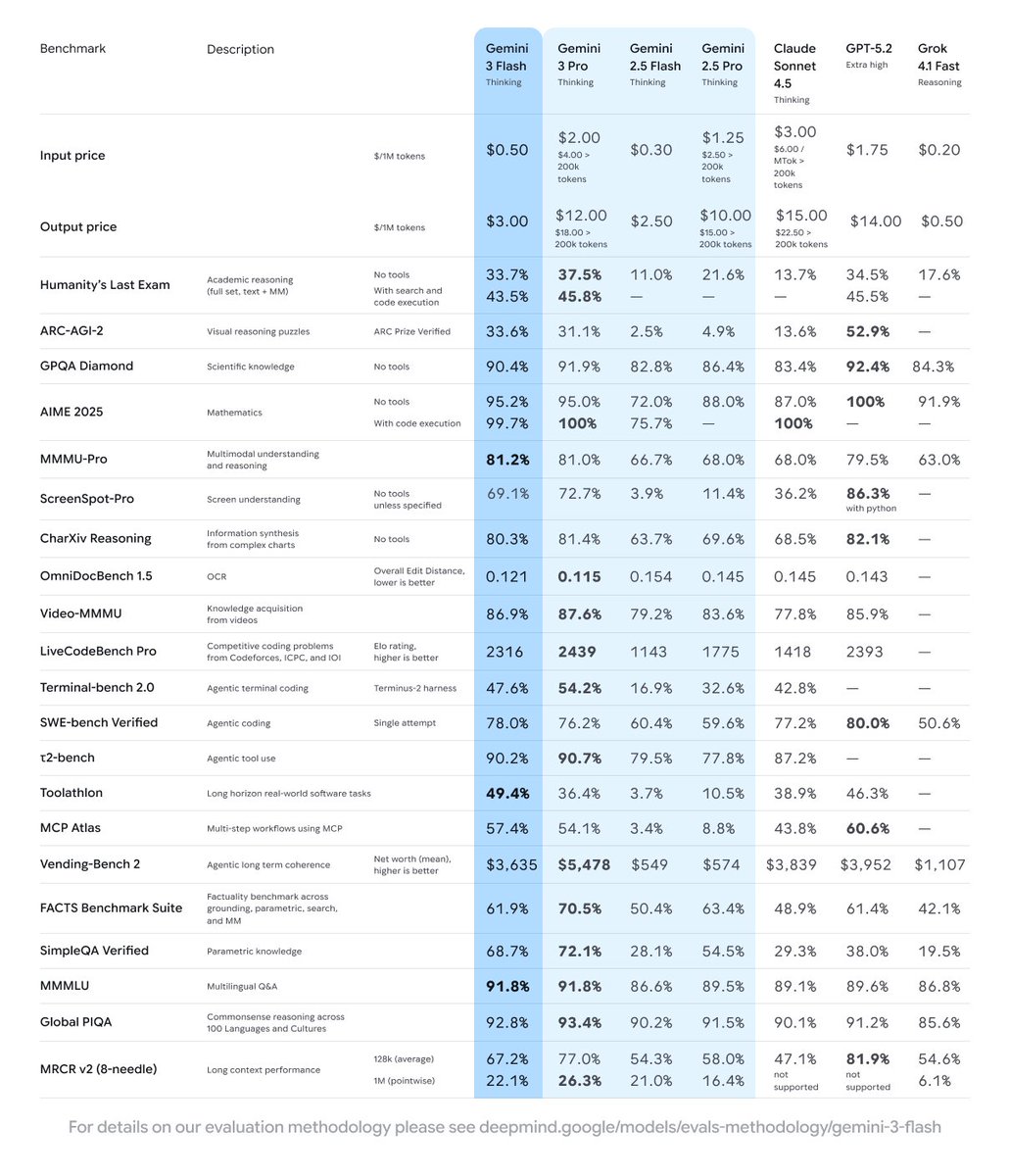
One of the things we strive to do with each new Gemini release is to make the new Flash model as good or better than the previous model’s Pro model. Gemini 3 Flash exceeds Gemini 2.5 Pro on nearly every metric, often by very large margins, and almost matches Gemini 3 Pro on most benchmarks.
Sensorized human collection is the most promising path for data scaling to enable generalist robots.
Interesting insights on critical mass of robot diversity needed for the model to start using human data!
We discovered an emergent property of VLAs like π0/π0.5/π0.6: as we scale up pre-training, the model learns to align human videos and robot data!
This gives us a simple way to leverage human videos. Once π0.5 knows how to control robots, it can naturally learn from human video.
Are you opening doors for humanoids… or is your humanoid opening doors for you?
Introducing DoorMan, our humanoid door-opening system powered by:
• end-to-end RGB pixel-to-action control
• large-scale simulation-only training
• teacher–student-bootstrap RL
This took our team 6 months of relentless iteration.
I wasn’t sure it could be done — now it’s real.
Website: https://t.co/d6oEHZQt0A
ArXiv: https://t.co/LElN1r4KCG