Human feedback is so critical for evaluating subjective AI systems -- and yet so costly to collect.
Come talk to me about AutoMetrics at #ICLR2026 🇧🇷! With <100 feedback points we generate automatic evaluation metrics for your task that beat hand crafted LLM-as-a-Judge rubrics by up to +33.4% improvement in correlation to human judgements!
The AM Podcast EP5 is around the corner. 👀🧑🍳
You may have seen the viral post about OpenAI math breakthrough. For EP5 we sat down with Jeremy Avigad, co-creator of @leanprover before that and the conversation is incredible. Jeremy shares not just the Lean project, but also
- The verification gap in human-AI collaboration
- How AI is changing mathematics
- The future of math education
- Capital, startups, and the mathematician's ecosystem
- ...
Stay tuned and subscribe our YouTube channel for latest updates!
"Evolve your repo, not just your agent."
Self-evolving repository (SEPO) is a fun idea that I’ve been exploring recently. @sepoagent turns any GitHub repo into a shared workspace for humans and coding agents.
Join us this Thursday May 28th 6-7pm PST for our first ever AM Podcast Live Stream! 🎉
We are hosting @cjziems, @dorazhao9, and @Diyi_Yang for a discussion on their new paper "Reflections and New Directions for Human-Centered Large Language Models"!
RSVP 🔗⬇️
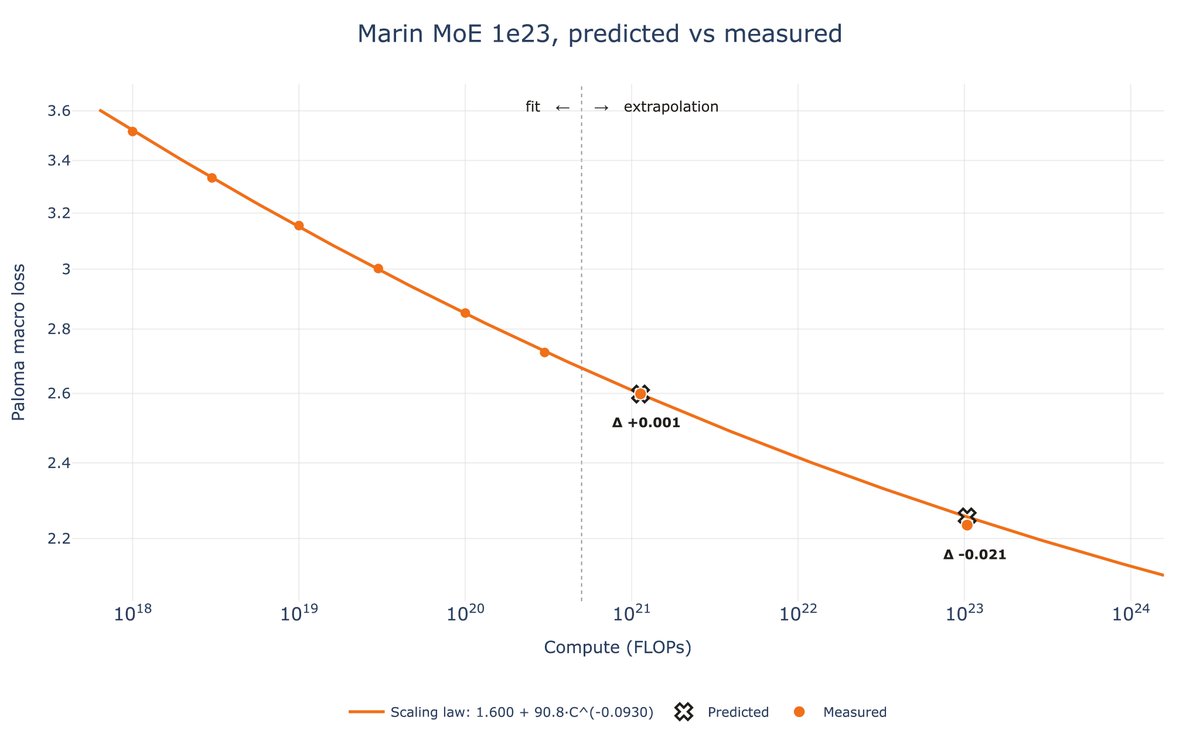
Not only do we want to train a good model, we want to know it'll be good before we even start training.
About a month ago, the Marin team launched a 129B (16B active) 1e23 FLOPs MoE run and preregistered a loss of 2.252. The run finished this past week and landed at 2.234.
https://t.co/OptaVa7jIO
The next frontier of AI is not only more capable model; it is an AI that *humans* can meaningfully live and work with :)
With all students in my cs329x Human-Centered LLM class, we present 60+ pages of insights for developing Human-Centered LLMs (HCLLMs), from design & data sourcing to training, eval & deployment 🧵
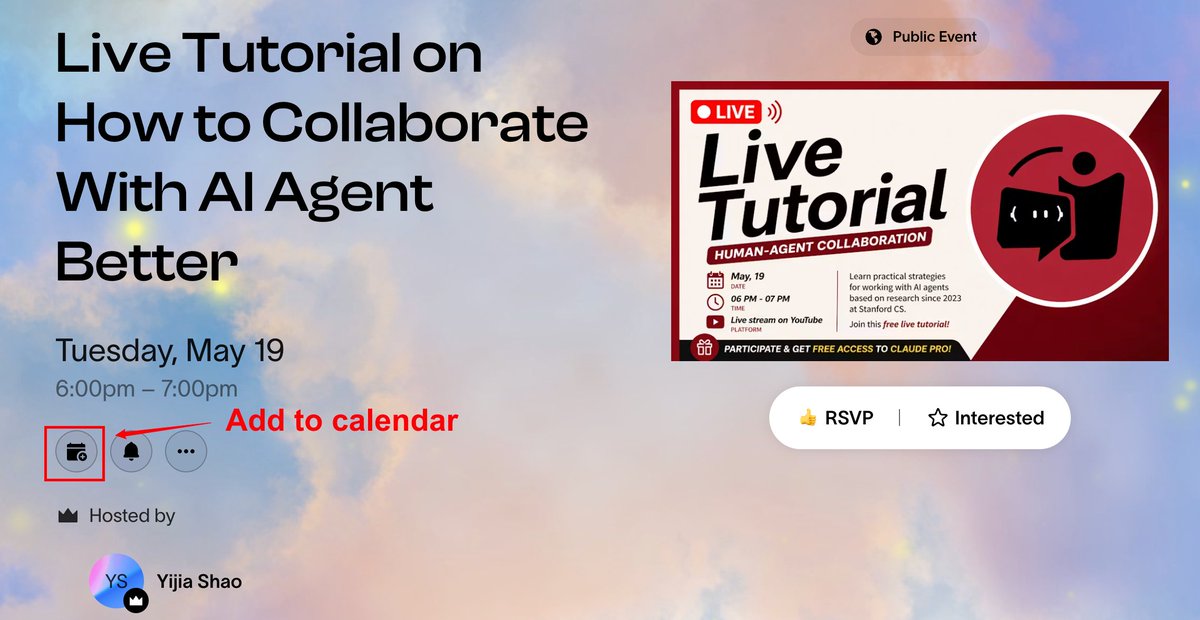
Tomorrow (5/19), 6–7pm PT: We're going live for the first time to share how to collaborate with AI agents more effectively 🤖
Thrilled (and a little nervous!) to see so many RSVPs. As Stanford Qualtrics console is down😅, we can't reach everyone directly — here's your calendar link: https://t.co/bf4pbb9FsO
Super excited to join the 2026 cohort of @KnightHennessy scholars!
Has been incredible talking to the other scholars about the major problems they are tackling across healthcare, science, policy, etc. Excited to work towards Human-Centered Open-Source AI that can support people tackling the world's biggest challenges!
Meet the 2026 cohort of KH scholars! These 87 new scholars make up the most global Knight-Hennessy Scholars cohort to date, and will pursue degrees in 45 graduate programs across all seven graduate schools at @Stanford: https://t.co/Ksw21DOnnw (1/2)
Interaction model poses new challenges for AI model inference engine. We discussed about it in our episode with @woosuk_k on @vllm_project 's solution. Link to the full episode in the thread.
We upgraded Tabracadabra 🎉 to bring an entire context-aware assistant (not just tab to autocomplete!) to any textbox. It's pretty great if you hate switching between the chat interface and what you're working on. We're also open-sourcing, so you can try it out!🧵
Introducing SWE-ZERO-12M-trajectories: the largest agentic trace dataset in the open, 5.7x larger than the previous largest.
112B tokens · 12M trajectories · 122K PRs · 3K repos · 16 languages
https://t.co/aVqCc4J5tr