Magnífico recurso de @Biblioteca_UNED para consultar políticas editoriales de revistas: interfaz clara, bien diseñada y muy útil para investigadores 👏👏
Nuevo caso de hoax científico al estilo Affaire Sokal: un profesor español de matemáticas, Pascual D. Diago (de la Universidad de Valencia), cansado del spam constante de revistas depredadoras que recibía, decidió probar hasta dónde era capaz de llegar una de ellas con un experimento. Los resultados son o muy graciosos o muy tristes, según cómo lo miremos
En octubre de 2025 recibió una invitación del Clinical Journal of Obstetrics and Gynecology (una revista conocida por ser depredadora, que cobra miles de dólares por publicar sin apenas revisión) y respondió enviando un artículo completamente absurdo generado por ChatGPT, un texto ridículo que mezclaba obstetricia con matemáticas, hablando de “ecuaciones de dilatación cervical”, de “teoremas de función ovárica”, de que la secuencia de Fibonacci provoca antojos de números primos en embarazadas matemáticas, y tonterías por el estilo.
Lo mandó bajo pseudónimo, con referencias falsas, nombres de autor en plan cachondeo y gráficos sin sentido. La revista lo aceptó sin problemas, lo pasó por su “equipo de revisión profesional”, le pidió citas irrelevantes, lo calificó de “interesante” y “bien escrito” y lo aceptó en minutos. Y lo publicó con DOI real… aunque Diago nunca pagó los 2.949 dólares que le cobraban por publicación.
El artículo sigue online, indexado en bases como OpenAlex, y la revista sigue mandándole recordatorios de pago. Es un ejemplo perfecto de cómo funcionan estas revistas: cero rigor científico... sólo buscan dinero.
Nueva expresión favorita "Catedraticos MDPI":
Miles de científicos hinchan su currículum con estudios autopublicados que cuestan millones de euros de dinero público
https://t.co/MBDorUVHha
"Los números especiales de MDPI y Frontiers son un enorme coladero. La ANECA debe excluir explícitamente estos trabajos. Universidades y OPI deben identificar las carreras construidas mediante números especiales y penalizarlas”, afirma @isidroaguillo
https://t.co/rOLWQqBRpe
Hemos preparado estos materiales para el curso "Una visión general del ecosistema IA de Google: la perspectiva universitaria".
Lo damos esta tarde en la plataforma #YoSigoUGR
👽PDF: https://t.co/EEF34BPH7r 👽
Según el autor de este artículo, la avalancha de artículos académicos -impulsada por el famoso “publica o perece”, así como por la globalización (sobre todo China) y el modelo de negocio de las cinco grandes editoriales (Elsevier, Springer Nature, Taylor & Francis, Wiley, Sage)- está ahogando la calidad científica.
Estas editoriales ganan enormes beneficios publicando artículos académicos gracias al modelo de "open access": cobran a los investigadores (o a sus universidades) un cargo por procesamiento de artículo que suele estar entre 1.800 y 2.900 dólares por paper (hasta 11.700 en revistas top), cuando el coste real de publicarlo es solo unos 400 dólares de media. Esto les deja márgenes de beneficio del 30–40 %, similares o superiores a los de gigantes tecnológicos como Google o Microsoft. El dinero para pagar esos cargos sale casi siempre de fondos públicos: subvenciones gubernamentales (como NIH en EE.UU. o fondos europeos) y presupuestos de universidades públicas, financiados con impuestos de los ciudadanos. Así, los contribuyentes estamos pagando indirectamente beneficios privados muy altos, mientras las editoriales multiplican la cantidad de artículos publicados (un 47 % más entre 2016 y 2022) para seguir aumentando ingresos, aunque esto esté bajando la calidad y facilitando la entrada de papers fraudulentos.
El resultado es una crisis en la calidad de los artículos, un debilitamiento de la peer review, proliferación de fraudes y retractaciones masivas. La solución pasa por poner algún tope a las 5 grandes pero sobre todo por un cambio cultural: menos cantidad, más calidad, y menos presión por publicar a cualquier precio.
https://t.co/WtqlEuPDiu
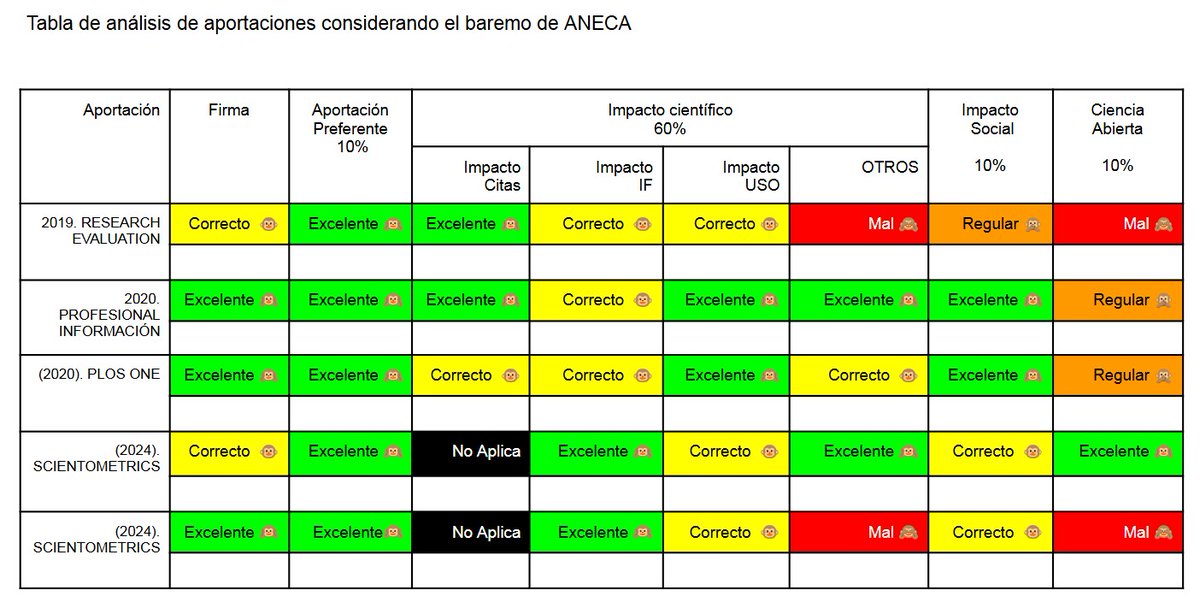
Mirad, para convocatoria de Sexenios, yo me preparé una tabla/matriz como esta (considerando el baremo) que me ayudó a seleccionar mis 5 aportaciones. Os ayudará a decidir y triunfar.
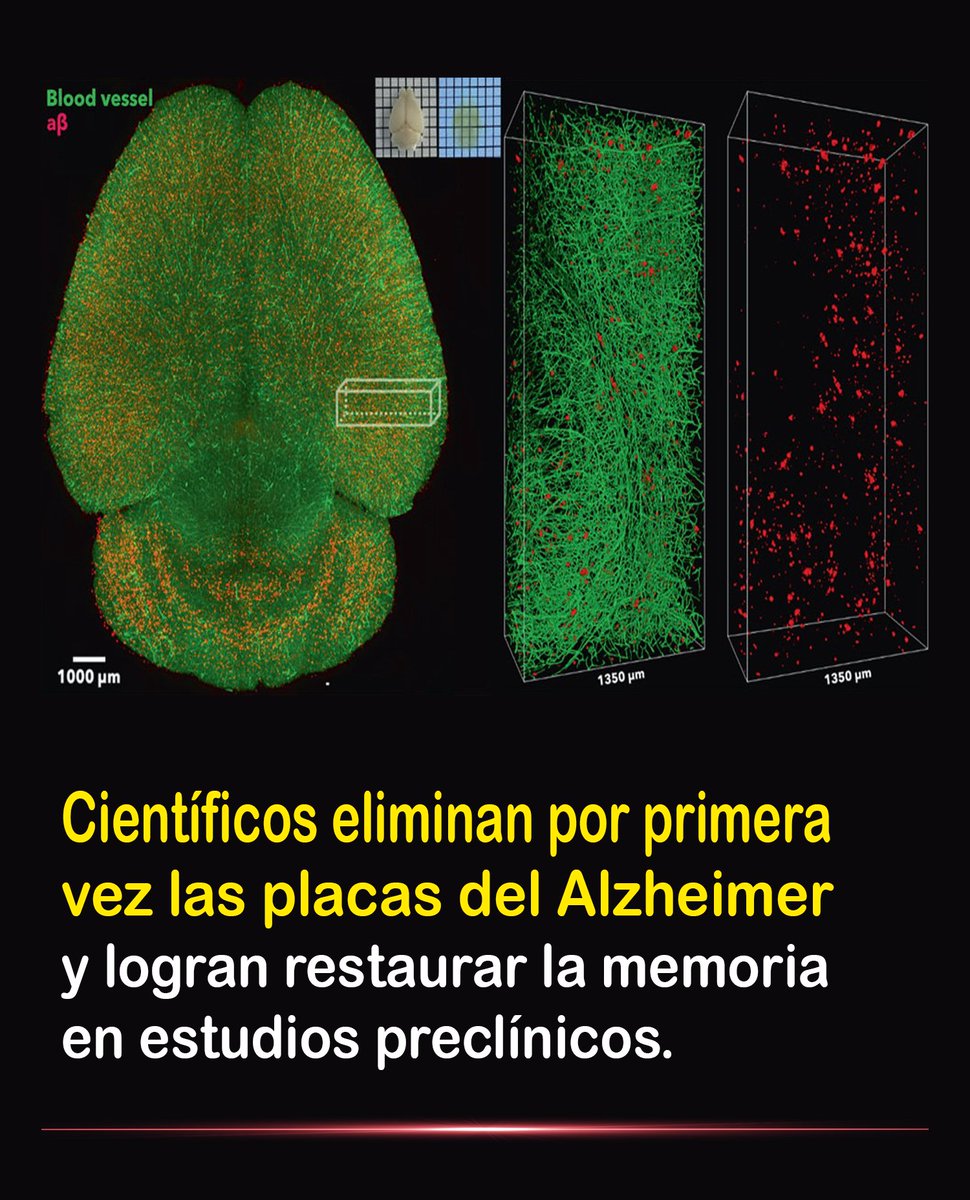
Científicos eliminaron las placas del Alzheimer y lograron restaurar la memoria en estudios preclínicos con una nanomedicina capaz de limpiar el cerebro en pocas horas. Un avance que podría transformar el futuro del tratamiento. 👇
Mayor info: https://t.co/yfyEVCl0Pj
Se continúa #DesmontandoAFlecha y todas las estructuras que conforman CREA.
Seguiremos trabajando y visibilizando sin perder el foco, las víctimas y denunciantes de Flecha.
No os vamos a dejar solas.
https://t.co/qBdJ7QsVe3
Pues me he permitido el lujo de probar #GScholarLENS con el perfil del gran @torressalinas y me parece una maravilla la información que devuelve (la imagen adjunta es el Plot que te permite descargar GScholarLENS)
+ Info: 🔗https://t.co/zuAmlXevxr
📢 NEW updates to COPE Retraction guidelines!
* batch retractions
* communicating with authors
* purpose of retraction
* editor’s decision to retract
* aligning with NEW expressions of concern guidelines
👉 Guidelines: https://t.co/kZfOXDw1Yb
#Scholcomms
La nueva ley de protección al informante/denunciante de casos de fraude, endogamia, acoso, abuso… está en marcha y es poco conocida.
En la academia e investigación es una arma muy importante.
Os dejamos esta web donde se puede descargar la guía.
https://t.co/jAJyWyi8LC
#Bibliotecarios.
¿Os gustaría tener acceso a un Mapa de #PatrimonioBibliográfico 📜 para localizar desde un único punto de consulta las colecciones patrimoniales españolas?
El GT CCPB del Consejo de Cooperación Bibliotecaria está trabajando en ello. 👇
https://t.co/XnNYvAf5dg
La @IFLA ha publicado el documento «IFLA Entry Point to Libraries and AI», una guía de referencia que recoge su posicionamiento sobre la Inteligencia Artificial #IA y su aplicación en el ámbito bibliotecario.
Noticia en el @CCBiblio ➡️ https://t.co/OZvSmbi3Rg