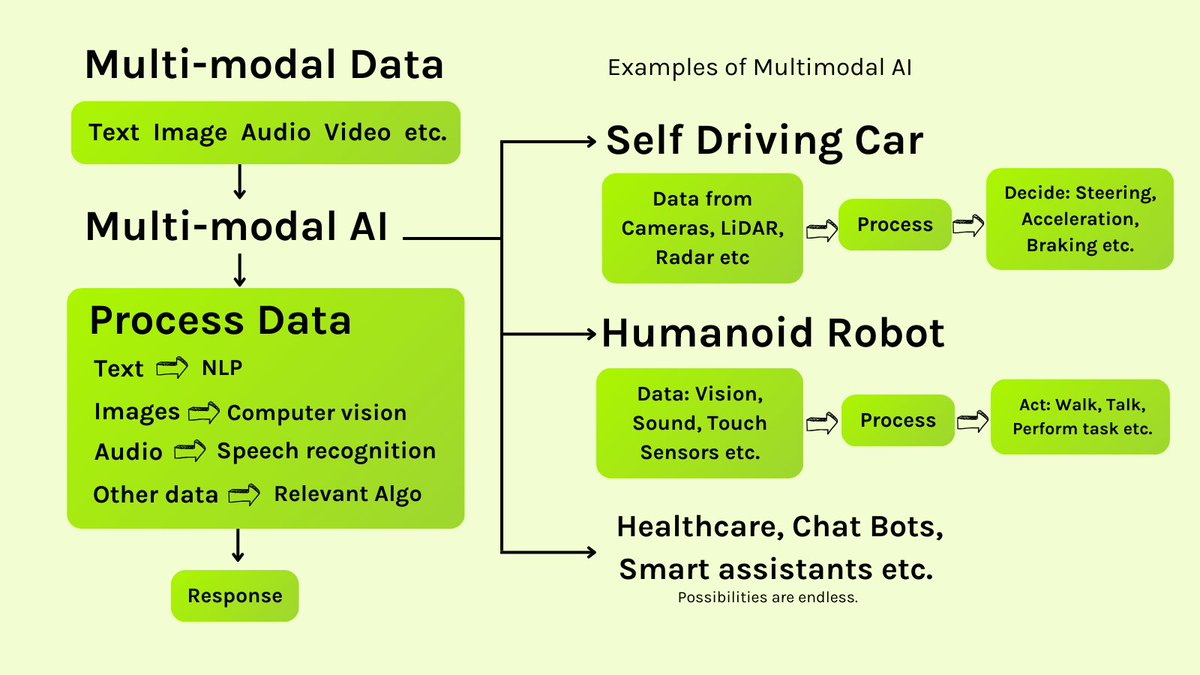
The vast amount of data in the world isn't textual. Data exists in the form of text and images, audio, video and more. To be able to fully understand the world, AI needs to be able to understand and process ALL of these different forms of multimodal data.
Multimodal AI systems are capable of processing different data types using specialized algorithms. It works in parallel, processing text through Natural language processing algorithms, audio through speech recognition algorithms, images through computer vision algorithms, and etc. Once all these different data are processed, AI combines them to form a more comprehensive output.
To compare it with us, we see, hear, visualize and combine all of them. For example, when you talk with your friend, you listen to what they say, notice their expression and act accordingly. This is similar to how multimodal AI work, it can process multiple data to generate output comprehensive output. What’s Interesting about multimodal AI is, if one modality is unreliable or unavailable, it can rely on other modalities to get a response instead of hallucinating.
Example:
- Self driving car takes input from sensors like radar, LiDAR, cameras, and ultrasonic sensors etc to navigate safely.
- Humanoid robots also takes input from like vision, audio, touch sensors etc. to act and perform task.
- In healthcare, it can combine different reports like CT-scans, X-rays, ECG etc. for diagnosis. etc.
The possibilities are endless.
TL;DR Our world is made up of diverse data like: audio, visual, text, and more. By combining and processing this data, we can develop more reliable AI models for real-world applications like self-driving cars, medical diagnostics, humanoid robots and many more!
Imagine telling someone in 2024 that not over-relying on synthetic data is a good thing.
The reality is LLM outputs are biased towards the high-density regions of the training distribution.
Synthetic data is a lossy reconstruction of reality. That's great for augmentation and distillation. But if models increasingly train on the outputs of other models, we're effectively recompressing a compression. The first thing that disappears is the long tail (rare observations and genuinely novel information), and much of what we call intelligence is the ability to reason about those exact things.
The next GRASS Token Holder and Network Participant Call will take place on July 7. The call will provide an overview of Grass network progress, the development roadmap, business milestones, growth highlights, and more.
To promote equal access to information, the call will be open to the public. Questions may be submitted in advance for consideration during the session.
Further details, including the exact time and registration information, will be shared soon.
The network is more reliable than it's ever been as our success rates and core performance metrics have increased across the board.
This is a result of improvements to our detection and filtering capabilities that remove bots, bad actors, and low quality nodes from the network. Our efforts to prevent bad actors from gaming the system have led to stronger and more sustainable network performance.
Our goal has always been simple: reward real users who support the network with bandwidth that the network can actually use.
Real rewards for real users.
There's nothing quite like waking up to see new network points added on the dashboard overnight. Instead of big corporations quietly profiting off my unused bandwidth, it's now helping train AI models and I get rewarded for it.
win-win, especially as someone who's genuinely passionate about AI.
grass in 2025
> 3x’d node count
> launched the most performant multimodal data crawl in the world
> broke 3PB in daily scraped data
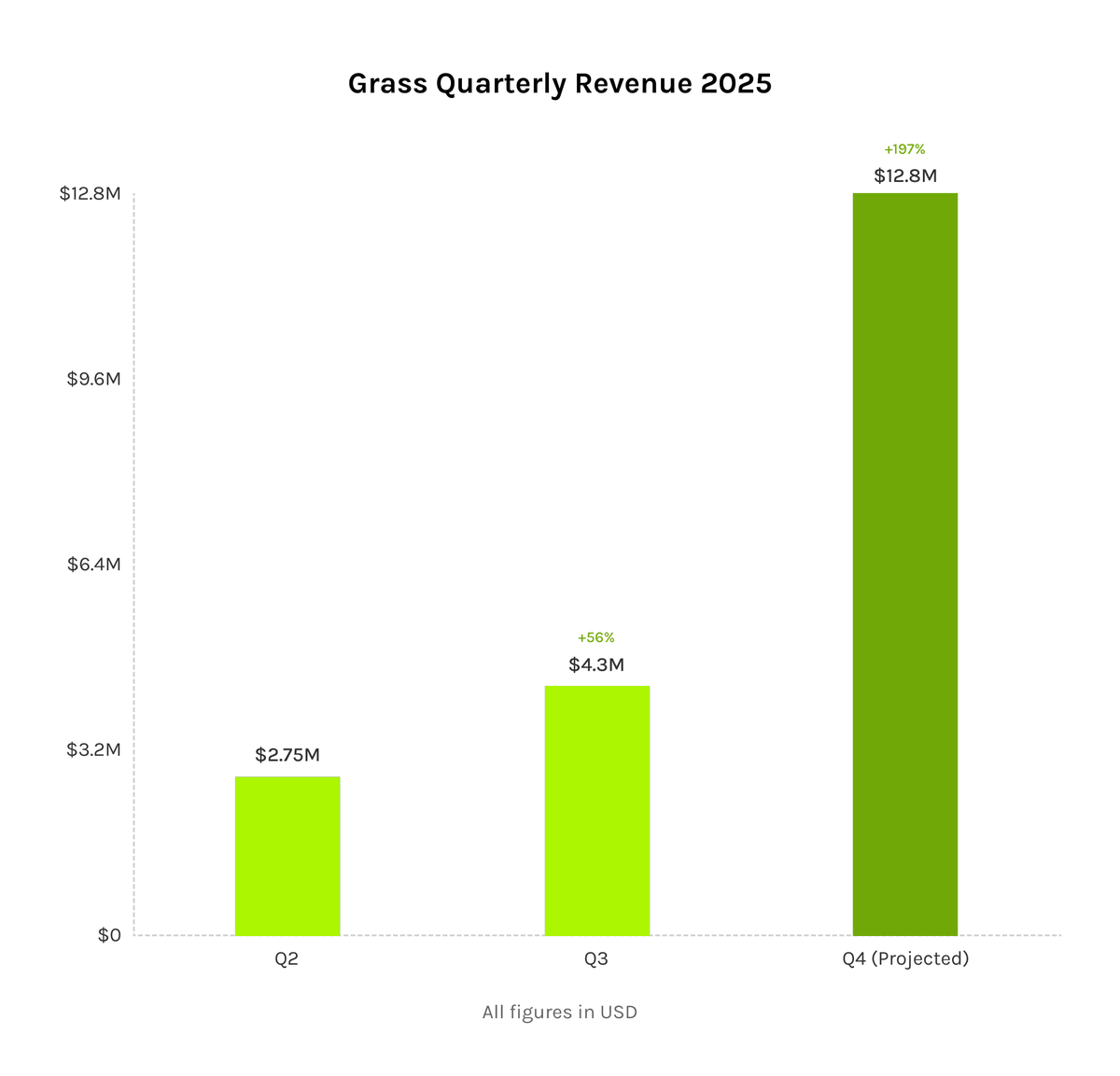
> scaled quarterly revenue from data sales to 8 figures
among other things, a big focus for 2026 will be expanding from training to inference data
we're growing quickly at Wynd Labs.
if you are highly technical, wanting to work with exabyte-scale data in a high performing and competitive environment alongside world class talent, send me a message.
Enterprise revenue flows directly to the Grass Foundation.
Wynd Labs is a service provider executing the network's mandate.
This structure ensures that as the business scales, value accrues to the ecosystem itself.
Andrej Radonjic breaks down the structure 👇
2025 has been a breakthrough year. Grass has evolved into one of the largest multimodal data providers, with accelerating commercial demand from AI labs and enterprise clients.
Every dollar generated is being reinvested to expand network capacity and support the Grass ecosystem.
🔥 @grass just dropped a big hint: a token holder call is coming — with revenue details on the way!
In this DePINed episode @TheTomTrow talks with @0xdrej about:
• Grass’ 8M+ node network powering today’s AI models
• why AI companies are desperate for high-signal multimodal data
• the insane scale: 4 PB/day, hundreds of PB stored
• token incentives + the philosophy of “token holders first”
��️ Tap in — this might be our most important episode yet!
We’re announcing our first Token Holder Call on November 24th, 2025 at 1PM EST.
We’ll review business progress, revenue and growth highlights, updates related to the token’s role in our ecosystem, and major initiatives ahead.
Questions may be submitted in advance through the registration form on Luma.
Register here: https://t.co/lDq3SUZ20C
Grass × @inference_net × @laion_ai
100 million scientific papers processed with open models, making global research structured, searchable, and accessible to both people and AI.
A milestone for open, connected science.
https://t.co/Rsh2vNgGqH
At ODSC AI West 2025, Andrej Radonjic @0xdrej, Co-Founder & CEO of @Wyndlabs_ai, pulls back the curtain in:
The Hidden Infrastructure Behind AI: Building High-Performance Systems for Planet-Scale Data Collection.
🔗 Register → https://t.co/60XEzchSzF
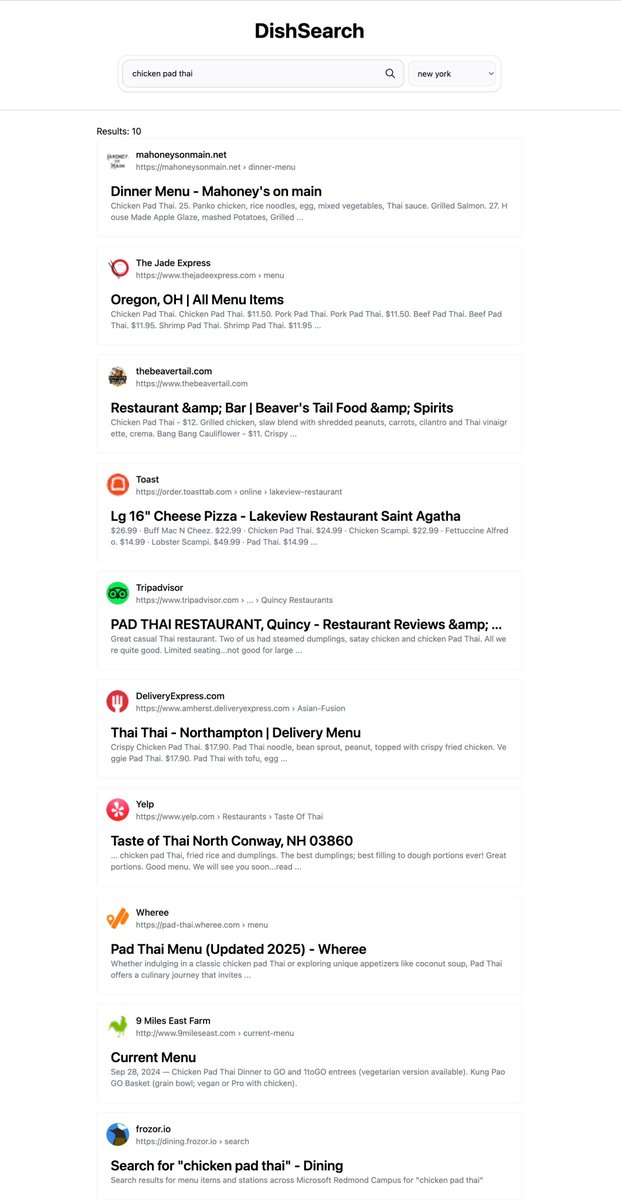
Ever been somewhere new and struggled to find a good spot for what you're craving but you are stuck with ads and irrelevant search results? I built a quick experiment to fix this.
Here's how it works: users input the dish and location, and everything else happens in the background. Using Grass’s SERP API, it filters out noise, ads, and irrelevant content, then presents only the best options.
What's a SERP API? SERP stands for Search Engine Results Page, it gives you search results as structured JSON instead of unorganized format or raw format.
Why does this matter? Normally when you search "Beef Wellington near me," you see ads, chains, and random listings. With structured JSON data, I can programmatically filter by ratings, remove sponsored content, and show only what's actually relevant. Cleaner results and less noise.
How can this app be improved? It could include filters for price and rating, AI summaries, and map integration.
Note: This is an experimental web app I wanted to try and isn’t fully optimized yet.
we just shipped the fastest search api on the market.
we are giving free access for a limited amount of time. please reach out if you'd like to give it a try!
We've just launched Network Points(Diamonds on the db)
Network Points are a new type of Grass Point earned when your bandwidth is actively used by the Grass Network to power web data requests. Uptime Points, which you’ve been earning until now, reward your device for staying connected and helping grow the network through referrals. Together, Uptime Points and Network Points reflect both the availability and the usage of your bandwidth.
🧵