Check out the latest work of our center, in collaboration with @TAMU!
Towards theorizing the boost in capabilities of agent systems.
@PierBeneventano@GalantiTomer
Have you ever wondered how to formalize what an agentic system actually is? Meaning where they fit in the book of ML and how to explain/predict their performance?
We argue here, agents can be seen as boosting reasoning models!
https://t.co/lvQtfHEi12
Thanks a lot for sharing our work! On top of the things mentioned! We also give a very nice mathematical framework and mathematical results about agent systems :)
With the amazing Varun, Riccardo, Tommy, @GalantiTomer
1/ Many optimization problems are hard in theory.
But real OR and NP-hard instances often have exploitable structure.
Can an LLM agent discover that structure automatically and turn it into faster solver code?
This is a project I’m very excited about.
Back in the days the smartest computer scientists were finding the efficient ways to solve their problems.
We made the agents do this work here.
Our new paper was accepted at ICML!
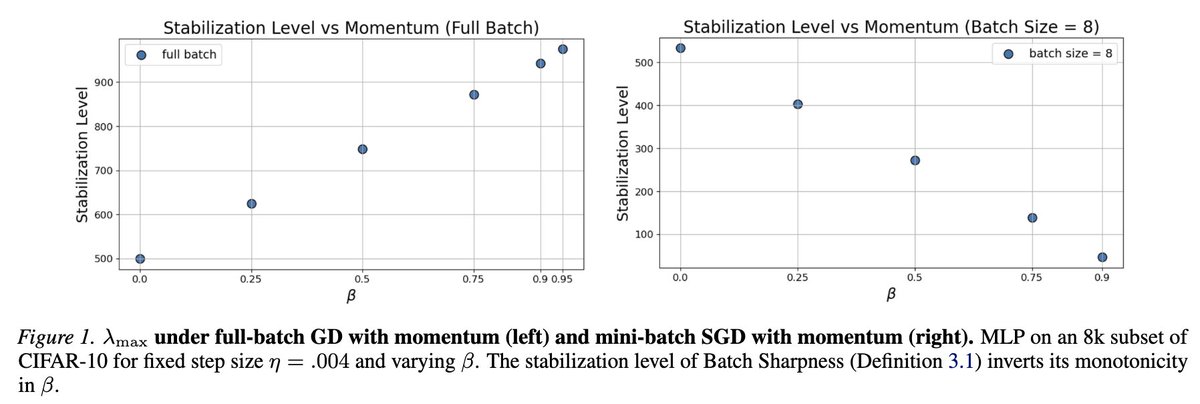
1) Momentum isn’t just “SGD but faster”.
It affects sharpness (of orders of magnitude!)
2) The usual story says momentum lets you train in sharper regions.
That’s true for large batches only! The opposite is true for minibatches!
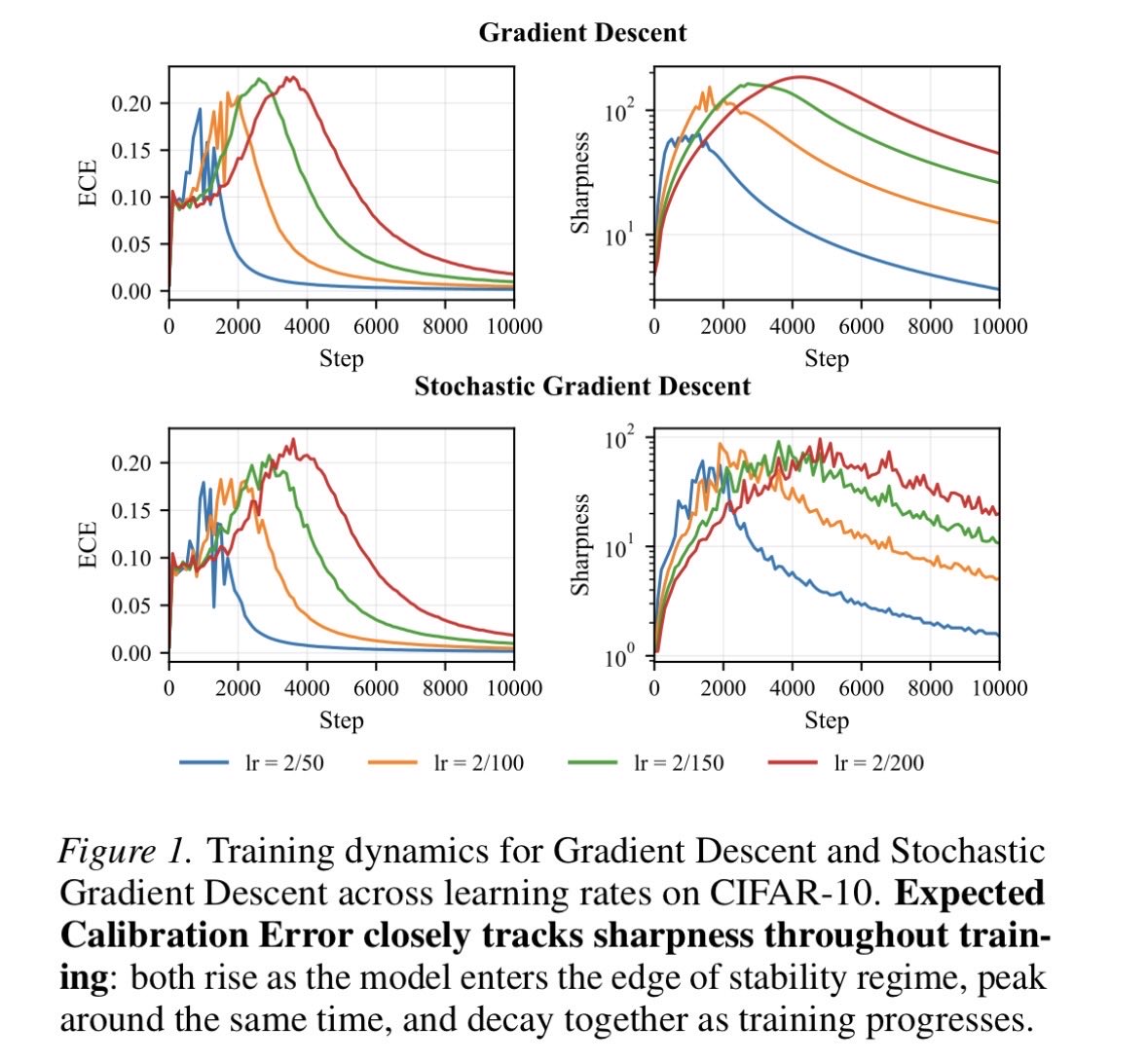
Muon leads to severely miscalibrated models!
This is just one of the results of this new paper of ours:
In “Too Sharp, Too Sure�� we show calibration error tracks loss curvature during training and we tie both to margin tails.
[blog] What is Intelligence? Or "Distinguishability is All You Need"
Here are several related questions to which we do not have a good answer:
How will we know when we've achieved "Artificial General Intelligence" (AGI)?...
https://t.co/fpmEG5a6xa
[video] "Intelligence as Prediction: Cybernetics, LLMs, and Sociality"
Speaker: Blaise Agüera y Arcas - Google, Paradigms of Intelligence
https://t.co/RwKTdB8MLu
[blog post] "PoggioAI/MSc Went Online"
This first public release is an open-source, customizable, modular multi-agent system for academic research workflows, with a current emphasis on machine learning theory and nearby quantitative fields.
https://t.co/4wbnoRo8OZ
Most AI for research work tries to maximize autonomy first and patch quality later.
We think the near-term path is the reverse:
Automating step-by-step holding the quality bar fixed.
Today we’re open-sourcing PoggioAI/MSc for ML Theory Research
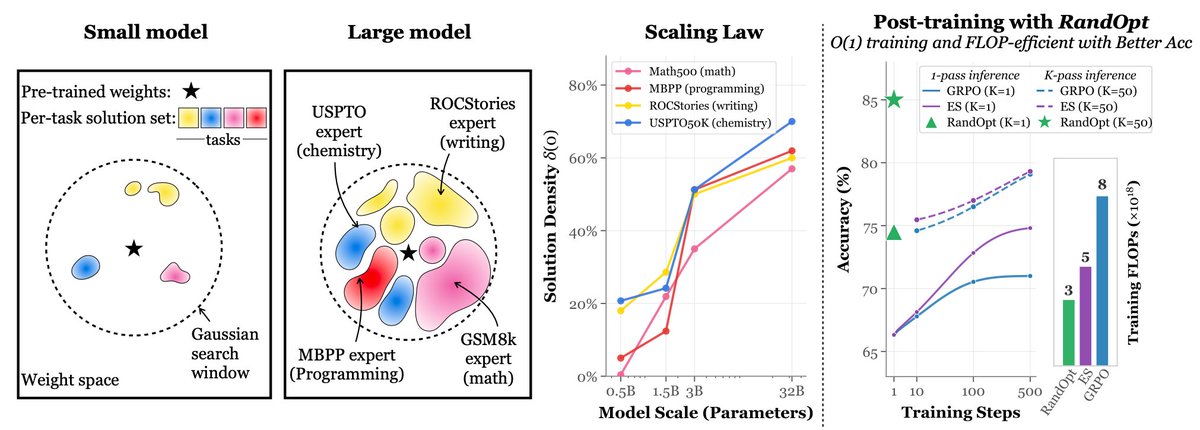
Simply adding Gaussian noise to LLMs (one step—no iterations, no learning rate, no gradients) and ensembling them can achieve performance comparable to or even better than standard GRPO/PPO on math reasoning, coding, writing, and chemistry tasks. We call this algorithm RandOpt.
To verify that this is not limited to specific models, we tested it on Qwen, Llama, OLMo3, and VLMs.
What's behind this? We find that in the Gaussian search neighborhood around pretrained LLMs, diverse task experts are densely distributed — a regime we term Neural Thickets.
Paper: https://t.co/rFJz2kVEOA
Code: https://t.co/HAmonfpXIA
Website: https://t.co/QZ6AMIsKCw
[blog] Beneficial Misalignment: Why We Shouldn't Always Align AI to Humans
In the rapidly evolving field of NeuroAI, a significant amount of energy is dedicated to 'alignment', the idea that representations from artificial intelligence should converge...
https://t.co/T2Dyufvsp5
[blog post] A Conversation with Blaise Agüera y Arcas: On Intelligence, Life, and the Future of AI
What does it mean to call something intelligent - and when did this question get so hard to answer? For Blaise Agüera y Arcas, VP at Google and founder...
https://t.co/oSHAfjfwVx
[blog post] Can a Neural Network Think Before It Speaks?
Somewhere around 2022, an observation started making the rounds among researchers working with large language models: if you just asked a model...
https://t.co/fjb6BxtB2c
[blog post] Edge of (Stochastic) Stability made simple — Part II: the mini-batch case
In Part I we had one landscape and a deterministic update.
Now we have a distribution of mini-batch landscapes and a stochastic update...
https://t.co/UBb5Exd2Jh
[blog post] Edge of (Stochastic) Stability made simple — Part I: A crash course on (full-batch) Edge of Stability
In this part I introduce the phenomenon and what I believe are the two key mechanisms—which we’ll use as the springboard for the mini-bat...
https://t.co/b2rXpiWVAa
[blog post] Are Transformers Just "Stochastic Parrots"?
A common criticism of Large Language Models (LLMs) is that they are merely "stochastic parrots"—statistical mimics that stitch together likely patterns without genuine reasoning...
https://t.co/gFRbqdH311
🧵 New paper: LLM-ERM: Sample-Efficient Program Learning via LLM-Guided Search
https://t.co/okXMmqAV8k
We use reasoning LLMs to learn tasks like IsPrime from ~200 samples by proposing short programs, making both the learned function *and* the learning process interpretable 🤯
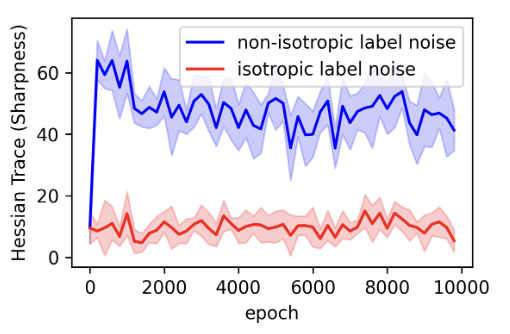
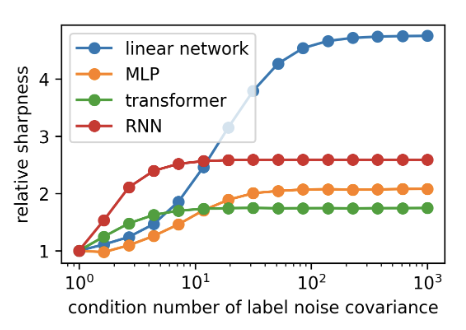
Does SGD really “seek flat minima”?
We show that SGD has no intrinsic preference for flatness, even for stable linear networks—going against ~10 years of folklore.
Flatness emerges iff label noise is isotropic; anisotropic noise drives SGD to arbitrarily sharp solutions.
This reveals a new flattening–sharpening mechanism in late training, unrelated to standard progressive sharpening or Edge-of-Stability effects.






















![MIT_CBMM's tweet photo. [blog] What is Intelligence? Or "Distinguishability is All You Need"
Here are several related questions to which we do not have a good answer:
How will we know when we've achieved "Artificial General Intelligence" (AGI)?...
https://t.co/fpmEG5a6xa https://t.co/6hwKPGlmUp](https://pbs.twimg.com/media/HFjFXYrakAARnNh.jpg)
![MIT_CBMM's tweet photo. [video] "Intelligence as Prediction: Cybernetics, LLMs, and Sociality"
Speaker: Blaise Agüera y Arcas - Google, Paradigms of Intelligence
https://t.co/RwKTdB8MLu https://t.co/76npNPFjFy](https://pbs.twimg.com/media/HEx_XpzaQAAOYot.jpg)
![MIT_CBMM's tweet photo. [blog post] "PoggioAI/MSc Went Online"
This first public release is an open-source, customizable, modular multi-agent system for academic research workflows, with a current emphasis on machine learning theory and nearby quantitative fields.
https://t.co/4wbnoRo8OZ https://t.co/jnEUYjyoVi](https://pbs.twimg.com/media/HEjHI0RWcAE29aS.jpg)

![MIT_CBMM's tweet photo. [blog] Beneficial Misalignment: Why We Shouldn't Always Align AI to Humans
In the rapidly evolving field of NeuroAI, a significant amount of energy is dedicated to 'alignment', the idea that representations from artificial intelligence should converge...
https://t.co/T2Dyufvsp5 https://t.co/uKx6pQ3qwH](https://pbs.twimg.com/media/HDoc_hYXkAAZgKJ.jpg)
![MIT_CBMM's tweet photo. [blog post] A Conversation with Blaise Agüera y Arcas: On Intelligence, Life, and the Future of AI
What does it mean to call something intelligent - and when did this question get so hard to answer? For Blaise Agüera y Arcas, VP at Google and founder...
https://t.co/oSHAfjfwVx https://t.co/hxzhtHcBGs](https://pbs.twimg.com/media/HDGXlX1XUAAz06y.jpg)
![MIT_CBMM's tweet photo. [blog post] Can a Neural Network Think Before It Speaks?
Somewhere around 2022, an observation started making the rounds among researchers working with large language models: if you just asked a model...
https://t.co/fjb6BxtB2c https://t.co/Tybbsu333y](https://pbs.twimg.com/media/HCib5xoWEAAG3lu.jpg)
![MIT_CBMM's tweet photo. [blog post] Edge of (Stochastic) Stability made simple — Part II: the mini-batch case
In Part I we had one landscape and a deterministic update.
Now we have a distribution of mini-batch landscapes and a stochastic update...
https://t.co/UBb5Exd2Jh https://t.co/pJD8OW5EZG](https://pbs.twimg.com/media/HCGNVzqa4AAn2Ud.jpg)
![MIT_CBMM's tweet photo. [blog post] Edge of (Stochastic) Stability made simple — Part I: A crash course on (full-batch) Edge of Stability
In this part I introduce the phenomenon and what I believe are the two key mechanisms—which we’ll use as the springboard for the mini-bat...
https://t.co/b2rXpiWVAa https://t.co/iQX15XK78c](https://pbs.twimg.com/media/HBnkXIeWMAACaiX.jpg)
![MIT_CBMM's tweet photo. [blog post] Are Transformers Just "Stochastic Parrots"?
A common criticism of Large Language Models (LLMs) is that they are merely "stochastic parrots"—statistical mimics that stitch together likely patterns without genuine reasoning...
https://t.co/gFRbqdH311 https://t.co/pb1JqECSbQ](https://pbs.twimg.com/media/HBAdo78awAADTze.jpg)