"Screening Is Enough"
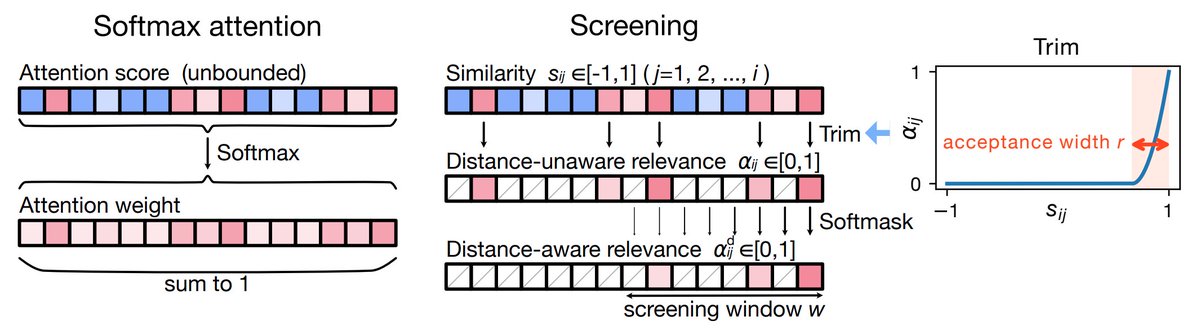
> [Softmax attention] does not provide an independently interpretable measure of query—key relevance: attn. scores are unbounded, while attn. weights are defined only relative to competing keys. Consequently, irrelevant keys cannot be explicitly rejected...
I just released a revised version of my paper on Multiscreen, an alternative to Transformer for long-context language modeling.
✅ Maintains performance and retrieves information accurately on contexts far longer than those seen during training
✅ Much more stable at large learning rates — it can even train with learning rate 1
✅ Smaller model size & faster inference
✅ More interpretable context selection
I added more figures to the main text and rewrote the paper to make it easier to follow. I’d be very happy if you read it!
Paper → https://t.co/fi9Ucl6oOy
I just released a revised version of my paper on Multiscreen, an alternative to Transformer for long-context language modeling.
✅ Maintains performance and retrieves information accurately on contexts far longer than those seen during training
✅ Much more stable at large learning rates — it can even train with learning rate 1
✅ Smaller model size & faster inference
✅ More interpretable context selection
I added more figures to the main text and rewrote the paper to make it easier to follow. I’d be very happy if you read it!
Paper → https://t.co/fi9Ucl6oOy
パラメータ数92%削減、推論速度3.2倍。 Transformerの限界を突破する新アーキテクチャ『Multiscreen』が注目されているようだ。論文タイトルは “Screening is enough” 。 「Attention Is All You Need」への挑戦状とも取れる内容である。
従来の研究は「いかにして重要な情報に注目するか」を追求してきた。この論文はその逆で「無関係な情報をいかに切り捨てるか」というアプローチを提案する。
従来のAttention機構はSoftmaxを用いて「相対的な重要度」を計算するが、これは無関係なノイズにも重みを割り当ててしまう欠点があった。提案手法のMultiscreenは、各キーに対して絶対的な閾値で判定を行い、不要な情報を削除してから集約を行う。
たとえば、Softmaxは「AがBよりマシなら、Aに重みを振る」という相対評価だったが、Multiscreenでは「AもBもゴミなら、両方捨てる」という挙動になる。
この変更により、同じトークン予算で、Transformerのベースラインよりも40%少ないパラメータで同等の検証損失を達成した。まだTransformerでは学習が発散してしまうような大幅に大きな学習率でも、Multiscreenでは安定した最適化が可能である。大きな学習率を使えるので微調整が短時間で実行でき、高速な実験サイクルを回せるようになる。
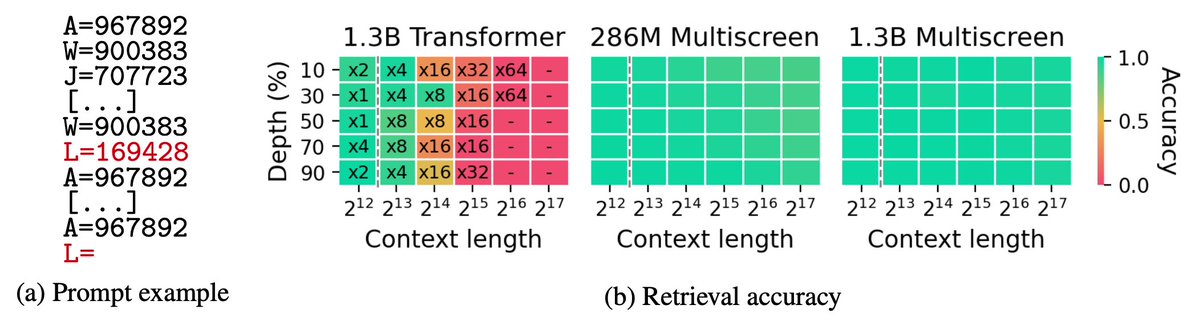
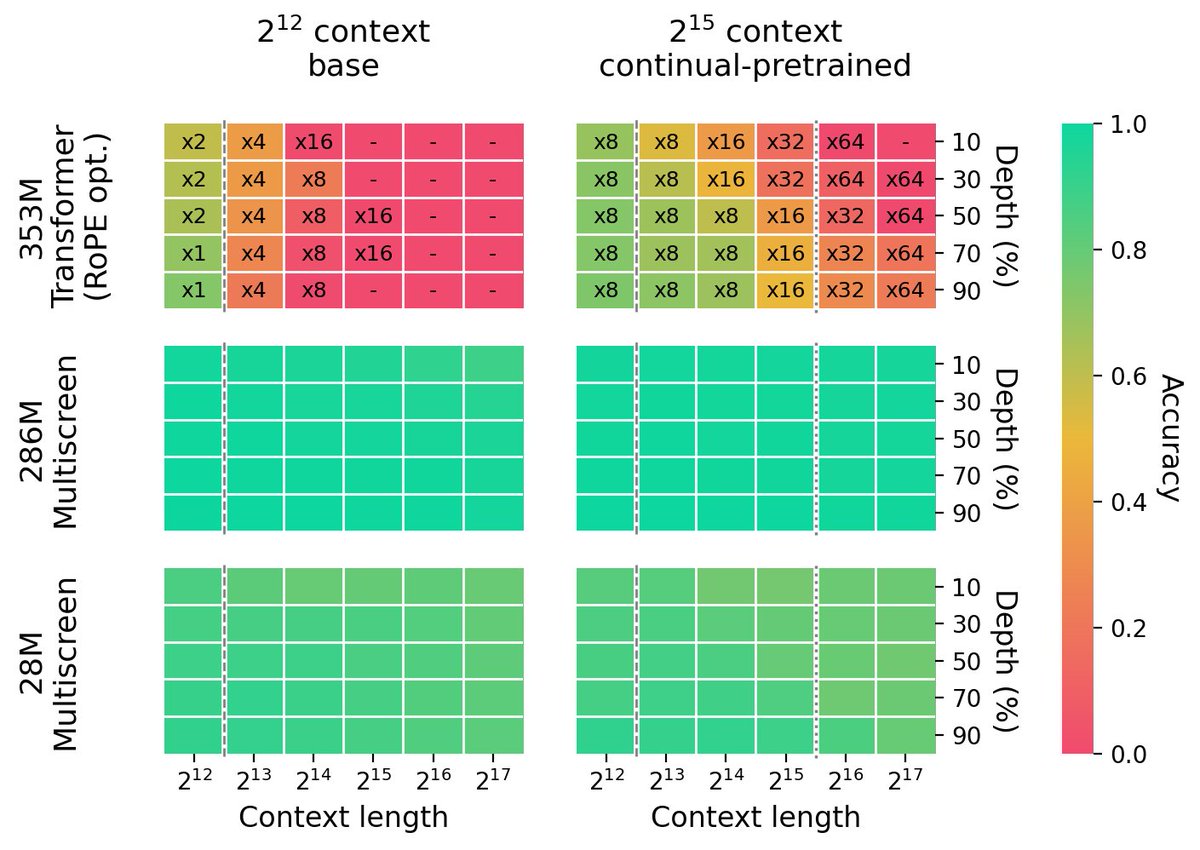
長文脈評価において、Multiscreenはパープレキシティにおいて強い性能を維持し、学習中に見た長さを遥かに超える文脈長でも、検索性能の劣化をほとんど示さない。AIや統計の分野では、これを外挿性(Extrapolation)が高いと表現するようだ。外挿性は学習した範囲外でも正しく振る舞える能力のことを指す。
条件によってはモデルパラメータが92%少なくても、一貫してTransformerベースラインを上回る。つまり情報の密度が非常に高いということである。100Kトークンのコンテキストを持つ次のトークン予測では、MultiscreenはTransformerベースラインに対して、推論レイテンシーを2.3-3.2倍削減する。
情報の集約ロジックを相対評価から、絶対選別にシフトさせた点が画期的で、メモリ、速度、精度のすべてにおいてブレイクスルーを達成している。大型のモデル開発だけでなく、エッジデバイスでのLLM実行においても有望なアーキテクチャである。
全員に配分する民主主義をやめて、一部の適格者だけ通す門番を導入したという例えがわかりやすい。
https://t.co/LuuaqJhqwg
🚨This week's top AI/ML research papers:
- HISA
- Embarrassingly Simple Self-Distillation Improves Code Generation
- FIPO
- SKILL0
- Reasoning over mathematical objects
- Screening Is Enough
- Path-Constrained Mixture-of-Experts
read this in thread mode for the best experience