Introducing Mixedbread Wholembed v3, our new SOTA retrieval model across all modalities and 100+ languages.
Wholembed v3 brings best-in-class search to text, audio, images, PDFs, videos...
You can now get the best retrieval performance on your data, no matter its format.
By now, everyone knows that single-vector embedding models are hugely limiting for modern workflows.
But they contain than you think: you can extract sparse Latent Terms from them.
And it turns out that BM25 is all you need to turn this vocabulary into a strong retriever.
Having language-adjacent properties means that tools designed for lexical approaches "just work".
BM25, always refusing to exit the scene, is strong here: applied over the Latent Terms extracted from nomic-embed-v1.5, it results in a near state-of-the-art sparse retriever.
New: grep for exact matching
grep → keyword / regex matching
search → fine-grained semantic retrieval
Works across uploaded content, including text, PDFs (OCR) and audio/video (transcription).
Give your agents both retrieval primitives to perform at their best.
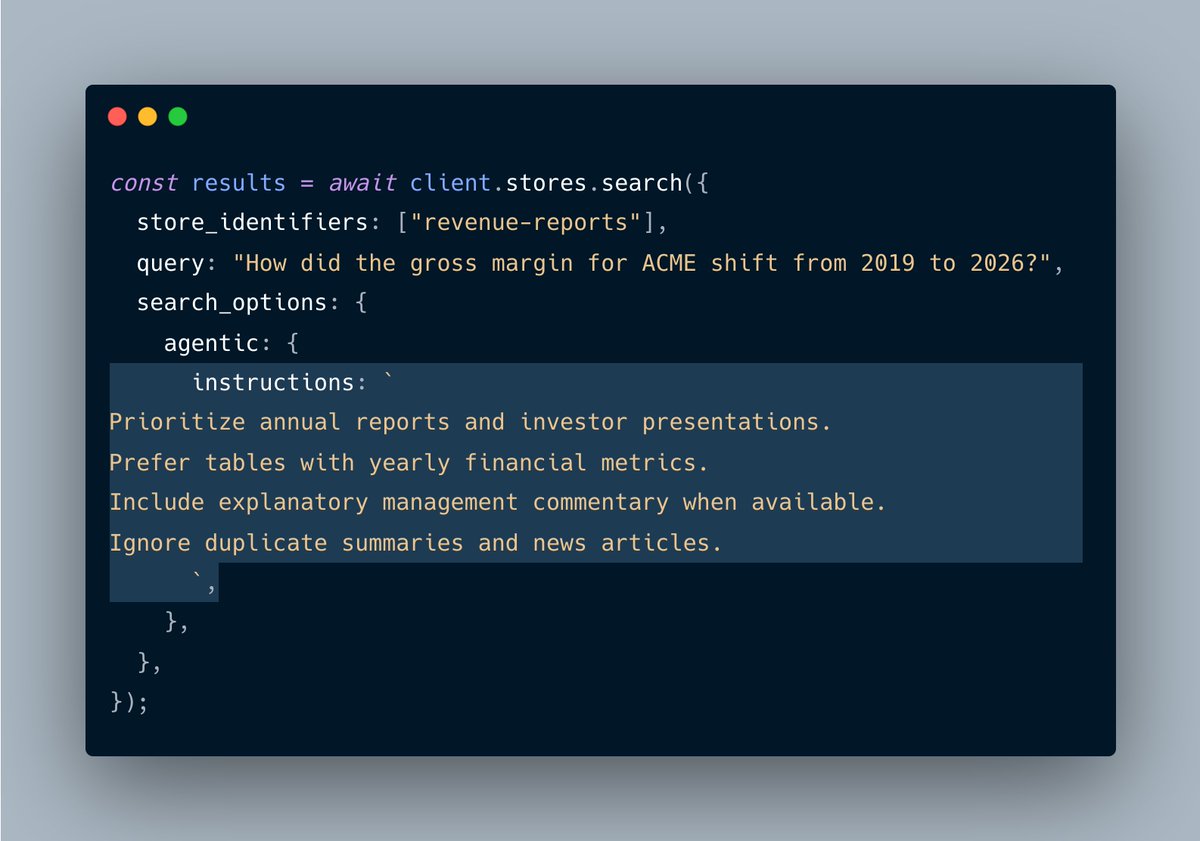
Feature: Native agentic search on Mixedbread
Search with auto-planning, exploration, and multi-hop reasoning across documents.
Built for:
- evidence discovery
- exhaustive search
- cross-document reasoning
→ Topped MADQA @snowflake with 93.4% accuracy across 18,000 PDF pages.
New: Traces for Mixedbread agentic search
See every search call an agent makes directly in the dashboard, and tune instructions for better retrieval quality.
Introducing mxbai-rerank-v3-listwise: reranking that goes beyond binary relevance.
It reads the whole candidate set, resolves conflicts, and ranks by directives like recency, source priority, and multi-step rules.
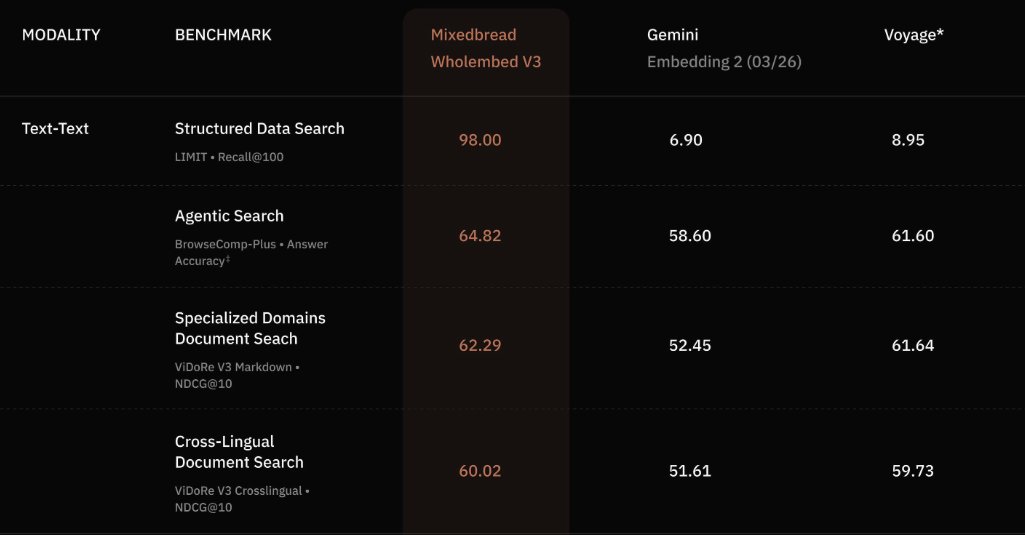
+11% NDCG@10 on average across multiple domains, modalities, and languages in runs with Wholembed v3.
Available today in preview in Mixedbread.
Mixedbread search's ultimate aim is to power all workflows, no matter their modality or language.
Try it for your own knowledge-intensive tasks today: https://t.co/FlUA03fS8b
You can read more about this in our blog post, where we present more detailed benchmark results and elaborate on the nature of the three benchmarks, and why we're very proud to be topping all three of them.
https://t.co/I0mjNnPPl9
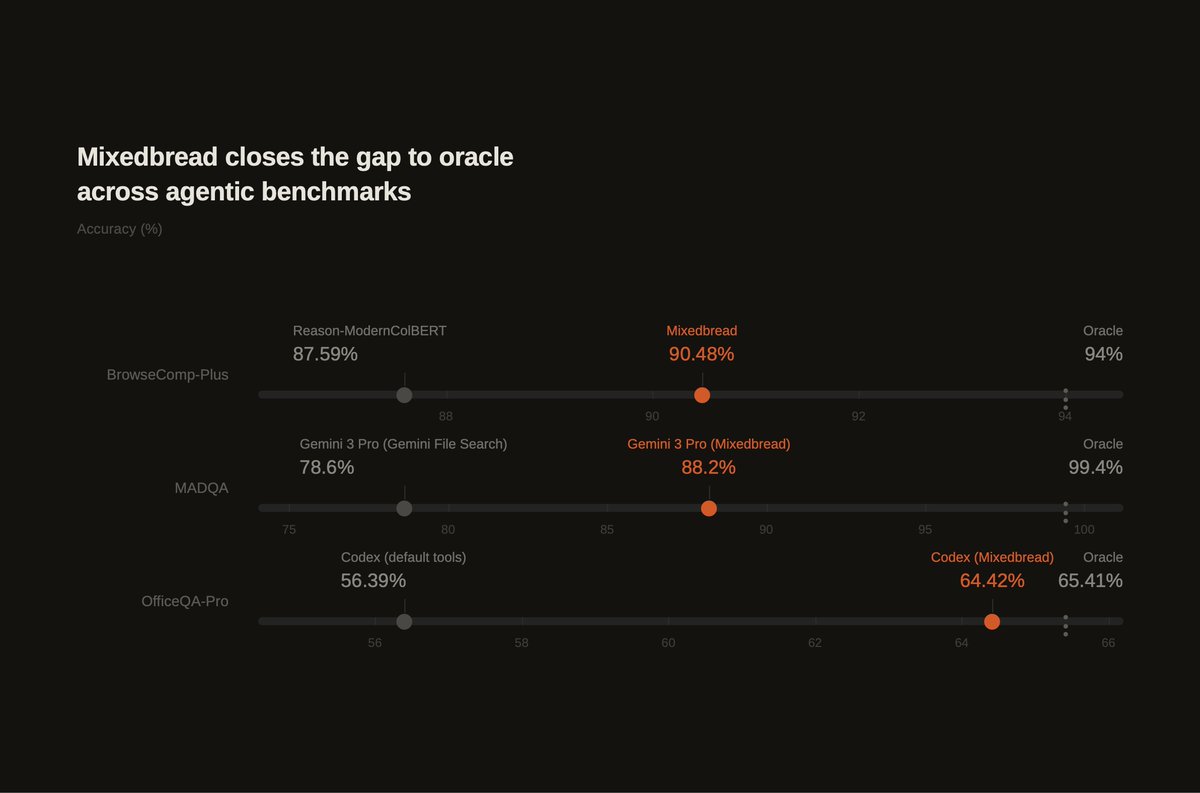
So what is the Oracle gap?
Optimising agentic systems is complicated. There are many individual components you need to get just right.
Retrieval is one of those components, and its impact is best measured by the Oracle gap: the difference between the performance of the same system between an imperfect retriever and perfect, fully-relevant results that would be provided by a so-called Oracle.
Agents are increasingly performing knowledge work: Deep Research, generating financial reports, reasoning across historical knowledgebases...
Many high-quality benchmarks now focus on evaluating such tasks, among which BrowseComp-Plus, @databricks's OfficeQA, or @Snowflake's MADQA, released just last week.
For Agentic tasks, Oracle-level performance is the maximum performance a system can achieve, assuming it is able to retrieve all relevant documents perfectly, every time.
We're proud to show that Mixedbread Search approaches the Oracle on multiple knowledge intensive benchmarks.
I've been eagerly awaiting this release from the @mixedbreadai folks. They're world-leading experts in late interaction retrieval.
And today they remind us that late interaction done well makes all your favorite embedding models look like they don't work.
Introducing Mixedbread Wholembed v3, our new SOTA retrieval model across all modalities and 100+ languages.
Wholembed v3 brings best-in-class search to text, audio, images, PDFs, videos...
You can now get the best retrieval performance on your data, no matter its format.
Wholembed v3 is available immediately through Mixedbread Search.
You can try it on our platform now, for free: New users get 2M free tokens to get started.
Startups can receive much more through our partnered accelerator programs with Vercel and TinyFish.
https://t.co/koj5FFazp2