📢 New paper in Statistics in Medicine!
We compare TMLE vs CV-TMLE across tough simulation settings:
✔️ Misspecification
✔️ Limited overlap
✔️ High-dimensional data
✔️ Super Learner + cross-fitting
Read it here: https://t.co/J1Fjx61eGM
@epi_twit@statstwitbot
We argue that dissemination of #TMLE relies on 5 key factors:
1. Software availability (https://t.co/Rfnk4B2LqX) 🧑💻
2. Accessibility of available material 📄🔓
3. Number of experts in #TMLE 🤓🤓🤓
4. Teaching 🏫🧑🎓
5. Collaborations 🧑🎓🤝🧑💼🤝🧑💻🤝🧑🔬🤝🧑⚕️ ...... 💡...... 🤯🤯🤯
@rabois@MaartenvSmeden For a confounder with low prevalence (e.g., 1%), if you only sample the other 99% of the population, then you should get an unbiased estimate?
So as you increase n from 50% to 99%, you decrease the bias of the confounder that you never captured in the first place…?
Hmmmm….
@kenkoonwong@epi_twit@statstwitbot @CausalInferBot Certainly! Below are two tutorials. The first offers a comparison of the common estimators (including TMLE). The second is a tutorial of TMLE for a binary treatment.
https://t.co/8R0lcRHjhD
and
https://t.co/iJVbJqhiSM
@WATZILEI@camaringe
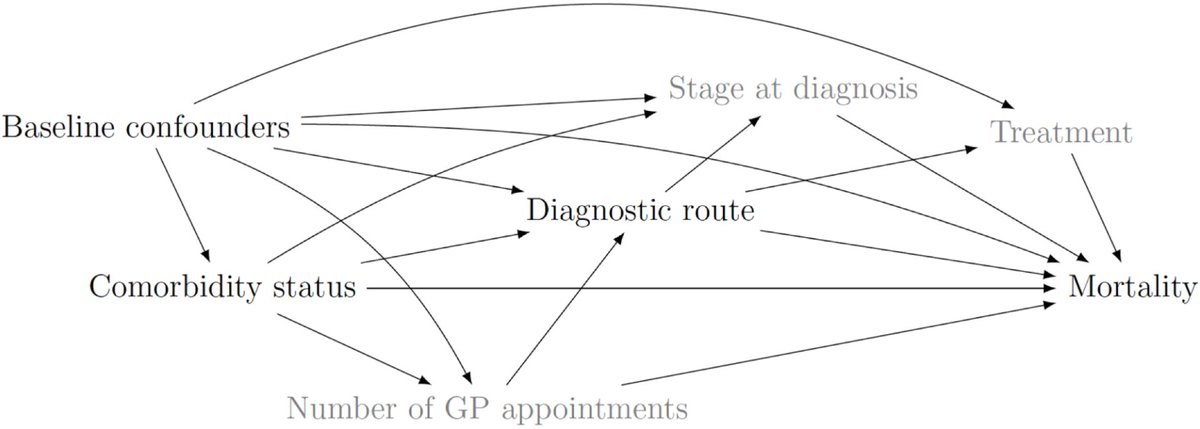
📢 New publication by @icon_lshtm researchers highlights importance of diagnostic route in survival of people with #lymphoma and comorbidities.
➡️https://t.co/DkPwjxBSIn
Further research is vital to ensure timely diagnoses to reduce the #inequalities in #cancer survival.
Save the dates! EuroCIM 2023 will take place in Oslo, April 19-21 (with short courses April 18). Keep an eye on https://t.co/FDUHFQEB19 for more information.