Fun stat: In the last month, people have created more than 1,000,000 native Android apps directly in @GoogleAIStudio!! Huge amount of progress here and so cool to see the breadth of what folks are building.
@icanvardar Every enterprise customer I meet, uses more than one LLM, quite often it's Gemini + Anthropic via Vertex AI. Not sure which world you live in. Gemini provides one of the best cost-performance specially for CX applications.
Introducing the Open Knowledge Format (OKF), an open specification that formalizes the LLM-wiki pattern into a portable, interoperable format.
AI is only as smart as the context we give it. As we build more advanced, agentic AI systems, they need accurate metadata and context to be useful. But in most organizations, that context is locked inside fragmented data catalogs, isolated wikis, scattered code comments, or the minds of senior engineers. Every time a new AI agent is built, teams are forced to solve the exact same context-assembly problem from scratch.
To solve this, we've announced OKF, a vendor-neutral, open specification that formalizes the "LLM-wiki pattern" into a portable, interoperable format. It provides a standardized way to represent the enterprise knowledge that modern AI systems rely on.
— Just markdown: readable in any editor, renderable on GitHub, indexable by any search tool
— Just files: shippable as a tarball, hostable in any git repo, mountable on any filesystem
— Just YAML frontmatter: for the small set of structured fields that need to be queryable: type, title, description, resource, tags, and timestamp
We’ve also shipped reference implementations to help you hit the ground running, including an enrichment agent for BigQuery, a static HTML visualizer, and live sample bundles on @github → https://t.co/ilhAMCrcTc
➕ Knowledge Catalog can now natively ingest OKF!
Stop reinventing data models and building bespoke integrations for every new AI tool. Here's more about how OKF works → https://t.co/FR4kJRsgEH
@svpino Try it with A2UI + AG-UI. It sounds complicated but it’s lot more easy to tell UI what to render using JSON spec (A2UI) which is transported via AG-UI.
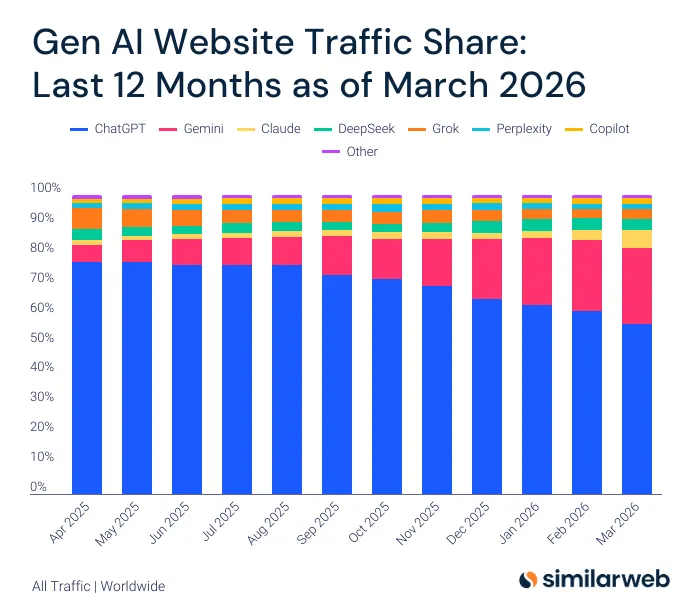
This guy is making a claim that GPUs are better than TPUs because Anthropic is losing share and Gemini Adoption is declining and OpenAI is "greater than" Gemini. And when asked about the source for his claims of TPU under performing .. Nil! People love hating Google for no reason
@Jespabe TPU benchmarks are all good but when you look at the actual model adoption among enterprises, OpenAI > Gemini and Anthropic is loosing ground as it gets compute constrained on inference side.
My leader @ImranKhanPTI sits in jail with his health in jeopardy. His imprisonment weighs on us every day. But I know him well enough to say this: He would want Pakistan's young people to keep building, to take on the world. Especially in AI. Especially now, without losing sight of the political struggle, which we will not abandon.
This thread is for them 🧵
—
Forced to stay away from my country gave me two benefits: More time and more passion. I chose not to waste either. This is a personal account:
It started with my need to transcribe my long speeches, some over thirty minutes, in mixed English and Urdu on YouTube (which gave a Hindi/Sanskrit transcript). The platforms available would do a bad job with the mix. So, I asked my coaches — ChatGPT, Claude & Gemini and I concluded to do it myself, locally, with Whisper’s large, medium & small models and other AI tools. This was completed in Dec ‘25
For the sake of open source and transparency, I am publishing it on GitHub.
https://t.co/yR9X32e819
In January ’26, I began building the Dr Arif Alvi AI Archive. An attempt to bring together everything I had said, written, read, and recorded across decades, and make it searchable, synthesizable, MINE.
I built it alone. No team. No budget. Just time, curiosity, and persistence.
It runs entirely on my enhanced laptop. My data never leaves it.
My AI agents ingest my writings/articles; thousands of books read and summarised; millions of words of archival material; my thousands of speeches on YouTube press conferences; thousands of talk show appearances since 2000 and clips on YouTube. All scraped from the net via APIs— indexed, and alive inside my local RAG (Retrieval Augmented Generation) system that answers back.
My 50,000+ tweets are searchable faster than X's own tools. Not just by keyword but semantically.
None of it leaves my computer or enters the public domain, remains private.
—
The local LLMs answer questions, draft research briefs, synthesize across all data. When I need to reach beyond my own archive, they augment from public LLMs — ChatGPT, Claude, DeepSeek, others.
I use the archive every day, updating it regularly. It has changed how I think and work.
—
Following are the layers of the stack — what I built is one-of-one. But what I built it from is available to every-one:
▶️ Ollama / Llama / Phi / Qwen — local LLMs running entirely on-device
▶️ Whisper — bilingual English-Urdu speech transcription
▶️ ChromaDB — vector memory across 70,000+ chunks
▶️ Sentence Transformers — semantic search across tweets, speeches, and archives
▶️ Streamlit — dashboard with dual modes: semantic search and AI research
▶️ Six LLM interfaces (ChatGPT, Claude, DeepSeek, Gemini, Perplexity, Copilot) for python scripts and for augmentation of local output
▶️ OpenClaw and GitHub — for code management
▶️VS Code — for scripts and code writing
None of them are mine. The COMPOSITION is mine.
—
I should tell you what it took to get here.
I started learning Python basics from online courses. I am not a programmer, but I reviewed and iterated over a million lines of scripts —learning, correcting, improving, understanding—just enough to keep going.
I had launched Pakistan's Presidential Initiative on Artificial Intelligence in 2019. I thought I understood AI but I took advanced courses anyway. There is always more to learn, and humility about ignorance is not a weakness. It is the only honest starting point.
—
There are tens of thousands of students, researchers, operators, lawyers, and doctors across Pakistan and the world, quietly trying to dabble in AI right now.
To them I would say: software writing is mostly done by machines today. You do not need to become a programmer. You need to understand enough to read, direct, correct and employ tools — like a symphony conductor, with an AI baton.
More than anything, pick a project. Something real, something yours.🔑 Scripts fill the architecture. Concrete fills the blueprint.
GET TO WORK
And do not move slowly. AI tools and agentic systems are changing every single day. What was remarkable yesterday is ordinary today. Sometimes the gap is hours, not months.
The people who stay ahead are not waiting to fully understand it before they begin.
THEY ARE ALREADY BUILDING.
—
Pakistan cannot afford to fall behind in this.
Not out of nostalgia for what Pakistan was, but out of economic and strategic urgency for what it must become — because our talented, hungry people can build anything when given the tools and the leadership.
This is for them.
START
As a Googler I can tell it does not seem correct. I simply can't live without AI. Most of my workflows use AI extensively from research to plan to build and all the way to deployment.
I was chatting with my buddy at Google, who's been a tech director there for about 20 years, about their AI adoption. Craziest convo I've had all year.
The TL;DR is that Google engineering appears to have the same AI adoption footprint as John Deere, the tractor company. Most of the industry has the same internal adoption curve: 20% agentic power users, 20% outright refusers, 60% still using Cursor or equivalent chat tool. It turns out Google has this curve too.
But why is Google so... average? How is it that a handful of companies are taking off like a spaceship, and the rest, including Google, are mired in inaction?
My buddy's observation was key here: There has been an industry-wide hiring freeze for 18+ months, during which time nobody has been moving jobs. So there are no clued-in people coming in from the outside to tell Google how far behind they are, how utterly mediocre they have become as an eng org.
He says the problem is that they can't use Claude Code because it's the enemy, and Gemini has never been good enough to capture people's workflows like Claude has, so basically agentic coding just never really took off inside Google. They're all just plodding along, completely oblivious to what's happening out there right now.
Not only is Google not able to do anything about it, they don't seem to be aware of the problem at all. I'm having major flashbacks to fifty years ago as a kid at the La Brea Tar Pits, asking, "why can't they just climb out?"
My Google friend and I had this conversation over a month ago. I didn't share it because I wanted to look around a bit, and see if it's really as bad as all that. I've been talking to people from dozens of companies since then. And yeah. It's as bad as all that.
Google is about average. Some companies at the bottom have near-zero AI adoption and can't even get budget for AI. They may have moats and high walls, but the horde is coming for them all the same.
And then there are a few companies I've met recently who are *amazingly* leaned in to AI adoption. One category-leader company just cancelled IntelliJ for a thousand engineers. That's an incredibly bold move, one of many they're making towards agentic adoption. In my opinion, that company is setting themselves up for a _huge_ W.
As for the rest, well, it's the Great Siloing. Everyone's flying blind. With nobody moving companies, no company knows where they stand on the AI adoption curve. Nobody knows how they're doing compared to everyone else.
Half of them just check a box: "We enabled {Copilot/Cursor} for everyone!" Cue smug celebrations. They think this is like getting SOC2 compliance, just a thing they turn on and now it's "solved." And they don't realize that they've done effectively nothing at all.
All because of a hiring freeze.
We've signed an agreement with Google and Broadcom for multiple gigawatts of next-generation TPU capacity, coming online starting in 2027, to train and serve frontier Claude models.
Today, I had the honour of speaking to the 47 countries that comprise the @UN#HumanRightsCouncil urging the immediate release of my father @imrankhanpti and all #Pakistan’s #politicalprisoners. Along with this, I want to be very clear. Like my father, I fully support maintaining GSP+ as the people of #Pakistan should never be punished for the actions of its leaders. But the Pakistani regime must also fully comply with the 27 treaties it committed to follow to obtain this benefit, including the International Covenant on Civil and Political Rights and Convention Against Torture. @UN@ptiofficial #HumanRights #ImranKhanUnlawfullyDetained
Introducing the all new vibe coding experience in @GoogleAIStudio, feating:
- One click database support
- Sign in with Google support
- A new coding agent powered by Antigravity
- Multiplayer + backend app support
and so much more coming soon!
https://t.co/G0m9hRnoIS
My sons Sulaiman & @kasim_khan_1999 applied for visas in January (again… ) to allow them to visit their father @ImranKhanPTI in Pakistan. The Pakistan consulate states that online visa processing normally takes 7–10 working days. It has now been 60 days. This despite the public promise that they could safely travel there to see their father after 4 years, made by both Defence Minister @khawajaMAsif to @mehdirhasan & PM spokesperson @mosharrafzaidi to @SkyYaldaHakim
Meanwhile, they are not allowed to speak to him on the phone, nor send him a letter. They haven’t seen him since 2022 after he was shot in an assassination attempt.
This is an appeal directly to Pakisan’s PM @CMShehbaz to please allow Imran Khan’s two sons to see their father asap, particularly since, by all accounts, his health is in decline.