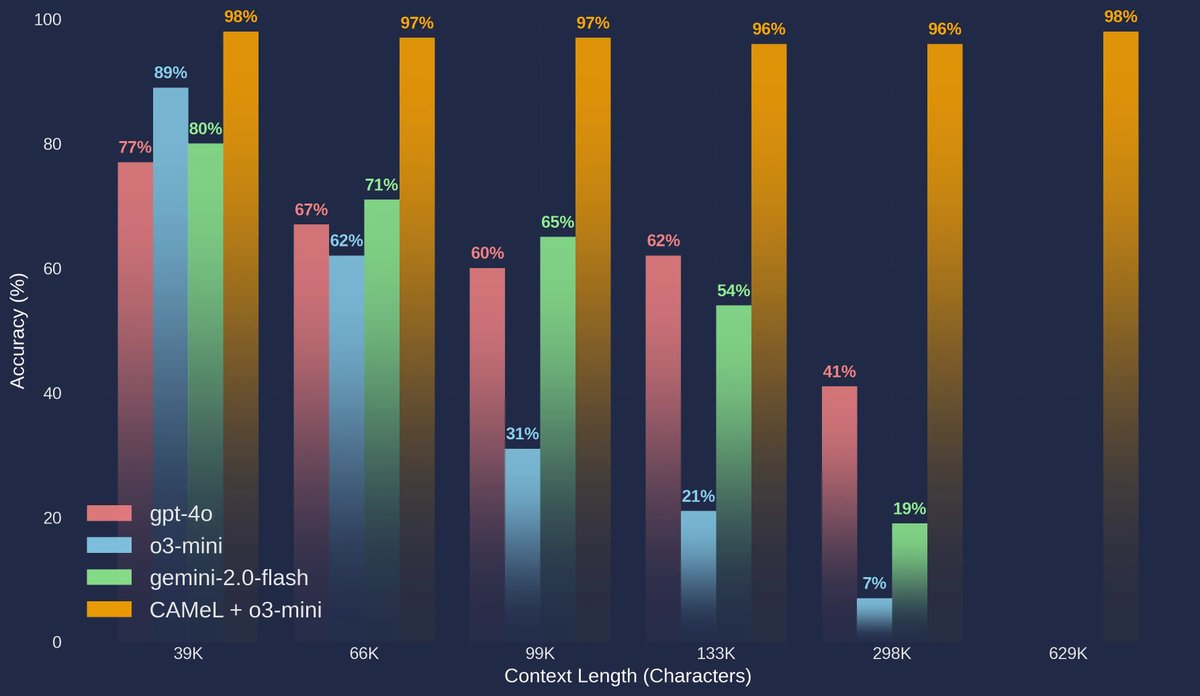
LLMs like GPT4o often struggle with complex queries on large documents. But why?
Our new benchmark spotlights a key deficiency—comprehension—that worsens as context grows.
The good news: We show how our custom LLM CAMeL can augment a frontier model, vastly improving comprehension.
Reach out if you have Q&A tasks that are not well served by current long context and RAG systems. Also stay tuned for more results!
https://t.co/KUzRlTgr6Q
A TensorWave Report: AMD’s MI300X Outperforms NVIDIA’s H100 for LLM Inference
There has been much anticipation around AMD’s flagship MI300X accelerator. With unmatched raw specs, the pressing question remains: Can it outperform NVIDIA’s Hopper architecture in real-world AI workloads? We have some exciting early results to share.
Read the full article here: https://t.co/tD2y7zwGb8
Watch 32 @AMD MI210 cards 🔥 on Tensorwave’s GPU cloud.
Summarizing 82 articles / sec using MK1 Flywheel inference engine, hitting max TDP!!!
Can’t wait for 80 MI300x cards per node. What will you run?
Learn how to get the most from your GPUs at @mkoneai and @tensorwave
Run MK1 Flywheel on @modal_labs for the fastest LLM inference 🚀
Experience faster responses and lower costs with just a few lines of code.
Get started with free credits and instant GPU access.
Learn more on our blog: https://t.co/9K2wI6eGLe
Launching Flywheel, MK1's enterprise LLM inference engine. Now out of closed beta and ready to make AI go brrr!
You can try MK1 Flywheel now on AWS SageMaker or reach out if you're ready to deploy at scale.
Learn more about our progress on our blog post: https://t.co/W4pNVsYHcD