JoyAI-Echo is now on ModelScope. Minute-level multi-shot audio-video generation from Joy Future Academy, JD, with paired cross-modal memory for story-level consistency.
🤖 https://t.co/Ae74mOPSzk
● Long video: 5 min coherent stories from one prompt JSON
● Speed: 7.5x faster than the original multi-step pipeline with DMD-distilled few-step inference
● Large-scale evaluation: 3,000 generated shots across 100 benchmark stories
● Long-video human eval:preferred over HappyOyster on long-video visual aesthetics 63.6%, audio quality 81.7%, prompt following 80.6%, IP consistency 59.4%
● Short video comparison: preferred over Wan 2.6 on visual aesthetics 58.8% and prompt following 33.8%
Under the LTX-2 Community License Agreement,non-commercial use only.
One image, controllable 3D output. TripoSplat from @tripoai a lightweight image-to-3D Gaussian model for fast, controllable 3D asset generation.
🔗https://t.co/EkeN1JlWJ9
✅ Adjustable Gaussian count up to 262,144
✅ Two core files, ~2,000 LOC total, for lightweight implementation.
✅ Near-zero dependencies, no transformers or diffusers required.
✅ Official ComfyUI support
Released under the MIT License for flexible commercial and non-commercial use.
For image-to-3D and Gaussian Splatting workflows, TripoSplat offers a practical way to reduce setup cost while keeping quality and rendering cost controllable.
📚Paper:https://t.co/Vgzb4nrzI8
Meet Cosmos3-Nano✨ Before Physical AI acts, it needs to imagine. NVIDIA Cosmos3-Nano makes that possible. 🧩
🧷https://t.co/ZxMr1g9a7y
-16B, split for reasoning + generation. Combines an 8B reasoner and an 8B generator to connect world understanding with world generation.
-Generate simulation-ready video. Creates physics-aware video worlds for synthetic data, edge-case testing, and model evaluation.
-Built for real-world agents. Designed for robotics, autonomous driving, smart spaces, and other systems that need to perceive, predict, and act.
-From multimodal input to action insight. Takes text, image, video, and action inputs, and outputs physics-aware video, future-scene simulations, and action insights.
Open for commercial and non-commercial use. Released under OpenMDW-1.1, ready for developers building AI that needs to understand the real world
Singapore builders, we're hosting a ModelScope & Qwen meetup on June 10 🇸🇬
We'll be talking about developers' commercial pathways with ModelScope, what people are actually building with Qwen, hear from the community, and have an open mic session for anyone who wants to share projects, ideas, feedback, or just hang out with fellow AI builders.
If you're around, come say hi 👋 https://t.co/6LppkusZeQ
Congrats to @PaddlePaddle on the open release of PaddleOCR-VL-1.6! 🚀
An upgraded compact document parsing model hitting a 96.33% score on OmniDocBench v1.6, outperforming top-tier VLMs.🤖
https://t.co/xovFqwPeDW
📊 Benchmark Accuracy: Achieves 96.33% on OmniDocBench v1.6, while setting new performance records on OmniDocBench v1.5 and Real5-OmniDocBench for text, formula, and table recognition.
⚡ Upgraded Capabilities: Built with a region-aware data optimization framework. Brings significant precision leaps in tables, charts, seals, Chinese ancient documents, and rare characters.
🧠 Staged Optimization: Adopts a progressive post-training recipe based on curated data selection and reinforcement learning to enhance supervision signals.
🔄 Seamless Migration: Model architecture is fully compatible with PaddleOCR-VL-1.5 for a zero-cost plug-and-play replacement.
Say hello to OmniNFT, an RL fine-tuning framework that enables joint audio and video generation with better audio-visual synchronization. Built on LTX-2/2.3, with pretrained LoRA weights available.🚀
Collapsing multi-modal rewards into a single advantage causes conflicting gradients across modalities. OmniNFT fixes this with three targeted designs:
🎬 Modality-wise Advantage Routing: independent per-reward advantages for video, audio, and sync, each routed to its own branch
🔧 Layer-wise Gradient Surgery: partial stop-gradient on audio layers in shallow transformer blocks, preventing video gradients from leaking into audio
🎯 Region-wise Loss Reweighting: uses cross-attention maps to focus optimization on sound-emitting regions, no external detection needed
📄 https://t.co/UpkQk2gC3O
💻 https://t.co/8VTOBfNGFS
🤖 https://t.co/juWwnnAmKS
TransitLM is now live on ModelScope, a dataset for training and evaluating LLMs on public transit route planning in Chinese cities. 📊
13M+ records across Beijing, Shanghai, Shenzhen, and Chengdu. 120,845 stations, 13,666 lines. Three tasks: optimal route, preference-aware planning, multi-route comparison.
📄 https://t.co/8gZZeutqDd
🗂️ https://t.co/Ici8bZUb3N
- 13.9M CPT records + 90K SFT training samples + 30K evaluation samples.
- Dual test set design: anonymized set for models trained on this corpus, real-world benchmark for general-purpose LLMs. Both 30K samples, directly comparable.
- Each sample includes coordinates, station sequences, transfer structure, line info, travel time, distance, and fare.
🔥@KwaiKeye 's Keye-VL-2.0-30B-A3B is now officially live on ModelScope! A major milestone that brings DSA (DeepSeek Sparse Attention) into multimodal AI. 🎬🤖
By coupling sparse attention with advanced feature aggregation, Keye 2.0 unlocks a 256k context window, allowing seamless processing of hour-long videos with zero context degradation. 📈 🔗 Get the weights: https://t.co/ScMIfM6ExY
🌟 Core Technical Highlights:
• 🧠 MoE Performance, Flash Cost: Outperforms 200B+ open models on LongVideoBench (74.10) while slashing prefill costs by 50%.
• ⏱️ Frame-Level Precision: Captures complex causal chains and timestamps in long vlogs, handicraft tutorials, and gaming clips.
• 🚀 Anti-Decay Mastery: On VideoMME V2, expanding input from 64 to 512 frames actually boosts accuracy from 35.34% to 42.44%.
Introducing VINS-120K, a large-scale dataset for researchers building ultra-high-resolution image editing models. 🚀
📄 https://t.co/n8W1g3uy9r
🗂️ https://t.co/5NCsI6WTfv
120K editing triplets (instruction + input + edited image), all at 4K+ resolution. Built from real-world ultra-high-resolution videos and high-quality open-source editing data, filtered for visual quality, instruction alignment, and aesthetic fidelity.
Covers 13 editing types across local editing, global editing, camera movement, and personalized generation.
@xiaofeifeiovo@KwaiKeye Basically, this is one example run on a sample clip. You are welcomed to grab the weights and try your own videos. To avoid any misunderstanding, I've replaced the clip.🤝
Imagine controlling Black Myth: Wukong or Genshin Impact using an open-source world model. 🎮🌍
@auyeying and @ZizhaoT just dropped SCOPE, a native interactive world model for FPS games! Built on Wan2.2-TI2V-5B and trained on 69K clips, it delivers 81 frames at 20 FPS (832x480) with impressive zero-shot capabilities. 📈
🔗 Get the weights & paper on ModelScope: https://t.co/Atq0LtJ5c8
🌟 Core Features:
• 🕹️ Hybrid Action Space: Unifies 4D dual-joystick continuous input and 6 discrete binary buttons into one framework.
• 🎯 Dense Per-Frame Conditioning: Handles multi-action composition like moving, aiming, and firing simultaneously at every single frame.
• 🚀 Zero-Shot Generalization: Zero fine-tuning needed for unseen titles like It Takes Two.
• 🖼️ Decoupled Generation: Separates weapon recoil and HUD elements from the core world environment without needing any segmentation labels.
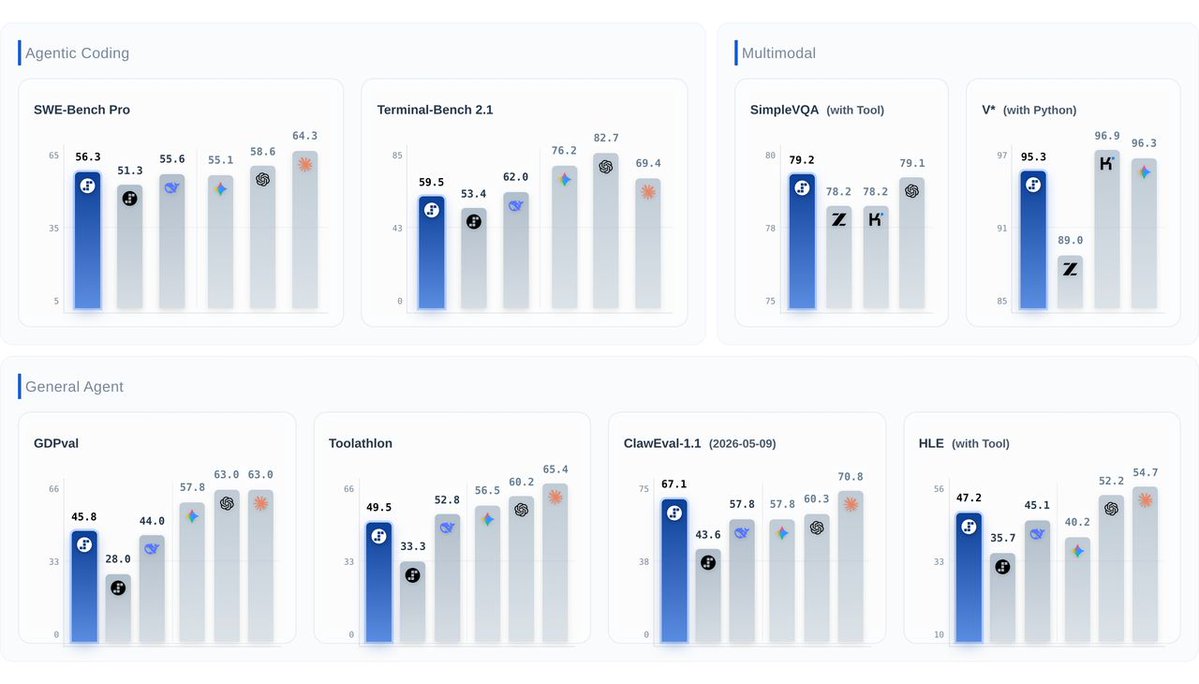
Thrilled to welcome Step 3.7 Flash landing on ModelScope, a 198B sparse MoE VLM from @StepFun_ai 🔥🤖 https://t.co/wRRqeYa34Z
198B total, 11B active per token, up to 400 tok/s. 256K context. Three reasoning levels (low/medium/high) to balance speed, cost, and depth.
🥇 #1 on ClawEval-1.1 (67.1), leading Kimi K2.6 by 9.3pts
🥈 #2 on SWE-bench Pro (56.3)
🥇 #1 on SimpleVQA Search (79.2)
🖼️ Multimodal: 196B language backbone + 1.8B vision encoder. Parses dense UI, charts, and financial reports natively.
📄 Apache 2.0.
vLLM / SGLang / llama.cpp / Transformers supported. Hermes Agent / OpenClaw / Kilo Code compatible. Runs locally on Mac Studio or DGX Station with 128GB+ memory.
Introducing LocateAnything-3B, a vision-language model for fast, precise visual grounding from NVIDIA. Up to 2.5x throughput improvement over prior methods. 🤖 https://t.co/28Wvz4Q7lg
Trained on 12M images, 138M+ queries, 785M bounding boxes across natural scenes, robotics, autonomous driving, GUI, and document understanding.
🎯 Object detection, phrase grounding, GUI element locating, scene text detection, document layout, pointing — all in one model.
Already integrated into NVIDIA Nemotron Nano Omni for production-grade VLM grounding.
📄 Non-commercial research use only.
18 frontier models evaluated. Key findings:
🥇 GPT Image 2 leads overall (64.7), nearly 5pts ahead of second place
🖼️ Qwen Image 2.0 Pro ranks 5th overall
⚠️ 4 facets remain systemic ceilings across all models: Physical Logic, Anatomical Fidelity, Animals, Contact Interaction — best scores below 44
📊 Creative Generation has 11x the variance of Quality — the most discriminative dimension, and the one most existing benchmarks miss
1,000 expert-crafted bilingual prompts (500 long + 500 short, Chinese/English), each covering 4+ fine-grained facets across multiple pillars.
Introducing Q-Judger and Qwen-Image-Bench, an automated T2I evaluation suite from Qwen team. Apache 2.0. 🤖 https://t.co/hv3R6iU9UX
Q-Judger is built on Qwen3.6-27B with thinking mode. Input prompt + image, get structured JSON scores across 5 dimensions: Quality, Aesthetics, Alignment, Real-world Fidelity, Creative Generation. Spearman ρ = 0.92 vs human expert rankings. Trained on 130K+ bilingual pairs supervised by 80 professional annotators from art academies.